Taming the Noise: Advanced Strategies for Robust DBTL Cycles in Biomedical Research
This article provides a comprehensive guide for researchers and drug development professionals on managing experimental noise in Design-Build-Test-Learn (DBTL) cycles.
Taming the Noise: Advanced Strategies for Robust DBTL Cycles in Biomedical Research
Abstract
This article provides a comprehensive guide for researchers and drug development professionals on managing experimental noise in Design-Build-Test-Learn (DBTL) cycles. It explores the fundamental sources and impacts of noise in high-throughput biological data, presents advanced machine learning methodologies like Bayesian optimization and heteroscedastic modeling for robust data analysis, and offers practical troubleshooting and optimization strategies for automated platforms. Through validation case studies from metabolic engineering and protein expression, it demonstrates how these approaches lead to more reliable, reproducible, and efficient strain and therapy development, ultimately accelerating the translation of biomedical research.
Understanding Experimental Noise: The Fundamental Challenge in Biological DBTL Cycles
Troubleshooting Guide: FAQs on Experimental Noise
Q1: My TR-FRET assay has no assay window. What is the most common cause?
The most common reason for a complete lack of an assay window is that the instrument was not set up properly. Additionally, the single most common reason for TR-FRET assay failure is the use of incorrect emission filters. Unlike other fluorescence assays, TR-FRET requires specific emission filters recommended for your instrument. The excitation filter has a greater impact on the assay window itself. You should always test your microplate reader’s TR-FRET setup using reagents you have on hand before beginning experimental work [1].
Q2: How can I determine if a problem in my single-cell RNA-seq experiment is due to technical noise or genuine biological variation?
Technical noise in scRNA-seq, stemming from stochastic RNA loss during cell lysis, reverse transcription, and amplification, can be distinguished from biological noise by using a generative statistical model alongside external RNA spike-ins. These spike-in molecules are added in the same quantity to each cell's lysate and provide an empirical model of the technical noise across the dynamic range of gene expression. This approach allows you to decompose the total observed variance into its technical and biological components, helping to confirm whether observed variability, such as stochastic allele-specific expression, is genuine or a technical artefact [2].
Q3: My experimental results show high variability between replicates. How can I assess if my assay is still robust enough for screening?
Assay window size alone is not a good measure of robustness. The Z'-factor is a key metric that takes into account both the assay window (the difference between the maximum and minimum signals) and the variability (standard deviation) of the data. It is calculated as: ( Z' = 1 - \frac{3(σ{max} + σ{min})}{|μ{max} - μ{min}|} ) where ( σ ) is the standard deviation and ( μ ) is the mean of the high (max) and low (min) controls. A Z'-factor > 0.5 is generally considered suitable for screening. A large assay window with a lot of noise can have a lower Z'-factor than an assay with a small window but little noise [1].
Q4: What is a structured approach to troubleshooting general lab instrument issues?
A logical, funnel-based approach is effective:
- Start Broadly: Determine if the issue is method-related, mechanical, or operational.
- Ask Preliminary Questions: What was the last action before the issue? How frequent is the problem? Check instrument logbooks and software logs.
- Confirm Parameters: Verify that the method parameters match what is supposed to be run, as they can be accidentally changed.
- Isolate the Issue: Use "half-splitting" on modular instruments to isolate the problem to a specific component (e.g., chromatography side vs. mass spectrometer side).
- Repair Systematically: Start with easy fixes like replacing consumables. Document every step and resist applying multiple fixes at once [3].
Quantifying and Managing Noise in the DBTL Cycle
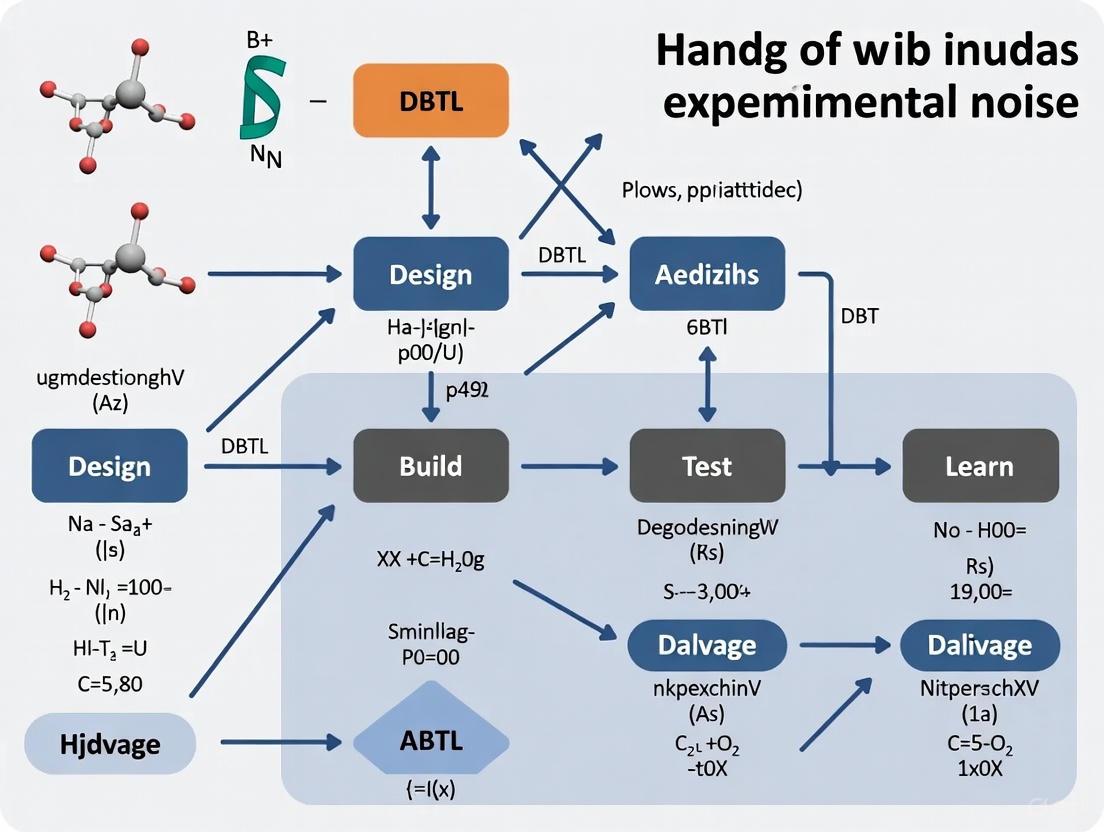
The Design-Build-Test-Learn (DBTL) cycle is a core iterative process in metabolic engineering and biosystems design. Managing noise is critical for efficient learning and design in subsequent cycles. Fully automated, algorithm-driven platforms are now being used to close the DBTL loop, using machine learning to distinguish robust signals from noisy data and directly inform the next round of experiments [4] [5].
Table 1: Key Metrics for Quantifying Experimental Noise and Data Quality
| Metric | Definition | Application | Interpretation |
|---|---|---|---|
| Z'-factor [1] | A statistical measure that assesses the robustness of an assay by considering both the dynamic range and the data variation. | High-throughput screening assays (e.g., TR-FRET, fluorescence-based assays). | > 0.5: Excellent assay for screening.0.5 to 0: A marginal to poor assay.< 0: The signals of the high and low controls overlap. |
| Biological Variance [2] [6] | The component of total observed variance in gene expression across cells that is attributable to genuine biological stochasticity (e.g., transcriptional bursting) rather than technical artifacts. | Single-cell RNA-sequencing (scRNA-seq) data analysis. | Helps distinguish true stochastic allele-specific expression or cell-to-cell heterogeneity from noise introduced by low capture efficiency or amplification bias. |
| Transcriptional Burst Frequency and Size [6] | Kinetic parameters describing stochastic gene expression; frequency is how often a gene switches to an "ON" state, and size is the number of transcripts produced per burst. | Analysis of single-cell expression data (e.g., from smFISH or scRNA-seq) to understand the source of phenotypic variability. | Genomic features (e.g., TATA-box, CpG islands) can modulate these parameters, influencing the level of transcriptional variability. |
Experimental Protocol: Decomposing Noise in Single-Cell RNA-Seq
This protocol outlines the use of external RNA spike-ins to quantify technical noise [2].
1. Principle: External RNA Control Consortium (ERCC) spike-in molecules are added in known, identical quantities to the lysis buffer of every single cell. This provides an internal standard that experiences the same technical noise (e.g., stochastic dropout, amplification bias) as the endogenous transcripts but has no biological variation. The difference between the expected and observed spike-in counts is used to model the technical noise.
2. Reagents and Equipment:
- Single-cell suspension
- ERCC spike-in mix
- scRNA-seq library preparation kit
- scRNA-seq platform (e.g., microfluidic or plate-based)
- High-throughput sequencer
3. Procedure:
- Spike-in Addition: Add a precise volume of ERCC spike-in mix to the cell lysis buffer immediately after cell lysis.
- Library Preparation and Sequencing: Proceed with standard scRNA-seq library preparation, including reverse transcription, amplification (using Unique Molecular Identifiers, UMIs), and sequencing.
- Data Processing: Align sequencing reads to a combined reference genome (endogenous genes + ERCC sequences) and quantify transcript counts.
- Generative Modeling: Use a probabilistic model (e.g., as described in [2]) to:
- Estimate cell-specific technical parameters (e.g., capture efficiency) from the spike-in data.
- Fit the mean-variance relationship for technical noise across the expression level dynamic range.
- Calculate the technical variance for each endogenous gene.
- Estimate biological variance as: Biological Variance = Total Observed Variance - Technical Variance.
4. Data Analysis:
- The model outputs an estimate of the proportion of variance for each gene that is due to biological noise versus technical noise.
- This allows for the correct identification of genuine biological phenomena, such as stochastic allele-specific expression, by ensuring that apparent monoallelic expression is not merely a consequence of technical dropout for lowly expressed genes [2].
Diagram: Integrating Noise Analysis into the DBTL Cycle
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Reagents and Materials for Noise Control Experiments
| Item | Function in Noise Control | Example Application |
|---|---|---|
| External RNA Spike-ins (ERCC) [2] | Provides an internal standard to model technical noise across the expression dynamic range. Added in known quantities to each sample. | Quantifying technical noise and decomposing variance in single-cell RNA-sequencing experiments. |
| LanthaScreen TR-FRET Assay Reagents [1] | Terbium (Tb) or Europium (Eu)-labeled donors and acceptors for time-resolved FRET assays. The donor signal serves as an internal reference to normalize for pipetting variance and reagent lot-to-lot variability. | High-throughput screening assays in drug discovery (e.g., kinase activity assays). |
| Unique Molecular Identifiers (UMIs) [2] | Short random nucleotide sequences added to each mRNA molecule during reverse transcription. They allow for the correction of amplification bias by collapsing PCR duplicates, reducing technical noise in sequencing counts. | Any sequencing-based protocol where amplification is involved (e.g., scRNA-seq, bulk RNA-seq). |
| Robotic Automation Platform [4] [5] | Executes repetitive "Test" steps in the DBTL cycle with high precision, minimizing human-introduced operational variability and enabling high-throughput data generation for machine learning. | Automated cultivation, induction, and measurement in metabolic engineering and biosystems design optimization. |
Frequently Asked Questions (FAQs)
FAQ 1: What are the primary sources of data variability in a DBTL cycle? Data variability in DBTL cycles arises from multiple sources, which can be broadly categorized as follows:
- Biological Noise: Inherent stochasticity in biological systems, such as differences in cell physiology, metabolic burden, and colony-to-colony variability [7] [4].
- Experimental Noise: Variations introduced during manual laboratory workflows, including pipetting inaccuracies and inconsistencies in culturing conditions [4].
- Analytical Noise: Limitations in the precision of analytical instruments and methods. For example, standard bioanalytical methods can have a precision CV% of 15-20%, which directly contributes to the scatter of final results [8].
- Process and Material Variability: Fluctuations in raw materials, such as natural excipients in formulations, where factors like particle size and moisture content can vary even within pharmacopeia specifications [9].
FAQ 2: How does data variability impact the machine learning (ML) phase of the DBTL cycle? Data variability, or noise, presents a fundamental challenge to machine learning.
- Impaired Model Performance: Noisy data can lead to inaccurate predictive models that fail to identify the true optimal designs. ML requires large, reproducible datasets to function effectively, and variability can drastically slow down the learning process [10] [4].
- Exploration vs. Exploitation Dilemma: Variability makes it difficult for algorithms to distinguish between a genuinely high-performing strain and one that measured high due to random chance. This confusion disrupts the balance between exploring new designs and exploiting promising ones [5].
FAQ 3: What practical steps can I take to mitigate variability in my experiments?
- Automate Workflows: Utilizing robotic platforms for tasks like cultivation and liquid handling significantly increases throughput and data reproducibility, reducing human-introduced errors [4].
- Leverage High-Throughput Data: Generate large, multivariate datasets using plate readers and RNA-sequencing to capture system behavior more comprehensively, making ML models more robust to noise [11] [4].
- Implement Robust Design Principles: Apply Quality by Design (QbD) and Design of Experiment (DoE) principles to understand and control critical material attributes and process parameters early in development [9].
Troubleshooting Guides
Problem: High variability in protein expression yields.
- Potential Cause: Colony-to-colony variation or metabolic burden on the host organism [7].
- Solution:
- Design: Hypothesize that different colonies from the same transformation plate may have varying tolerance to expression.
- Build: Inoculate multiple flasks with different colonies, rather than relying on a single colony.
- Test: Measure growth curves (OD600) and protein yield for each flask.
- Learn: Select and scale up the healthiest colonies with the most consistent expression for subsequent cycles [7].
Problem: High variability in pharmacokinetic (PK) concentration-time data, especially during absorption and distribution phases.
- Potential Cause: The combined effect of physiological variability and analytical method precision [8].
- Solution: A data transformation method can be applied to reduce standard deviation without statistically significantly altering the mean.
- Identify the phase of the PK profile with the lowest relative standard deviation (RSD%), typically the elimination phase.
- Use this lowest RSD% value, along with the known precision of your analytical method (CV%,an), to optimize and transform the entire concentration-time dataset.
- This method has been shown to more than halve the SD of PK parameters, providing a clearer and more selective pharmacokinetic profile [8].
Problem: Machine learning recommendations are not converging on an optimal design.
- Potential Cause: The training data is too noisy or biased for the ML algorithm to learn effectively [10].
- Solution:
- Algorithm Selection: In low-data regimes, choose machine learning methods proven to be robust to noise and training set biases, such as Gradient Boosting or Random Forest [10].
- Cycle Strategy: If the number of strains you can build is limited, favor starting with a larger initial DBTL cycle to generate a more substantial baseline dataset for the model to learn from, rather than distributing the same number of builds evenly across multiple cycles [10].
- Platform Integration: Implement a fully automated DBTL platform where an algorithm, such as a Bayesian optimizer, can actively select new designs based on real-time data, effectively managing the noise through sequential, informed experimentation [4] [5].
Quantitative Data on Variability and DBTL Performance
Table 1: Impact of Data Optimization on Pharmacokinetic Variability This table summarizes the effect of a specific data transformation technique on the variability of pharmacokinetic parameters for a high-variability drug [8].
| Pharmacokinetic Parameter | Variability Before Optimization (SD) | Variability After Optimization (SD) | Reduction in Variability |
|---|---|---|---|
| Overall Concentration Data | High | More than 2x lower | > 50% |
| Absorption & Early Distribution Phase Profile | High variability, less selective | Lower variability, more selective | Significant |
Table 2: Machine Learning Algorithm Performance in Noisy, Low-Data Environments A simulation-based study evaluated different ML algorithms for combinatorial pathway optimization, a common DBTL challenge [10].
| Machine Learning Algorithm | Performance in Low-Data/Noisy Regime | Key Characteristics for DBTL |
|---|---|---|
| Gradient Boosting | Outperforms other methods | Robust to training set biases and experimental noise [10] |
| Random Forest | Outperforms other methods | Robust to training set biases and experimental noise [10] |
| Other Tested Methods | Lower performance | More susceptible to data variability |
Detailed Experimental Protocols
Protocol 1: Establishing an Autonomous Test-Learn Cycle Using a Robotic Platform
Objective: To autonomously optimize inducer concentration for protein expression in a bacterial system, closing the DBTL loop without human intervention [4].
Methodology:
- System Setup: An E. coli or Bacillus subtilis system with a GFP reporter gene under an inducible promoter is used.
- Cultivation: Bacteria are cultivated in 96-well microtiter plates (MTPs) inside a fully integrated robotic platform, which includes a shake incubator, liquid handling robots, and a plate reader.
- Initial Experiment: The platform executes a pre-defined set of inducer concentrations.
- Data Acquisition: The platform's plate reader measures optical density (OD600) and fluorescence at defined time points.
- Active Learning:
- An importer software component retrieves the measurement data and writes it to a database.
- An optimizer (e.g., a Bayesian algorithm) selects the next set of inducer concentrations to test based on a balance of exploration and exploitation.
- Iteration: The platform directly executes the new experiments suggested by the optimizer, completing multiple full Test-Learn cycles autonomously [4].
Protocol 2: Data Transformation to Reduce Pharmacokinetic Variability
Objective: To significantly reduce the standard deviation of observed drug concentrations in a pharmacokinetic study without a statistically significant influence on the mean [8].
Methodology:
- Data Collection: Collect full concentration-time (C-T) profiles from subjects after a single oral drug administration.
- Identify Stable Phase: Determine the phase of the PK profile with the lowest relative standard deviation (RSD%), which is typically the elimination phase where the process is dominated by a single mechanism.
- Assess Analytical Precision: Note the precision (CV%) of the bioanalytical method used.
- Transformation: Apply a mathematical transformation to the entire C-T dataset, using the lowest RSD% from the elimination phase and the analytical method precision as reference points to optimize and reduce variability in the more chaotic absorption and distribution phases [8].
DBTL Workflow and System Diagrams
Automated DBTL with Noise
Automated Platform Architecture
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Key Reagents and Platforms for Managing DBTL Variability
| Item / Solution | Function in DBTL Cycle | Role in Mitigating Variability |
|---|---|---|
| Robotic Liquid Handling Platform [4] | Automates the "Build" and "Test" phases (e.g., pipetting, cultivation). | Eliminates manual errors and provides high reproducibility for large-scale experiments. |
| Integrated Robotic Platform (e.g., iBioFAB [5], Analytik Jena [4]) | A fully automated biofoundry that integrates incubators, liquid handlers, and plate readers. | Creates a controlled, consistent environment for end-to-end experimentation, minimizing batch effects. |
| Bayesian Optimization Algorithm [5] | Drives the "Learn" phase by selecting the next experiments. | Efficiently navigates noisy experimental landscapes by balancing exploration and exploitation. |
| High-Throughput RNA-seq Platform [11] | Generates comprehensive gene expression data for thousands of molecules. | Provides deep, multi-parametric data that helps build robust ML models less sensitive to noise. |
| QbD Excipient Samples [9] | Provides excipient batches that represent the highest and lowest limits of specification ranges. | Allows formulators to test and build robustness to material variability directly into their drug development process. |
In automated biofoundries, experimental noise—the unwanted variability in data that obscures true biological signals—is a fundamental challenge that can compromise the integrity of the Design-Build-Test-Learn (DBTL) cycle. Noise originates from multiple sources: biological (stochastic fluctuations within cells), technical (instrumentation and protocols), and data-related (computational modeling). Effectively identifying, quantifying, and mitigating these sources is critical for achieving reproducible, high-throughput biological research and development. This guide provides a systematic breakdown of common noise sources and practical troubleshooting strategies for researchers and scientists.
FAQs: Identifying and Troubleshooting Noise
1. What are the most common sources of biological noise in cell-based assays?
Biological noise arises from inherent stochasticity in cellular processes. Key sources and solutions include:
- Genetic Expression Variability: Stochastic fluctuations in transcription and translation lead to cell-to-cell differences in protein and metabolite levels, even in clonal populations [12].
- Cellular Response to Drugs: Non-uniform distribution of macromolecules and varying cellular abilities to sense the environment cause divergent responses to identical drug stimuli [12].
- Circadian Rhythms: About 50% of human genes follow a circadian cycle, influencing drug metabolism and inflammatory responses, which introduces temporal variability if experiments are conducted at different times [12].
- Troubleshooting Steps:
- Implement Controlled Environments: Use incubators that tightly regulate temperature, humidity, and CO₂. For light-sensitive processes, control light-dark cycles.
- Standardize Cell Passaging: Maintain consistent cell passage numbers and confluence levels at the start of experiments to minimize drift in phenotypic behavior.
- Utilize Biosensors: Integrate genetic circuits (e.g., RNA-based riboswitches or transcription factors) to monitor intracellular metabolite levels in real-time, helping to distinguish true biological signals from noise [13].
2. How can I determine if my automated instrumentation is introducing technical noise?
Technical noise originates from the automated platforms and liquid handling systems themselves.
- Liquid Handler Inaccuracy: Improper calibration can lead to systematic errors in dispensed volumes, directly impacting cell growth and metabolite production measurements. For example, in media optimization, an error in a single component like salt (NaCl) can drastically alter production yields [14].
- Sensor Drift in Bioreactors: Probes for pH, dissolved oxygen, or temperature can drift over time, leading to inaccurate environmental control and increased heterogeneity between culture vessels [15].
- Edge Effects in Microplates: Evaporation and temperature gradients in multi-well plates can cause wells on the perimeter to behave differently from interior wells.
- Troubleshooting Steps:
- Perform Regular Calibration: Establish a strict schedule for calibrating pipettes, liquid handlers, and bioreactor probes using traceable standards.
- Run Dye Tests: Use fluorescent or colored dyes in water to visually and quantitatively check for volume dispensation accuracy and consistency across all nozzles and tips of a liquid handler.
- Conduct Blank and Control Experiments: Include negative controls and technical replicates across different plate locations (center vs. edge) to quantify and correct for positional biases.
3. My machine learning models are not converging during the 'Learn' phase. Could data noise be the cause?
Yes, noise in the training data is a primary reason for poor model performance. Machine learning models, like the Gaussian Processes used in Bayesian optimization, are highly sensitive to noisy data [15] [14].
- Insufficient Data Quality: Models trained on small or highly variable datasets will fail to learn the underlying biological function and instead model the noise [15].
- Heteroscedastic Noise: This is noise whose magnitude is not constant but depends on the input parameters (e.g., measurement error is larger at high metabolite concentrations). Standard models that assume constant noise will perform poorly [15].
- Troubleshooting Steps:
- Increase Replicates: Incorporate more technical and biological replicates to robustly estimate and account for experimental noise.
- Use Noise-Aware Models: Employ Bayesian optimization frameworks that explicitly model heteroscedastic noise. These models can separate signal from noise more effectively, leading to faster convergence on the true optimum [15].
- Feature Selection: Prior to modeling, use techniques like Principal Component Analysis (PCA) to reduce high-dimensional data and filter out non-informative, noisy features [16].
4. What strategies can reduce noise when scaling up from microplates to bioreactors?
Scale-up is a major source of noise due to changing physical and chemical environments.
- Environmental Gradients: Large bioreactor vessels develop gradients in nutrients, pH, and dissolved oxygen that are absent in well-mixed microplates [13].
- Population Heterogeneity: The larger cell population in a bioreactor can exhibit increased genotypic and phenotypic diversity.
- Troubleshooting Steps:
- Implement Dynamic Control: Use genetic circuits with biosensors to enable dynamic regulation of pathways. This allows cells to auto-adjust to changing bioreactor conditions, improving robustness and yield [13].
- Characterize Mass Transfer: Profile the kLa (volumetric oxygen transfer coefficient) and mixing times in the bioreactor to ensure homogeneous conditions.
- Employ Scale-Down Models: Create small-scale (e.g., in microplates) models that mimic the environmental fluctuations anticipated at large scale. This allows for high-throughput strain and media optimization under more relevant conditions [14].
The table below summarizes key noise types, their origins, and measurable impacts on data, providing a reference for diagnostics.
| Noise Category | Specific Source | Typical Impact on Data | Mitigation Strategy |
|---|---|---|---|
| Biological | Genetic drift in microbial populations [12] | Increasing variance in production yield (titer) over serial passages | Use cryopreserved master cell banks; limit passaging |
| Biological | Cell-to-cell variation in pathway expression [12] | High coefficient of variation (>20%) in fluorescence from reporter genes | Use flow cytometry to characterize population distribution; implement constitutive expression controls |
| Technical | Liquid handler volumetric inaccuracy [14] | >5% CV in growth (OD600) across technical replicates in a plate | Regular calibration; use of liquid class optimization for different reagents |
| Technical | Edge effects in 48-well plates [14] | 15-30% deviation in growth metrics between edge and center wells | Use plate covers to reduce evaporation; exclude edge wells or use statistical correction |
| Data | Heteroscedastic measurement error [15] | Poor predictive performance (high RMSE) of machine learning models in high-output regions | Use Bayesian optimization with heteroscedastic noise modeling [15] |
| Data | Technical variability in scRNA-seq [12] | Distortion in Highly Variable Genes (HVG) list, masking true biological variation | Use computational tools (e.g., DDG model) to distinguish technical from biological variation [12] |
Experimental Protocols for Noise Quantification
Protocol 1: Quantifying Technical Noise in a Liquid Handling System
- Objective: To measure the accuracy and precision of a liquid handler's dispensation, a key source of technical noise.
- Materials: PBS buffer, fluorescent dye (e.g., fluorescein), microplate reader, black-walled 96-well or 384-well microplates.
- Method:
- Prepare a solution of PBS with a known concentration of fluorescent dye.
- Program the liquid handler to dispense a target volume (e.g., 10 µL) of the dye solution into every well of the microplate (n≥5 replicates per column).
- Use a microplate reader to measure the fluorescence intensity in each well.
- Data Analysis: Calculate the mean fluorescence for each column and the coefficient of variation (CV) across all replicates. A CV > 5% indicates significant technical noise introduced by the liquid handler. Compare the mean measured fluorescence to a standard curve to assess accuracy (systematic error).
Protocol 2: Characterizing Biological Noise in a Production Strain
- Objective: To measure the inherent strain-to-strain and day-to-day variability of a microbial production system.
- Materials: Production strain, appropriate growth medium, deep-well plates, microplate reader, HPLC or GC-MS for product quantification.
- Method:
- Inoculate production strain from a single colony into liquid medium and grow overnight.
- The next day, sub-culture into fresh medium in a deep-well plate. Use at least 12 biological replicates (independent cultures).
- Grow cultures under standard production conditions (e.g., 48 hours, 30°C).
- Measure both the optical density (OD600) and the product titer (e.g., via absorbance or HPLC) for each culture.
- Repeat this experiment on three separate days to capture day-to-day variability.
- Data Analysis: Calculate the CV for both OD and product titer for within-day (biological noise) and between-day (total process noise) datasets. This establishes a baseline for expected noise levels and helps determine the necessary number of replicates for future DBTL cycles.
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in Noise Management |
|---|---|
| Cell-Free Transcription-Translation (TX-TL) Systems [17] | Bypasses cellular complexity and growth-related variability, providing a highly reproducible and rapid platform for testing genetic parts and circuit behavior. |
| RNA-based Biosensors (Riboswitches/Toehold Switches) [13] | Enable real-time, non-destructive monitoring of specific intracellular metabolites, allowing researchers to track and account for metabolic noise in living cells. |
| Automated Cultivation Platform (e.g., BioLector) [14] | Provides tight control over culture conditions (O2, humidity, shaking) in microplates, minimizing environmental noise and improving data reproducibility for fermentation optimization. |
| Gaussian Process (GP) Models with Heteroscedastic Kernels [15] | A machine learning model that does not assume constant noise; it can learn how measurement uncertainty changes across the experimental space, leading to more robust predictions. |
Workflow Diagram: Managing Noise in the DBTL Cycle
The following diagram illustrates a robust DBTL workflow that integrates noise management strategies at every stage.
Frequently Asked Questions
Q1: What are the primary sources of noise in metabolic pathway data, and how can I quantify their impact? Cellular noise originates from stochastic biochemical events and results in significant cell-to-cell heterogeneity, even in clonal populations. You can quantify this using high-throughput quantitative mass imaging techniques, such as Spatial Light Interference Microscopy (SLIM), which captures the optical-phase delay (ΔΦ) of the cell cytosol and lipid droplets to calculate dry-mass values with single-cell resolution [18]. This method provides more than 55% higher precision than conventional microscopy, allowing you to precisely measure how resources are partitioned between growth and productivity and to detect subpopulations with distinct metabolic trade-offs [18].
Q2: My DBTL cycles are yielding inconsistent results due to experimental noise. What computational approaches can help? Implement a nonparametric Bayesian framework using Gaussian Process Regression (GPR) to infer dynamic reaction rates from metabolite concentration measurements without requiring explicit time-dependent flux data [19]. This approach allows you to model metabolic dynamics and perform hierarchical regulation analysis even with noisy data. Furthermore, machine learning methods, particularly gradient boosting and random forest models, have proven robust against training set biases and experimental noise in the low-data regimes typical of initial DBTL cycles [20].
Q3: How can I distinguish between hierarchical and metabolic regulation in my noisy pathway data? Apply dynamic Hierarchical Regulation Analysis (HRA), which quantifies the contributions of enzyme concentration changes (hierarchical regulation) versus metabolic effector changes (metabolic regulation) to flux control [19]. The time-dependent hierarchical regulation coefficient can be calculated as ρhi(t) = [ln h(ei(t)) - ln h(ei(t0))] / [ln vi(t) - ln vi(t0)], where h(ei) represents enzyme capacity and vi is the reaction rate. The metabolic regulation coefficient is then derived as ρmi(t) = 1 - ρh_i(t) [19].
Q4: What experimental design maximizes signal detection when working with noisy single-cell data? Incorporate multiple independent replicate cultures (at least 3 per condition) and aim for large observation numbers (≥10,000 single-cells) to achieve statistical power [18]. Use cross-correlation imaging approaches to suppress cytosolic signal and enhance specific organelle localization, which achieved >98% agreement with fluorescence-based methods while accelerating processing to >1,000 single-cell observations per condition [18].
Experimental Protocols for Noise Quantification
Protocol 1: Single-Cell Trade-Off Analysis Using Quantitative Phase Imaging
Purpose: To quantify metabolic trade-offs between growth and product formation at single-cell resolution while accounting for cellular noise [18].
Materials:
- Yarrowia lipolytica culture (or your target microorganism)
- Spatial Light Interference Microscopy (SLIM) system
- Two coverslips per sample
- U-13C glucose for NanoSIMS validation
Methodology:
- Sample Preparation: Place 2µL of growing culture between two coverslips without further processing.
- Image Acquisition: Transfer sample to SLIM system and capture both phase-contrast intensity images and quantitative phase images by projecting onto a spatial light modulator.
- Data Conversion: Convert ΔΦcytosol and ΔΦTAG to dry-mass values using protein-specific refractive index increment for cytosol and Clausius-Mossotti equation for lipid droplets.
- Image Processing: Localize cell-contour and lipid droplets via ΔΦ levels, using additional wavefront modulation (π/2 and π) to enhance LD-to-cytosol contrast.
- Validation: Confirm cytosolic and LD elemental composition using NanoSIMS after 13C glucose exposure.
Expected Outcomes: Quantitative bivariate analysis of growth-productivity trade-offs, identification of metabolic subpopulations, and determination of cell-to-cell heterogeneity in macromolecule recycling under nutrient limitation [18].
Protocol 2: Dynamic Flux Inference Using Gaussian Process Regression
Purpose: To accurately infer time-dependent metabolic fluxes from metabolite concentration measurements for dynamic regulation analysis [19].
Materials:
- Time-series metabolite concentration data
- Gaussian Process Regression computational framework
- Network stoichiometry of the target pathway
Methodology:
- Data Preprocessing: Estimate high-resolution time-dependent metabolite profiles from discrete measurements using GPR.
- Derivative Calculation: Approximate derivatives of metabolite concentrations from the GP derivatives.
- Flux Inference: Calculate dynamic reaction rates from derivatives and network stoichiometry using the relationship: vi = ẋi+1 + ... + ẋN + gN(x_N) for linear pathways.
- Pathway Simplification: For branched pathways, combine reaction rates to match the number of metabolites (e.g., ṽ1 = v1 - v_4 for branched pathways).
- Regulation Analysis: Compute time-dependent hierarchical regulation coefficients from inferred reaction rates and enzyme profiles.
Expected Outcomes: Complete temporal hierarchical regulation profiles for each reaction with statistical confidence, without requiring direct flux measurements [19].
Quantitative Data Analysis Tables
Table 1: Correlation Analysis of Single-Cell Parameters in Y. lipolytica
| Parameter Pair | Spearman Correlation Coefficient (ρ) | P-value | Number of Observations | Conditions Tested |
|---|---|---|---|---|
| LD Volume vs. TAG Number-Density | 0.65 | <0.001 | 25,960 individual LDs | 7 different conditions, 3 replicates each [18] |
| Cell Dry-Density vs. Cell Volume | -0.6 | <0.001 | 13,770 individual cells | 7 different conditions, 3 replicates each [18] |
Table 2: Machine Learning Performance in DBTL Cycle Optimization
| ML Method | Performance in Low-Data Regime | Robustness to Training Set Bias | Robustness to Experimental Noise | Recommended Application |
|---|---|---|---|---|
| Gradient Boosting | Superior | High | High | Initial DBTL cycles with limited data [20] |
| Random Forest | Superior | High | High | Initial DBTL cycles with limited data [20] |
| Other Tested Methods | Variable | Variable | Variable | Not recommended for low-data scenarios [20] |
The Scientist's Toolkit: Research Reagent Solutions
| Reagent/Technique | Function | Application Context |
|---|---|---|
| Spatial Light Interference Microscopy (SLIM) | Captures optical-phase delay (ΔΦ) of cellular components | Quantifying dry-mass of cytosol and lipid droplets at single-cell resolution [18] |
| Gaussian Process Regression (GPR) | Nonparametric Bayesian modeling for time-series data | Inferring dynamic metabolic fluxes from metabolite measurements [19] |
| Nanoscale Secondary Ion Mass Spectrometry (NanoSIMS) | Characterizes elemental composition at subcellular level | Validating cytosolic and lipid droplet composition; confirming 13C incorporation [18] |
| U-13C Glucose | Isotope-labeled substrate for metabolic tracing | Tracking carbon allocation and validating mass imaging measurements [18] |
| Clausius-Mossotti Equation | Converts refractive index to molecular number-density | Determining TAG molecule count in lipid droplets from phase imaging data [18] |
Experimental Workflow Diagrams
Diagram 1: DBTL Cycle with Noise Integration
Diagram 2: Single-Cell Mass Imaging Workflow
Machine Learning and Algorithmic Solutions for Noisy Biological Data
Bayesian Optimization as a Robust Framework for Noisy Black-Box Functions
Frequently Asked Questions (FAQs)
Q1: My Bayesian optimization is converging slowly or to a poor solution. What are the most common causes?
Poor convergence in Bayesian optimization (BO) often stems from three common issues: an incorrect prior width, over-smoothing by the surrogate model, or inadequate maximization of the acquisition function [21] [22]. An incorrectly set prior width can misrepresent the function's variability, while over-smoothing occurs when the kernel lengthscale is too large, causing the model to miss important details. Furthermore, if the acquisition function is not maximized effectively, the algorithm may select suboptimal points for evaluation.
Q2: How can I handle experiments that fail and produce no measurable output?
A robust method is the "floor padding trick": when an experiment fails, assign it the worst objective value observed so far in the campaign [23]. This simple and adaptive method informs the surrogate model that the parameter set led to a failure, encouraging the algorithm to avoid similar regions in subsequent iterations without requiring pre-defined, problem-specific constants.
Q3: My experimental measurements are very noisy. How can I make BO more robust?
For noisy observations, consider augmenting your standard acquisition function or implementing a retest policy [24] [25]. A retest policy selectively repeats experiments to confirm the performance of promising candidates, which mitigates the risk of being misled by single, noisy measurements. Noise-augmented acquisition functions are also designed to be more robust to non-Gaussian and high-variance noise processes [25].
Q4: Can I use low-fidelity, cheap experiments to accelerate the optimization of high-fidelity, expensive ones?
Yes, this is the goal of Multifidelity Bayesian Optimization (MF-BO) [26]. MF-BO uses a unified surrogate model to learn the relationship between different experimental fidelities (e.g., computational docking, single-point assays, and dose-response curves). It then uses an acquisition function, like Targeted Variance Reduction, to optimally allocate a fixed budget by deciding whether to perform many cheap low-fidelity experiments or a few expensive high-fidelity ones at each step.
Troubleshooting Guides
Problem 1: The BO algorithm is not exploring the parameter space effectively.
Symptoms: The algorithm gets stuck in a local optimum and fails to discover better regions.
Diagnosis and Solutions:
- Check Hyperparameters: The most common fix is to properly tune the hyperparameters of your Gaussian Process surrogate model, particularly the kernel lengthscale and prior width [21]. An overly large lengthscale can cause over-smoothing, preventing the discovery of local optima.
- Adjust Acquisition Function: If using the Upper Confidence Bound (UCB), try increasing the
βparameter, which controls the exploration-exploitation trade-off. A higherβvalue gives more weight to uncertain regions, promoting exploration [21]. - Validate Model Fit: Ensure your surrogate model's predictions are consistent with your observed data. A poor model fit indicates that the kernel or its hyperparameters may be inappropriate for your specific problem.
Problem 2: Dealing with failed experiments and missing data.
Symptoms: Experimental runs occasionally fail to produce a result, creating "missing data" that disrupts the optimization loop.
Diagnosis and Solutions:
- Implement the Floor Padding Trick: This is a direct and effective solution [23].
- Methodology: When an experiment at parameter
x_nfails, simply set its objective valuey_nto the minimum value observed in all previous successful experiments:y_n = min(y_1, ..., y_{n-1}). - Rationale: This automatically labels the failed parameter set as poor without requiring manual tuning of a penalty value. It updates the surrogate model to recognize the region around
x_nas low-performing, guiding future iterations away from it.
- Methodology: When an experiment at parameter
- Combine with a Failure Predictor: For a more advanced approach, you can train a binary classifier to predict the probability of failure for a given parameter set [23]. This can be used alongside the floor padding trick to actively avoid parameters with a high predicted chance of failure.
Problem 3: Optimization performance is degraded by high experimental noise.
Symptoms: The algorithm appears to make erratic decisions, often selecting points that later prove to be poor, due to unreliable measurements.
Diagnosis and Solutions:
- Employ a Retest Policy: In batched BO, you can dedicate a portion of your batch to retesting previously evaluated candidates [24].
- Methodology: For each batch, identify a subset of the most promising candidates (e.g., those with the highest predicted mean or those that were highly ranked but had high uncertainty) and repeat the experiment. Replace their recorded value with the average of the retests.
- Rationale: This reduces the variance in the data set for critical candidates, leading to a more accurate surrogate model and preventing the algorithm from chasing noise-driven outliers.
- Use a Noise-Robust Acquisition Function: Standard acquisition functions can be deceived by noise. Consider switching to ones specifically designed for noisy settings, which can handle non-Gaussian noise distributions like those found in molecular dynamics simulations or polymer crystallization studies [25].
Problem 4: Optimizing a high-fidelity property is prohibitively expensive.
Symptoms: The target property is very expensive or time-consuming to measure, making a full BO campaign infeasible.
Diagnosis and Solutions:
- Adopt a Multifidelity (MF-BO) Approach: Leverage cheaper, correlated experimental fidelities to guide the optimization [26].
- Methodology:
- Define your experimental fidelities (e.g., Low: computational docking score; Medium: single-point percent inhibition; High: dose-response IC50 value).
- Use a surrogate model (e.g., Gaussian Process with a Tanimoto kernel for molecules) that can learn the correlation between fidelities and molecular structure.
- Use a multifidelity acquisition function like Targeted Variance Reduction (TVR). This function selects the next (molecule, fidelity) pair that maximizes the expected improvement at the high-fidelity level, weighted by the cost of the experiment.
- Rationale: MF-BO allows you to perform many low-cost experiments to explore the search space efficiently, only using the expensive high-fidelity assay to confirm the most promising candidates.
- Methodology:
Experimental Protocols & Data
This protocol integrates directly into the BO loop.
- Initialization: Start with an initial dataset of parameters and successful evaluations.
- BO Iteration:
a. Fit the Gaussian Process surrogate model to the current data.
b. Maximize the acquisition function to select the next parameter
x_n. c. Run the experiment atx_n. - Failure Handling:
a. If the experiment is successful, record the true measurement
y_nand proceed. b. If the experiment fails, sety_n = min(y_1, ..., y_{n-1})(the worst value observed so far). - Update: Augment the dataset with
(x_n, y_n)and return to Step 2.
This protocol is designed for running experiments in batches, common in drug discovery.
- Initialization: Train an initial QSAR model (e.g., Random Forest or Gaussian Process) on a randomly selected batch of molecules.
- Batch Selection:
a. Use the model to predict the activity and uncertainty of all untested molecules.
b. Rank the molecules using an acquisition function (e.g., Expected Improvement, Upper Confidence Bound).
c. Select the top
Kmolecules for the next batch. To implement the retest policy, replace the lowest-rankedRof these new molecules withRretests of previously tested, high-potential candidates. - Experimentation & Update: Perform the batch of experiments (both new and retests). Update the dataset with the new results. If a molecule is retested, update its activity value with the average of all its measurements.
- Iteration: Retrain the surrogate model on the updated dataset and repeat from Step 2.
Table 1: Comparison of Bayesian Optimization Methods for Handling Noise and Failures.
| Method | Primary Use Case | Key Mechanism | Advantages |
|---|---|---|---|
| Floor Padding Trick [23] | Handling experimental failures | Assigns the worst-seen value to failed experiments | Simple, adaptive, requires no prior knowledge of penalty values |
| Retest Policy [24] | Mitigating experimental noise | Selectively repeats experiments to average out noise | Reduces variance in key candidates, improves model accuracy |
| Multifidelity BO (MF-BO) [26] | Optimizing expensive high-fidelity properties | Uses cheap, low-fidelity data to guide high-fidelity experiments | Dramatically reduces total cost and time of optimization campaign |
| Noise-Augmented Acquisition [25] | Non-Gaussian, high-variance noise | Modifies the acquisition function to be robust to specific noise types | Can handle complex noise distributions (e.g., exponential) |
The Scientist's Toolkit: Key Reagents & Materials
Table 2: Essential Materials for a Multifidelity Drug Discovery Campaign, as described in [26].
| Item / Reagent | Function in the Experiment |
|---|---|
| Genetic Algorithm-Generated Compound Library | Provides a diverse and synthetically feasible search space of candidate drug molecules. |
| Low-Fidelity Assay (e.g., Computational Docking) | A cheap, rapid virtual screen to predict a molecule's binding affinity to the target protein. |
| Medium-Fidelity Assay (e.g., Single-Point % Inhibition) | A physical lab assay providing an initial, medium-cost readout of biological activity. |
| High-Fidelity Assay (e.g., Dose-Response IC50) | The gold-standard, expensive experiment that accurately measures the potency of a compound. |
| Gaussian Process Surrogate Model with Tanimoto Kernel | The machine learning model that learns the relationship between molecular structure and activity across all fidelities. |
Workflow Visualizations
Diagram 1: DBTL Cycle with Robust Bayesian Optimization
Diagram 2: Multifidelity Bayesian Optimization for Drug Discovery
Leveraging Gaussian Processes for Probabilistic Predictions and Uncertainty Quantification
Frequently Asked Questions
Q1: What are the main types of predictive uncertainty, and how are they modeled? A: Gaussian Process (GP) models quantify two fundamental types of uncertainty: aleatoric and epistemic. Aleatoric uncertainty is the inherent noise in the observations themselves, which cannot be reduced with more data. Epistemic uncertainty is the uncertainty in the model due to a lack of knowledge or data; this type can be reduced as more data becomes available. GP models naturally capture both by providing a full predictive distribution for a new input point, where the predictive variance represents the combined uncertainty [27].
Q2: My dataset is large; are GPs still computationally feasible? A: Standard GPs can be slow for large datasets. However, scalable approximations are available. A common method mentioned in recent research is the use of Random Fourier Features (RFF) to approximate the GP kernel. This technique allows for more efficient computation, making GPs applicable to larger datasets common in modern experimental science [27].
Q3: How can I integrate UQ from GPs into an autonomous experimental cycle? A: The uncertainty estimates from a GP are key for autonomous decision-making. The GP model can be used as a surrogate model within a Design-Build-Test-Learn (DBTL) cycle. The optimizer can query the GP to suggest the next experiment by balancing exploration (probing areas of high epistemic uncertainty) and exploitation (testing areas predicted to have high performance), thereby closing the loop autonomously [28].
Q4: What is the practical difference between the predictive mean and variance? A: The predictive mean is the model's best guess for the target value at a new input. The predictive variance quantifies the confidence in that guess. A high variance indicates low confidence, which could be due to the input being far from the training data (high epistemic uncertainty) or high inherent noise (high aleatoric uncertainty). This is crucial for assessing the reliability of a prediction [27].
Q5: How do I know if my uncertainty quantification is well-calibrated? A: A well-calibrated model means that when it predicts a 90% confidence interval, the true value falls within that interval 90% of the time. You can assess this by using held-out test data. Calculate how often the true values fall within the predicted confidence intervals across your test set; the empirical coverage should match the predicted coverage. A GP with a correctly specified kernel and likelihood should produce well-calibrated uncertainties [27].
Troubleshooting Guides
Problem: Poor Predictive Performance and Miscalibrated Uncertainty
Possible Causes and Solutions:
- Incorrect Kernel Choice: The kernel function defines the properties of the functions your GP can learn. If your data shows smooth trends, a Radial Basis Function (RBF) kernel is appropriate. For periodic data, use a periodic kernel. Experiment with different kernels and combinations.
- Hyperparameter Optimization: The kernel's hyperparameters (e.g., length-scale, variance) greatly impact performance. These should not be set arbitrarily. Use optimization techniques like maximum marginal likelihood or Markov Chain Monte Carlo (MCMC) to fit them to your data.
- Inadequate Likelihood Model: If your noise is non-Gaussian (e.g., your data is count-based or binary), a standard GP will be misspecified. Switch to a variant like a Poisson GP for count data or a Bernoulli GP for classification, which use different likelihood functions.
Problem: Model is Too Slow or Does Not Scale
Possible Causes and Solutions:
- Large Training Dataset: The computational complexity of a standard GP scales with the cube of the number of data points (O(n³)), making it slow for large datasets (n > 10,000).
- Solution: Implement scalable approximations such as Sparse GPs (using inducing points) or Random Fourier Features (RFF) [27]. These methods reduce computational complexity, making training and prediction faster.
Problem: High Uncertainty on All Predictions
Possible Causes and Solutions:
- Excessive Kernel Length-Scale: If the length-scale hyperparameter is too large, the model assumes all points are highly correlated and will be overly general, leading to high uncertainty everywhere.
- Solution: Re-optimize the kernel hyperparameters, paying close attention to the length-scale.
- Lack of Data in a Region: High epistemic uncertainty is a natural and useful output. It indicates that the model has not seen enough data in that region of the input space.
- Solution: This is a feature, not a bug. In an active learning or autonomous DBTL cycle, these high-uncertainty regions should be targeted for new experiments [28].
Experimental Protocols
Protocol 1: Uncertainty Quantification for a Synthetic Biological Circuit
This protocol outlines how to use a GP for UQ when optimizing a biological process, such as protein production in a DBTL cycle [28].
1. Objective: To build a probabilistic model that predicts protein fluorescence output based on input factors (e.g., inducer concentration) and provides a reliable measure of prediction uncertainty to guide autonomous experimentation.
2. Materials:
- Robotic Platform: An integrated system with liquid handlers, a microtiter plate incubator, and a plate reader for high-throughput, automated cultivation and measurement [28].
- Biological System: Engineered E. coli or Bacillus subtilis with a inducible promoter controlling the expression of a reporter protein (e.g., Green Fluorescent Protein, GFP).
- Software Framework: A database to store experimental data and an optimizer module that uses the GP model to select the next set of experimental conditions [28].
3. Method:
- Step 1: Initial Experimental Design. Perform a space-filling design (e.g., Latin Hypercube) or a random search across the input factor space (e.g., inducer levels from 0-1 mM) to collect an initial dataset.
- Step 2: Automated Build & Test.
- The robotic platform prepares cultures in microtiter plates, adds inducers according to the design, and incubates them.
- The platform periodically measures optical density (OD600) and fluorescence.
- Step 3: Learn with Gaussian Process.
- Train a GP model on the collected data, using inputs (e.g., inducer concentration, time) to predict outputs (e.g., fluorescence/OD).
- The GP provides a posterior predictive distribution (mean and variance) for any untested condition.
- Step 4: Autonomous Optimization.
- The optimizer uses an acquisition function (e.g., Expected Improvement, Upper Confidence Bound) that balances the GP's predictive mean (exploitation) and variance (exploration).
- The optimizer selects the condition for the next experiment that maximizes this function.
- Step 5: Close the Loop. The robotic system automatically executes the new experiment(s) suggested in Step 4. The new data is added to the training set, and the cycle (Steps 3-5) repeats autonomously for multiple iterations.
4. Key Measurements:
- Input Variables: Inducer concentration, feed rate, induction time.
- Output/Target Variables: Final fluorescence intensity (GFP), final optical density (OD600).
Protocol 2: Benchmarking GP UQ with a Synthetic Dataset
1. Objective: To validate the accuracy of a GP's uncertainty estimates on a known function before applying it to real, noisy experimental data.
2. Method:
- Step 1: Generate Data. Sample inputs, ( x ), from a uniform distribution. Compute outputs from a known function, e.g., ( y = \sin(x) + \epsilon ), where ( \epsilon ) is Gaussian noise.
- Step 2: Train-Test Split. Reserve a portion of the data as a test set.
- Step 3: Model Training. Train a GP on the training data.
- Step 4: Prediction & UQ. Make predictions on the test set to obtain the mean ( \mu* ) and variance ( \sigma^2* ) for each test point.
- Step 5: Calibration Assessment. For a range of confidence levels (e.g., 90%, 95%), compute the empirical coverage: the proportion of test points where the true value lies within ( \mu* \pm z \cdot \sigma* ) (where ( z ) is the z-score). Plot empirical vs. predicted coverage to assess calibration.
Table 1: Standard Color Contrast Ratios for Accessibility in Visualizations [29] [30] [31]
| Element Type | Size / Condition | Minimum Contrast Ratio | Enhanced Contrast Ratio (Level AAA) |
|---|---|---|---|
| Text | Smaller than 18pt or 14pt bold | 4.5:1 | 7:1 |
| Text | 18pt or 14pt bold and larger | 3:1 | 4.5:1 |
| Non-text (UI, graphics) | Any | 3:1 | 3:1 |
Table 2: Key Reagent Solutions for Automated DBTL Experiments [28]
| Reagent / Material | Function in the Experiment |
|---|---|
| Microtiter Plates (MTP) | High-throughput cultivation vessel for bacterial cultures. |
| Inducers (e.g., IPTG, Lactose) | Triggers expression of the target protein from the inducible promoter. |
| Culture Media | Nutrient source for bacterial growth and protein production. |
| Substrate for Feed Release | Polysaccharide that is enzymatically broken down to control glucose release and growth rates. |
| Reporter Protein (e.g., GFP) | Easily measurable output to quantify system performance and model success. |
The Scientist's Toolkit
Table 3: Essential Computational & Modeling Tools
| Tool / Technique | Brief Explanation and Function |
|---|---|
| Scalable GP Approximations | Methods like Random Fourier Features (RFF) or Sparse GPs that reduce computational cost, enabling UQ on large datasets [27]. |
| Monte Carlo Sampling | A method used to estimate the predictive distribution and uncertainties from complex probabilistic models, including GPs [27]. |
| Acquisition Function | A function (e.g., Expected Improvement) used to decide the next experiment by balancing exploration and exploitation in an autonomous cycle [28]. |
| Kernel Function | The core of a GP that defines the covariance between data points, determining the shape and properties of the functions the model can learn. |
Experimental Workflow Visualizations
Implementing Heteroscedastic Noise Models for Non-Constant Biological Variance
FAQs: Understanding Heteroscedastic Noise in Biological Data
1. What is heteroscedastic noise and why is it problematic in biological DBTL cycles? Heteroscedastic noise refers to measurement noise variances that are not constant across all samples in your dataset. Unlike homoscedastic noise (constant variance), heteroscedastic noise means that different measurements have different levels of reliability. This is particularly problematic in Design-Build-Test-Learn (DBTL) cycles because it can lead to incorrect parameter optimization, unreliable model fits, and false conclusions about the significance of your results. When knowledge about noise levels is available, data can be processed in a much more rigorous way, allowing distinctions between what is statistically significant and what is not [32].
2. How can I detect heteroscedastic noise in my experimental data? You can detect heteroscedastic noise by analyzing the residuals of your model fits. Create a residual plot (residuals versus fitted values) and look for patterns such as a funnel shape where the spread of residuals increases or decreases systematically with the magnitude of the measured values. Statistical tests like the Breusch-Pagan test can also formally detect heteroscedasticity. The presence of such patterns indicates that the assumption of constant variance is violated [32].
3. What practical methods can I use to estimate heteroscedastic noise variances without replicate measurements? When replicate measurements are not available (which is common due to cost constraints), you can use a grouping approach. The method involves:
- Dividing your data into subsets where the noise variance can be assumed to be constant within each group.
- Starting from the residuals obtained from an initial model of your data.
- Applying a procedure that includes a correction to suppress possible model errors, making the noise variance estimation relatively independent of the specific model used. This approach copes with heteroscedastic noise variances and heterogeneous distribution of degrees of freedom [32].
4. How does handling heteroscedastic noise improve autonomous DBTL platforms? In automated robotic platforms used for biological optimization, properly accounting for heteroscedastic noise allows for more accurate assessment of model "goodness," enables the construction of weighted least squares cost functions, and helps detect systematic errors by comparing residuals with estimated uncertainties. This leads to more reliable autonomous decision-making, as the platform can better distinguish between significant effects and noise when selecting the next measurement points [32] [28].
5. Can I model heteroscedastic noise variances parametrically? Yes, one strategy is to model noise variances as a parametric function of the response. However, this approach requires that the class of the variance function (e.g., polynomial, rational) is well known, which is often not the case in biological experiments. When the functional form is unknown, the non-parametric grouping method described above is generally more reliable [32].
Troubleshooting Guides
Issue 1: Poor Model Performance Despite Good Experimental Design
Symptoms:
- Inconsistent parameter estimates across similar experiments
- Poor predictive performance of models developed in DBTL cycles
- Statistical significance of factors changes unpredictably
Solutions:
- Implement Weighted Least Squares: Instead of standard least squares, use a cost function that weights each data point by the inverse of its estimated variance. This ensures that more reliable measurements have greater influence on the parameter estimates [32].
- Estimate Noise Variances from Residuals: Apply the following protocol:
- Fit an initial model to your data using ordinary least squares.
- Divide your dataset into meaningful subsets based on experimental conditions (e.g., different time points, inducer concentrations).
- Calculate the variance of residuals within each subset.
- Apply a correction factor to account for potential model errors [32].
- Validate with Domain Knowledge: Compare the estimated noise variances with expectations from your biological system to identify potential issues.
Issue 2: Unreliable Optimization in Autonomous DBTL Platforms
Symptoms:
- Robotic platform makes poor decisions about next experimental conditions
- Failure to converge to optimal solutions in protein expression or metabolite production
- High variability in outcomes across DBTL iterations
Solutions:
- Integrate Noise Estimation into Learning Modules: Ensure your platform's optimizer includes noise variance estimation when selecting next measurement points. The software framework should:
- Retrieve measurement data from platform devices
- Estimate noise levels for different experimental conditions
- Balance exploration and exploitation while accounting for measurement reliability [28]
- Implement Iterative Re-weighting: For continuous optimization, update noise variance estimates between DBTL cycles to refine the weighting of different data types.
- Calibrate with Control Experiments: Include reference points with known expected outcomes to monitor and correct for systematic noise variations.
Issue 3: Handling Biological Variability in High-Throughput Experiments
Symptoms:
- Batch-to-batch differences introduce unexpected noise patterns
- Difficulty distinguishing true biological effects from technical noise
- Inconsistent results when scaling up from microtiter plates to bioreactors
Solutions:
- Structured Noise Modeling: Implement the stepwise variance estimation procedure that:
- Groups observations with similar expected noise characteristics
- Estimates variances within each group separately
- Corrects for model errors to prevent bias in variance estimates [32]
- Design Experiments to Characterize Noise: Include sufficient replication at strategic points in your experimental design to directly estimate variance components.
- Adaptive Sampling: Use initial results to guide more intensive sampling in regions of higher noise or greater biological interest.
Experimental Protocols
Protocol 1: Estimation of Heteroscedastic Noise Variances from Residuals
Purpose: To estimate measurement noise variances that vary across experimental conditions when replicate measurements are not available.
Materials:
- Dataset with measured responses and experimental conditions
- Computational environment (R, Python, or MATLAB)
- Initial model describing the system
Procedure:
- Fit Initial Model: Apply an appropriate model to your dataset using standard regression techniques.
- Calculate Residuals: Compute the residuals (differences between observed and predicted values) for all data points.
- Group Data: Divide your data into subsets where noise variance can be assumed constant. Grouping can be based on:
- Experimental batches
- Response magnitude ranges
- Specific experimental conditions
- Calculate Within-Group Variances: For each subset, calculate the variance of the residuals.
- Apply Model Error Correction: Adjust the variance estimates to account for potential biases introduced by model errors using the formula: Corrected Variance = (Residual Sum of Squares) / (Number of Observations - Effective Parameters)
- Validate Estimates: Check that the estimated variances align with experimental expectations and show appropriate patterns relative to experimental conditions.
Applications: This protocol is particularly valuable in oceanographic data processing, bioprocess optimization, and any experimental context where measurement precision varies systematically [32].
Protocol 2: Implementing Weighted Cost Functions in DBTL Analytics
Purpose: To incorporate heteroscedastic noise variances into the learning phase of DBTL cycles for more robust parameter estimation.
Materials:
- Noise variance estimates from Protocol 1
- DBTL platform with customizable analytics module
- Experimental data from Build and Test phases
Procedure:
- Assign Weights: Calculate weights for each data point as the inverse of its estimated variance.
- Modify Cost Function: Implement a weighted least squares cost function where each squared residual is multiplied by its corresponding weight.
- Parameter Optimization: Optimize model parameters by minimizing the weighted cost function.
- Uncertainty Quantification: Calculate parameter uncertainties using the weighted covariance matrix.
- Iterative Refinement: Use the updated model to generate new residuals and refine variance estimates if necessary.
Applications: Essential for autonomous DBTL platforms optimizing protein expression, metabolite production, or growth conditions in synthetic biology [28] [33].
Table 1: Heteroscedastic Noise Estimation Methods Comparison
| Method | Requirements | Advantages | Limitations | Suitable For |
|---|---|---|---|---|
| Replicate Measurements | Multiple measurements at same conditions | Direct variance estimation | Expensive, not always available | All experimental types |
| Parametric Variance Function | Known functional form of variance | Efficient use of data | Requires correct model specification | Systems with well-characterized noise |
| Residual Grouping | Data subsets with constant variance | No replicates needed, handles model errors | Requires sufficient data per group | DBTL cycles, biological optimization |
Table 2: Impact of Proper Noise Handling in DBTL Applications
| Application | Benefit of Heteroscedastic Noise Modeling | Implementation Approach | Result |
|---|---|---|---|
| Flavonoid production in E. coli [33] | More reliable identification of significant factors | Statistical analysis of production data | 500-fold improvement in (2S)-pinocembrin production |
| Automated cultivation optimization [28] | Better selection of next measurement points | Machine learning with noise-aware cost functions | Improved convergence to optimal inducer concentrations |
| Oceanographic data processing [32] | Accurate parameter uncertainties | Grouped variance estimation from residuals | Detection of systematic errors in measurements |
Research Reagent Solutions
Table 3: Essential Materials for Noise-Aware Biological Experiments
| Item | Function | Application Notes |
|---|---|---|
| Microtiter Plates | High-throughput cultivation | Enable parallel testing of multiple conditions; essential for variance estimation |
| Automated Liquid Handlers | Precise reagent delivery | Reduce technical variability; improve reproducibility |
| Plate Readers with OD600 and fluorescence | Biomass and protein production measurement | Critical for collecting quantitative data in DBTL cycles |
| DNA Parts Libraries | Pathway construction | Standardized parts facilitate modular experimental design |
| Inducer Compounds (e.g., IPTG, lactose) | Regulation of gene expression | Key factors in optimization of protein production pathways |
| Statistical Software (R, Python) | Data analysis and noise modeling | Implement weighted regression and variance estimation |
Workflow Diagrams
Dot Script: Heteroscedastic Noise Estimation Workflow
Dot Script: Autonomous DBTL Cycle with Noise Handling
Frequently Asked Questions (FAQs)
Q1: What is the core function of the Expected Improvement (EI) acquisition function in a noisy experimental setting?
EI is designed to balance the trade-off between exploration (sampling from uncertain regions) and exploitation (sampling near the current best-known value) when optimizing a black-box function. It calculates the expected value of improvement over the current best observation, naturally taking into account the prediction uncertainty from the surrogate model (like a Gaussian Process). This makes it particularly suited for noisy, expensive-to-evaluate functions common in biological experiments, as it does not just consider the probability of improvement, but the magnitude of a potential improvement as well [34].
Q2: My Bayesian Optimization (BO) with EI is converging slowly. What could be wrong?
Slow convergence can often be attributed to these common issues:
- Incorrect Kernel Choice: The kernel (covariance function) of your Gaussian Process must match the smoothness and patterns of your underlying biological system. A standard Radial Basis Function (RBF) kernel assumes smooth, continuous functions. If your response is erratic, a Matern kernel might be more appropriate [15].
- Excessive Noise: If your experimental noise (e.g., from biological variability or measurement error) is high, it can overwhelm the signal. Consider using a Gaussian Process with a dedicated noise term or a heteroscedastic noise model to better capture non-constant uncertainty [15].
- Poor Initial Design: BO is sensitive to the initial set of points. Ensure you start with a space-filling design (e.g., Latin Hypercube Sampling) to build a reasonable initial surrogate model before letting EI take over.
Q3: How can I make the EI algorithm more or less exploratory?
The explorative nature of EI is intrinsic, but you can influence it:
EI is defined as: EI(x) = σ(x) [s Φ(s) + φ(s)], where s = (μ(x) - f(x⁺)) / σ(x) [34].
In this equation, σ(x) (the uncertainty) directly controls exploration. You cannot directly set an exploration parameter in standard EI. For more exploration, consider using the Upper Confidence Bound (UCB) acquisition function, which has an explicit parameter κ to control the exploration-exploitation balance: UCB(x) = μ(x) + κσ(x) [15] [35].
Troubleshooting Guide: Expected Improvement
| Symptom | Potential Cause | Recommended Solution |
|---|---|---|
| Slow convergence | Inappropriate kernel choice | Switch from RBF to Matern kernel for less smooth landscapes [15]. |
| High experimental noise | Incorporate a heteroscedastic noise model into your Gaussian Process [15]. | |
| Convergence to local optimum | Over-exploitation | Ensure initial design is space-filling; consider a meta-algorithm that restarts from random points. |
| Poor model prediction | Sparse initial data | Increase the number of points in your initial Design of Experiments (DoE) before starting the BO loop [4]. |
| Unstable recommendations | High noise corrupting the signal | Increase the number of technical replicates at each condition to obtain a more reliable mean and variance estimate [15]. |
Experimental Protocol: Implementing an EI-driven DBTL Cycle
This protocol outlines how to integrate the Expected Improvement algorithm into an automated Design-Build-Test-Learn (DBTL) cycle for optimizing a biological system, such as protein production in a bioreactor [4].
1. Objective Definition:
- Define your input variables (e.g., inducer concentration, temperature, feed rate) and their feasible ranges.
- Define your objective function to maximize or minimize (e.g., GFP fluorescence, product titer, yield).
2. Initial Experimental Design:
- Perform an initial space-filling experimental design (e.g., Latin Hypercube) across your input variables. A minimum of 10 points is recommended to build an initial model.
- Execute these experiments and record the results.
3. Model Training and Point Selection:
- Learn: Train a Gaussian Process (GP) surrogate model on all data collected so far. Use a Matern kernel and a white noise kernel to account for experimental noise.
- Design: Apply the Expected Improvement acquisition function to the GP posterior.
- Identify the next point(s) to evaluate by finding the input configuration that maximizes EI.
4. Automated Execution:
- Build & Test: A robotic platform prepares the new culture conditions and runs the experiments [4].
- The results (e.g., from a plate reader) are automatically fed back into the database.
5. Iteration:
- Repeat steps 3 and 4 until a convergence criterion is met (e.g., a pre-defined number of cycles, or minimal improvement over several cycles).
Workflow Visualization
Expected Improvement Calculation Logic
Table 1: Key Parameters for Expected Improvement Implementation
| Parameter | Symbol | Typical Value / Range | Description |
|---|---|---|---|
| Current Best Value | f(x⁺) |
- | The highest objective function value observed so far. |
| Prediction Mean | μ(x) |
- | The Gaussian Process prediction at point x. |
| Prediction Std. Dev. | σ(x) |
- | The standard deviation (uncertainty) of the prediction at x. |
| Standardized Score | s |
- | s = (μ(x) - f(x⁺)) / σ(x); number of standard deviations the prediction is above the current best [34]. |
| Cumulative Dist. Func. | Φ(s) |
0 to 1 | Probability that a standard normal variable is less than s [34]. |
| Probability Dens. Func. | φ(s) |
≥ 0 | The height of the standard normal distribution at s [34]. |
Table 2: Performance Comparison of Optimization Algorithms in Biological Case Studies
| Algorithm / Study | Problem Dimension | Experiments to Converge | Key Outcome |
|---|---|---|---|
| Bayesian Optimization (EI) [15] | 4 (Transcriptional control) | ~18 | Converged to near-optimum in 22% of the experiments required by a grid search (83 experiments). |
| Grid Search [15] | 4 (Transcriptional control) | 83 | Exhaustively screened all combinations; guaranteed but highly inefficient. |
| Active Learning [34] | 1 (Gold mining) | N/A | Focused on model accuracy, not optimization; slower at finding the maximum. |
| Autonomous DBTL [4] | 2 (Inducer & feed) | 4 cycles | Successfully optimized GFP production using a robotic platform in a fully closed loop. |
The Scientist's Toolkit: Research Reagent Solutions
| Reagent / Material | Function in Experiment |
|---|---|
| Inducers (e.g., IPTG, Naringenin) | Molecules used to trigger expression of a target gene or pathway in a synthetic biological system [15]. |
| Reporter Proteins (e.g., GFP) | Easily measurable proteins (via fluorescence) that serve as a proxy for the performance of the system being optimized [4]. |
| Marionette-wild E. coli Strain | A specialized chassis organism with genomically integrated, orthogonal inducible transcription factors, ideal for high-dimensional optimization [15]. |
| Microtiter Plates (MTPs) | Standardized plates (e.g., 96-well) for high-throughput cultivation and measurement of many experimental conditions in parallel [4]. |
| Gaussian Process Software | Core computational tool for building the surrogate model; requires selection of a kernel (e.g., Matern) and noise model [15]. |
Troubleshooting Guides
Data-Related Issues
Problem: Experimental noise is corrupting my ML model training, leading to poor performance in the next DBTL cycle.
| Symptom | Possible Cause | Solution | Verification Method |
|---|---|---|---|
| High variance in model predictions between DBTL cycles [16] | High stochasticity in cell-free expression or assay results [17] | Implement Z-score normalization of raw data; use Gaussian Process models with RBF kernels to capture and filter noise [16] [36] | Check model R² score on validation set (target: >0.95, as achieved in iBioFAB kinetic models) [16] |
| ML model fails to converge or shows unstable learning [16] | Small, noisy dataset from initial DBTL rounds [37] | Employ "low-N" machine learning models specifically designed for small data settings; use ensemble methods like Random Forest Regression (with 100 trees) [36] | Monitor bootstrap stability analysis; reliable genes should have a selection rate >80% across iterations [16] |
| Discrepancy between predicted and actual variant fitness [36] | Assay measurement error or bias | Incorporate Bayesian optimization with Upper Confidence Bound (UCB) acquisition functions to balance exploration and exploitation [16] | Compare predicted vs. experimental OD values (successful implementation showed best OD=0.401 vs. predicted 0.408-0.424) [16] |
Problem: Inefficient communication between the ML and robotics layers is slowing down the DBTL cycle.
| Symptom | Possible Cause | Solution | Verification Method |
|---|---|---|---|
| Robotic platform halts awaiting ML design input [37] | Slow inference time of complex models (e.g., Hypergraph Neural Networks) [16] | Pre-compute initial variant libraries using unsupervised models (ESM-2, EVmutation) to ensure a constant workflow feed [36] [37] | Confirm successful construction of 180 initial variants for two distinct enzymes [36] |
| Data format from robotic assay is incompatible with ML training script | Lack of standardized data schema | Develop automated data parsers that transform instrument output (e.g., plate reader data) into structured CSV files for ML consumption [16] | Run an end-to-end test with a single 96-well plate to ensure data flows from "Test" to "Learn" phase without error [36] |
Hardware & Workflow Integration Issues
Problem: The physical 'Build' and 'Test' processes are introducing error and variability.
| Symptom | Possible Cause | Solution | Verification Method |
|---|---|---|---|
| Low assembly fidelity in variant construction [36] | Error-prone site-directed mutagenesis (SDM) | Replace standard SDM with a high-fidelity, HiFi-assembly based mutagenesis method [36] | Sequence random mutants; target ~95% accuracy, as achieved in the iBioFAB platform [36] |
| Low protein expression yield in high-throughput system [36] | Metabolic burden on host cells in automated culturing | Shift to cell-free transcription-translation (TX-TL) systems for rapid, decoupled protein production and testing [17] | Measure protein expression levels within hours; compare consistency with cell-based systems [17] |
| Contamination or cross-contamination in automated runs | Liquid handling robot calibration drift | Implement a module for automated calibration and scheduling of liquid handlers using integrated software (e.g., Thermo Momentum) [36] | Schedule routine runs with control samples to track pipetting accuracy and contamination rates. |
Frequently Asked Questions (FAQs)
Q1: What is the most effective way to start an autonomous engineering campaign for a new enzyme with no prior experimental data? The most successful approach uses unsupervised protein models to design the initial library. Provide only the wild-type protein sequence to a protein Large Language Model (LLM) like ESM-2 and an epistasis model like EVmutation. These models, trained on evolutionary data, will generate a list of initial variants (e.g., 180) with a high probability of success, with over 50% often performing above the wild-type baseline [36] [37].
Q2: How can I make my DBTL cycle faster and more resilient to failure? Adopt two key strategies:
- Modularize your automated workflow: Divide the end-to-end process into 7+ distinct, automated modules (e.g., mutagenesis PCR, transformation, assay). This allows you to troubleshoot or restart individual modules without halting the entire pipeline [36].
- Eliminate bottlenecks: Implement a high-fidelity DNA assembly method that does not require intermediate sequence verification, creating a continuous and uninterrupted workflow [36].
Q3: Our wet-lab experimental data is inherently noisy. How can we prevent this from corrupting the AI models? Handle noise through model choice and data processing:
- Use robust models: Gaussian Processes are excellent for modeling noisy experimental data and quantifying uncertainty [16].
- Leverage active learning: Use acquisition functions like Upper Confidence Bound (UCB) that explicitly explore uncertain regions, turning noise into a guide for exploration [16].
- Normalize data: Apply techniques like Z-score normalization to eliminate scale effects and reduce the impact of outlier measurements [16].
Q4: We have limited resources and cannot screen thousands of variants. What is a good strategy? Focus on data efficiency. A combined initial design and iterative ML strategy is highly effective. Start with a smart, LLM-designed library of ~200 variants. Use the data from this small set to train a "low-N" machine learning model. This model can then predict higher-order combinations, allowing you to find significantly improved variants (e.g., 16- to 26-fold activity increase) by screening fewer than 500 total variants [36] [37].
Q5: The DBTL cycle is a core concept, but is there a more efficient alternative? Emerging research suggests a reordering to LDBT (Learn-Design-Build-Test). This paradigm uses machine learning on existing data first to create a predictive model. You then Design and Build only the most promising candidates predicted by the model, and Test them rapidly in a cell-free system. This "learn-first" approach can dramatically reduce the number of costly build-and-test cycles [17].
Quantitative Performance Data
The following table summarizes key performance metrics from a state-of-the-art autonomous platform, serving as a benchmark for your own implementations.
Table 1: Performance Benchmarks of an AI-Powered Autonomous Enzyme Engineering Platform [36] [37]
| Metric | AtHMT (Halide Methyltransferase) | YmPhytase | General Workflow |
|---|---|---|---|
| Engineering Goal | Improve ethyltransferase activity | Improve activity at neutral pH | N/A |
| Number of DBTL Cycles | 4 | 4 | 4 |
| Total Time | 4 weeks | 4 weeks | 4 weeks |
| Total Variants Screened | < 500 | < 500 | < 500 per enzyme |
| Best Result | 16-fold increase in ethyltransferase activity; 90-fold shift in substrate preference | 26-fold increase in specific activity at neutral pH | N/A |
| Initial Library Success | 59.6% of variants above wild-type baseline [36] | 55% of variants above wild-type baseline [36] | Designed using ESM-2 & EVmutation |
Experimental Protocols
Core Protocol: Automated DBTL Cycle for Enzyme Engineering
This protocol details the end-to-end workflow for autonomous enzyme optimization, as implemented on the iBioFAB.
I. Design Phase
- Input: Provide the wild-type amino acid sequence of the target enzyme.
- Initial Library Design: Use a pre-trained protein LLM (ESM-2) and an epistasis model (EVmutation) to generate a list of ~180 single-point mutations ranked by predicted fitness [36] [37].
- Iterative Design: In subsequent cycles, feed experimental data into a supervised machine learning model (e.g., Low-N regression) to design higher-order mutant combinations.
II. Build Phase (Automated on iBioFAB)
- HiFi-Assembly Mutagenesis: Perform mutagenesis PCR using a high-fidelity assembly method instead of traditional SDM. This eliminates the need for intermediate sequencing.
- Primer Design: Design primers for the initial single mutants. Most higher-order mutants can be built from these without new primers.
- Assembly: Use automated liquid handling for PCR assembly and DpnI digestion to remove the template [36].
- Transformation: Automate the transformation of the assembled DNA into a microbial host (e.g., E. coli) plated on 96-well format omnitray LB plates [36].
- Colony Picking & Plasmid Purification: Use a robotic arm to pick colonies and proceed to automated plasmid purification.
III. Test Phase (Automated on iBioFAB)
- Protein Expression: Induce protein expression in a 96-well deep-well plate.
- Cell Lysis: Perform crude cell lysate removal automatically.
- Functional Enzyme Assay: Run a high-throughput, automation-friendly assay (e.g., colorimetric or fluorometric activity assay) in a plate reader. The specific assay must be quantifiable and relevant to the engineering goal (e.g., methyltransferase activity for AtHMT, phosphatase activity at specific pH for YmPhytase) [36].
IV. Learn Phase
- Data Aggregation: Automatically compile variant sequences and their corresponding assayed fitness values into a structured dataset.
- Model Training / Retraining: Use this dataset to train or update the supervised machine learning model for the next Design phase.
- Hypothesis Generation: The model identifies sequence-function relationships and proposes the next set of variants to test [36] [37].
Workflow Visualization
The Scientist's Toolkit: Essential Research Reagents & Materials
Table 2: Key Reagents and Materials for Autonomous Enzyme Engineering
| Item | Function / Explanation | Example / Specification |
|---|---|---|
| Pre-trained Protein LLMs | Unsupervised models used to design high-quality initial variant libraries without prior experimental data. | ESM-2 (Evolutionary Scale Modeling) [36] [37] |
| Epistasis Model | Computes the effect of mutations by analyzing co-evolution in protein families, complementing the LLM. | EVmutation [36] [37] |
| HiFi DNA Assembly Mix | High-fidelity enzyme mix for accurate assembly of DNA fragments during mutagenesis, crucial for automation. | Commercial kits (e.g., NEB HiFi DNA Assembly Mix) adapted for automated pipetting [36] |
| Cell-Free TX-TL System | A transcription-translation system for rapid protein synthesis without living cells, accelerating the "Test" phase. | Commercially available cell-free kits, implemented in a 96-well format [17] |
| Automated Liquid Handler | Robotic system to perform pipetting, plate transfers, and other repetitive liquid handling tasks. | Integrated systems (e.g., via Thermo Momentum software) with a central robotic arm [36] |
| Microplate Reader | Instrument for high-throughput quantification of enzyme activity assays (e.g., absorbance, fluorescence). | Capable of reading 96- or 384-well plates, integrated with the robotic platform [36] |
Optimizing DBTL Workflows: Strategies for Error Control and Enhanced Replicability
Design of Experiments (DoE) for Efficient Exploration and Noise Resilience
FAQs: Core Concepts and Application
What is the primary goal of using DoE in a research setting?
The primary goal of Design of Experiments (DoE) is to systematically investigate multiple input variables (factors) simultaneously to understand their effect on output variables (responses). This approach allows researchers to identify optimal conditions, reduce process variability, and understand complex interactions between factors, all while using resources efficiently [38] [39]. It moves beyond inefficient one-factor-at-a-time (OFAT) methods [40].
How does DoE provide resilience against experimental noise?
DoE enhances noise resilience through specific strategies aimed at making the process or product insensitive to uncontrollable variations. Key methods include:
- Incorporating Noise Factors: Deliberately including uncontrollable variables (noise) in the experimental design to find factor settings that minimize the output's sensitivity to them [41].
- Blocking: Grouping experimental runs to account for known sources of nuisance variation (e.g., different environmental chambers or days) [41].
- Randomization: Randomly assigning the order of experimental runs to mitigate the effects of lurking variables and minimize systematic bias [41].
- Signal-to-Noise Ratios: Using Taguchi's S/N ratios as a metric to find factor levels that maximize the desired signal while minimizing the effect of noise [41] [42].
When should I use a screening design versus an optimization design?
The choice depends on your experimental goal and the current level of process understanding, typically following a sequential approach:
| Design Purpose | When to Use | Common Design Types |
|---|---|---|
| Screening | Early phase; identifying the few critical factors from many potential candidates [38]. | Fractional Factorial, Plackett-Burman [38] [40]. |
| Optimization | After critical factors are known; finding the optimal settings and understanding response surfaces [38]. | Response Surface Methodology (RSM), Full Factorial, D-Optimal designs [38] [42]. |
What are the key steps for implementing a DoE?
A successful DoE implementation follows a structured workflow [38] [39]:
- Define the Problem: Clearly state the objective and identify measurable responses.
- Identify Factors: Select the key input variables (factors) and their levels to be tested.
- Select the Design: Choose an appropriate experimental design (e.g., Full Factorial, Fractional Factorial, RSM) based on the objective and resources.
- Execute the Experiment: Run the tests as per the design matrix, using randomization where possible.
- Analyze the Data: Use statistical methods (like ANOVA) to identify significant factors and interactions.
- Interpret and Validate: Draw conclusions from the analysis and perform confirmation runs to verify the optimal settings.
Troubleshooting Guides
Problem 1: High Variation in Responses Repeating the Same Experimental Condition
Potential Cause: Uncontrolled noise factors are significantly influencing the process.
Solution Strategy:
- Identify and Control: List all potential sources of noise (e.g., environmental humidity, operator differences, reagent batches) [43] [44].
- Implement Blocking: If a noise factor cannot be controlled (e.g., testing over multiple days), use it as a blocking variable in your design. This isolates its effect from the factors you are studying [41].
- Use Randomization: Randomize the order of all experimental runs to distribute the effect of unanticipated noise factors evenly across all treatments [41].
- Increase Replication: Run more replicates for each treatment combination to get a better estimate of the pure experimental error, which helps in validating the significance of your factors [40].
Problem 2: The Model Fits Poorly or Fails to Predict Accurately
Potential Cause: Important interactions between factors were not captured by the experimental design, or the design space was too narrow.
Solution Strategy:
- Check for Interactions: Use statistical software to create interaction plots. A poor model often indicates significant interaction effects are present but not accounted for [41] [40].
- Change the Design: If a screening design (e.g., highly fractional factorial) was used, it may have confounded (aliased) interactions with main effects. Switch to a design with higher resolution, such as a Full Factorial or a less-fractionated design, to de-alias these effects [40].
- Expand the Design Space: The relationship between factors and the response might be non-linear. Consider augmenting your design with axial points to create a Response Surface Methodology (RSM) design, which can model curvature [42].
Potential Cause: A full factorial design would require an impractical number of experimental runs.
Solution Strategy:
- Use a Screening Design: Start with a Fractional Factorial or Plackett-Burman design. These designs efficiently identify the "vital few" factors from the "trivial many" with a minimal number of runs [38] [40].
- Employ D-Optimal Designs: For situations with irregular experimental regions or complex constraints, D-optimal designs can be used to select the set of runs that provides the most information for estimating model parameters with minimal variance [41] [42].
- Leverage Bayesian Optimization: For very complex, resource-intensive "black box" biological systems, Bayesian Optimization can be a highly sample-efficient strategy. It uses a probabilistic model to intelligently select the next most informative experiment, converging on an optimum with far fewer runs than traditional methods [15].
The table below compares key characteristics of different experimental designs to help in selection [38] [40] [42].
| Design Type | Number of Runs (Example: k=5 factors, 2 levels) | Primary Use | Pros | Cons |
|---|---|---|---|---|
| Full Factorial | 2⁵ = 32 | Understanding all main effects and interactions. | Captures all interaction information. | Number of runs becomes prohibitive with many factors. |
| Fractional Factorial | 2⁽⁵⁻¹⁾ = 16 (½ fraction) | Screening; identifying vital factors. | Highly efficient; reduces runs significantly. | Some interactions are confounded (aliased). |
| Plackett-Burman | 12+ | Screening many factors with very few runs. | Very high efficiency for main effects screening. | Cannot estimate interactions; main effects may be biased. |
| Response Surface | Varies (e.g., 26 for CCD) | Optimization; modeling non-linear (quadratic) effects. | Models curvature to find a true optimum. | Requires more runs than screening designs. |
| D-Optimal | User-defined (e.g., 15) | Optimizing parameter estimates with constraints. | Flexible for unusual constraints and adding runs. | Design is optimal for a specific pre-defined model. |
| Taguchi | Varies (e.g., L8: 8 runs) | Robust parameter design; minimizing effect of noise. | Strong focus on reducing performance variation. | Complex interactions may be overlooked. |
Experimental Protocol: A Screening and Optimization Workflow
This protocol outlines a sequential DoE approach for a biopharmaceutical process, such as optimizing a cell culture media formulation.
Phase 1: Screening with a Fractional Factorial Design
- Objective: Identify which of 5 media components (e.g., Glucose, Glutamine, Growth Factor, NaCl, Trace Elements) significantly affect cell density (OD600).
- Design Selection: A 2⁽⁵⁻¹⁾ fractional factorial design (Resolution V) is selected. This requires 16 runs and allows estimation of all main effects and two-factor interactions without confounding [40].
- Execution: Prepare media according to the 16 combinations specified by the design matrix. Inoculate with cells and measure OD600 after 48 hours.
- Analysis: Perform ANOVA on the results. The analysis identifies Glucose, Glutamine, and Growth Factor as the three statistically significant factors.
Phase 2: Optimization with a Response Surface Design
- Objective: Find the optimal concentrations of the three significant factors (Glucose, Glutamine, Growth Factor) to maximize cell density.
- Design Selection: A Central Composite Design (CCD) is chosen, requiring 20 runs (8 factorial points, 6 axial points, 6 center points) [42].
- Execution: Run the 20 experiments as per the CCD matrix.
- Analysis: Fit a quadratic model to the data. The model provides a response surface equation that predicts cell density for any combination of the three factors within the tested range. The optimum concentration is identified from the model and confirmed with validation runs.
DoE Workflow Integration in the DBTL Cycle
The following diagram illustrates how a robust DoE process is integrated within the Design-Build-Test-Learn (DBTL) cycle for continuous improvement.
The Scientist's Toolkit: Essential Research Reagent Solutions
This table lists key materials and their functions relevant to DoE in a biopharmaceutical or drug development context.
| Item | Function in Experimentation |
|---|---|
| Orthogonal Array (Taguchi) | A pre-determined set of experiments to efficiently study a large number of factors with a minimal number of runs, focusing on robustness [40]. |
| D-Optimal Design Software | Algorithmically selects the most informative set of experimental runs from a candidate set, ideal for constrained or non-standard design spaces [41] [42]. |
| Non-Contact Dispensing System | Enables highly accurate and precise liquid handling for setting up complex assay plates, minimizing human error and ensuring reproducibility in DoE workflows [45]. |
| Bayesian Optimization Framework | A no-code or modular software tool that uses Gaussian processes and acquisition functions to guide the sequential optimization of expensive "black-box" biological experiments [15]. |
| Institutional Review Board (IRB) | A formally designated group that reviews and monitors biomedical research involving human subjects to ensure ethical standards and protect participant welfare [46]. |
FAQs: Automation and Replicability in the DBTL Cycle
Q1: How does automation specifically reduce variability in the "Test" phase of the DBTL cycle? Automation enhances reproducibility by standardizing workflows and minimizing human-induced variability. Robotic systems perform repetitive tasks with high precision, reducing errors and inconsistencies that can arise from manual fatigue or subtle protocol deviations between different researchers [47] [48]. In automated gene expression microarray experiments, this results in a significantly higher correlation between replicates (e.g., Spearman correlation of 0.92 in automated vs. 0.86 in manual protocols), directly increasing the statistical power to detect differentially expressed genes [49].
Q2: What are common automation failures that can introduce noise into DBTL cycle data? Common failures include damaged or misaligned equipment, integration issues between legacy and new automation systems, and power failures [50]. Furthermore, human error, such as incorrect sample labeling, erroneous software commands, or sample contamination during manual transfer steps, remains a significant source of problems, even within an automated workflow [50].
Q3: How can machine learning (ML) be integrated into an automated DBTL cycle to improve learning? ML models, such as gradient boosting and random forest, can learn from the data generated in the "Test" phase to predict high-performing strain designs for the next "Design" cycle [10] [20]. A mechanistic kinetic model-based framework shows these models are particularly effective in the low-data regime typical of early DBTL cycles and are robust to training set biases and experimental noise [10]. An automated recommendation algorithm can then use these predictions to suggest new designs, optimizing the cycle's efficiency [10].
Q4: What is the impact of automated liquid handling on data reproducibility? Automated liquid handlers drastically improve reproducibility by dispensing precise, miniaturized volumes, which reduces reagent consumption and costs by up to 90% [51]. Technologies like non-contact dispensing with integrated volume verification (e.g., DropDetection) identify and document dispensing errors in real-time, allowing for immediate correction and ensuring data reliability [51]. This is crucial for generating consistent, high-quality data in high-throughput screening (HTS) [51].
Q5: How does automation assist in managing data for reproducible DBTL cycles? Automation software, such as a Laboratory Information Management System (LIMS), is critical for post-analytical data integrity [52]. It automates data workflows, integrates instruments, and manages sample-associated data and metadata [52]. By automatically streaming results from equipment to the LIMS, it eliminates manual transcription errors, provides a robust audit trail, and ensures full traceability for each sample, which is essential for replicability and regulatory compliance [52] [47] [53].
Troubleshooting Guides
Guide 1: Addressing High Variability in Automated Assay Results
Problem: High well-to-well or plate-to-plate variability in assay results, leading to unreliable data.
| # | Step | Action & Description |
|---|---|---|
| 1 | Define Problem | Quantify variability using statistical measures (e.g., coefficient of variation, Z'-factor). Check if the issue is systematic (affecting entire plates) or random (single wells) [50]. |
| 2 | Inspect Liquid Handler | Verify pipette calibration and tip integrity. For non-contact dispensers, use in-built verification tech (e.g., DropDetection) to confirm droplet volume and placement [51]. |
| 3 | Check Reagents | Ensure reagent homogeneity and freshness. Precipitated or degraded reagents are a common source of variability. |
| 4 | Review Protocol | Confirm that incubation times, temperatures, and wash steps are identical between runs. Automated methods should be copied exactly, not re-written [47]. |
| 5 | Consult Logs | Analyze the automation system's activity and error logs for subtle failures or timing issues that may not trigger full alarms [50]. |
Guide 2: Troubleshooting Machine Learning Model Performance in the "Learn" Phase
Problem: ML models trained on "Test" data fail to generate successful designs in the subsequent DBTL cycle.
| # | Step | Action & Description |
|---|---|---|
| 1 | Audit Training Data | Ensure the training data from the "Test" phase is accurate, well-annotated, and free from systematic measurement errors [10]. |
| 2 | Assess Data Bias | Evaluate if the initial library of tested designs covers the design space sufficiently, as biases can limit model extrapolation [10]. |
| 3 | Evaluate Noise Impact | Test model robustness by adding simulated experimental noise to your training data to see if predictions remain stable [10]. |
| 4 | Benchmark Algorithms | Compare different ML methods. Evidence suggests gradient boosting and random forest may outperform others with limited data [10] [20]. |
| 5 | Review Recommendation | Check the algorithm used to select new designs from model predictions. Adjust the balance between exploring new regions and exploiting known high-performing areas [10]. |
Guide 3: Resolving Integration Failures in Automated Workcells
Problem: Individual devices function independently, but the integrated system fails to execute the complete workflow.
| # | Step | Action & Description |
|---|---|---|
| 1 | Identify Failure Point | Run the workflow step-by-step to pinpoint the exact location and nature of the failure (e.g., device not triggering, sample not transferred) [50]. |
| 2 | Check Communication | Verify all physical connections (cables, network) and software communication protocols between devices [50]. |
| 3 | Validate Data Streams | Confirm that the LIMS or orchestrator software (e.g., Automata LINQ Cloud) is correctly sending and receiving commands and data [47] [53]. |
| 4 | Inspect for Damage | Look for damaged components or sensors, especially on robotic arms or mobile robots that are prone to physical wear [50]. |
| 5 | Contact Vendor | If the root cause remains unresolved, contact the automation provider. They can run deep system diagnostics and apply necessary patches or repairs [50]. |
Experimental Protocols & Data
Detailed Methodology: Automated cDNA Synthesis and Labelling for Microarrays
This protocol, adapted from Klevebring et al., demonstrates a fully automated procedure for sample preparation, highlighting steps that minimize human-induced variability [49].
1. Principle: Total RNA is converted to cDNA, purified, and fluorescently labelled on a robotic workstation using superparamagnetic beads for all purification steps. This allows 48 samples to be processed in parallel without manual intervention [49].
2. Key Reagents and Solutions:
- Carboxylic Acid-Coated Paramagnetic Beads: For cDNA purification via precipitation.
- Reverse Transcription Master Mix: Contains reverse transcriptase, buffers, and nucleotides.
- NHS-Modified Fluorophores: For cDNA labelling.
- Ethanol/TEG Buffer: For precipitation in conjunction with magnetic beads.
- Wash Buffer (80% Ethanol): To remove unincorporated fluorophores.
3. Equipment:
- Robotic workstation capable of handling magnetic beads (e.g., Bravo or similar).
- Microtiter plates (96-well or 384-well).
- Magnetic plate holder.
- Thermocycler or temperature-controlled deck for incubations.
4. Step-by-Step Procedure: 1. cDNA Synthesis: The robotic system dispenses total RNA and reverse transcription master mix into a microtiter plate. The plate is incubated for 2 hours (e.g., on a heated deck). 2. First Purification (Post-Synthesis): * Binding: The robot adds paramagnetic beads in an ethanol/TEG buffer to the cDNA to precipitate it. * Capture: A magnet is engaged to capture the bead-bound cDNA. * Washing: The supernatant is removed, and the bead pellet is automatically washed five times with 80% ethanol to ensure purity. * Elution: cDNA is eluted in a low-salt buffer (e.g., water). A "double capture" method is used: after the first elution, beads are returned to the supernatant to capture any residual cDNA, increasing yield by approximately 15% [49]. 3. Labelling: The purified cDNA is mixed with NHS-ester fluorescent dyes in a labelling reaction. 4. Second Purification (Post-Labelling): The purification steps (binding, capture, washing, elution) are repeated identically to remove free, unincorporated fluorophores. The five washes are critical here to minimize background fluorescence [49]. 5. Quality Control & Hybridization: The robot transfers the labelled and purified cDNA for quantification and subsequent microarray hybridization.
5. Quantitative Data on Performance: The table below summarizes the performance gains of the automated protocol compared to a manual one, using the MAQC reference dataset [49].
| Metric | Manual Protocol (KTHMan) | Automated Protocol (KTHAuto) | Improvement & Significance |
|---|---|---|---|
| Median Spearman Correlation (replicates) | 0.86 | 0.92 | ↑ 7% increase in correlation, indicating higher reproducibility [49]. |
| Common DEGs (Top 200) | 155 (77.5%) between NCI3 & NCI4 platforms | 175 (87.5%) between KTHAuto1 & KTHAuto2 | ↑ 10% more genes in common, indicating more reliable detection [49]. |
| Inter-experiment Correlation | 0.94 (highest between NCI runs) | 0.97 (between KTH Auto experiments) | ↑ Higher consistency, allowing data from different cycles to be combined [49]. |
| Throughput | 24 reactions in ~5 hours | 48 reactions in ~5 hours | ↑ 100% increase in throughput with similar hands-on time [49]. |
The Scientist's Toolkit: Key Research Reagent Solutions
| Item | Function in Experimental Replicability |
|---|---|
| Paramagnetic Beads (Carboxylic Acid-coated) | Automated nucleic acid purification. Their use in an automated "double capture" protocol increases cDNA yield by ~15%, enhancing data consistency [49]. |
| Non-Contact Liquid Handler | Dispenses nano- to microliter volumes without cross-contamination. Integrated droplet verification technology confirms dispense accuracy, a major source of variability [51]. |
| Laboratory Information Management System (LIMS) | Manages samples and associated metadata automatically. Eliminates data transcription errors and provides a full audit trail, which is critical for replicability [52] [53]. |
| Electronic Lab Notebook (ELN) | Digitizes experimental documentation. Facilitates standardized protocol sharing and ensures all researchers use the same precise methods [52]. |
| Defined DNA Library Parts (Promoters, RBS) | Provides standardized, quantifiable genetic elements for combinatorial pathway optimization in DBTL cycles, ensuring that "Design" inputs are consistent and well-defined [10]. |
Workflow Diagrams
Automated DBTL Cycle for Metabolic Engineering
Automation Troubleshooting Logic Flow
Data Handling and Preprocessing Pipelines for Noise Mitigation
Frequently Asked Questions
FAQ 1: What are the most common root causes of noise in experimental data within the DBTL cycle? Noise in DBTL cycles often originates from two main areas: biological complexity and physical experimental processes. Biological systems exhibit intrinsic non-linear, high-dimensional interactions between genetic parts and host cell machinery, which can lead to unpredictable outcomes and obscure true signals in data [54]. From an experimental setup perspective, improper calibration of equipment, such as incorrect preload adjustment in linear guides used in automated systems, is a documented cause of abnormal noise and vibration, which can introduce variability into measurements [55].
FAQ 2: What strategies can reduce noise during the "Build" and "Test" phases? During the "Build" phase, employing high-fidelity DNA synthesis and precise genome editing technologies (e.g., CRISPR-Cas9) can minimize construction errors that contribute to biological noise [54]. In the "Test" phase, implementing high-throughput sequencing and robust analytical assays helps generate more reliable and reproducible data. Furthermore, controlling the physical lab environment—such as ensuring the flatness of installation surfaces for robotic equipment to prevent resonance—can reduce mechanically induced noise [55].
FAQ 3: How can machine learning models be designed to be robust against noisy data? Certain machine learning algorithms are inherently more robust in low-data, high-noise regimes. For instance, gradient boosting and random forest models have been shown to outperform other methods under these conditions due to their ability to capture complex patterns without overfitting easily [10]. It is also crucial to use large, well-characterized initial datasets for the first DBTL cycle to provide a solid foundation for the model to learn from, making it more resilient to noise in subsequent cycles [10].
FAQ 4: What are the best practices for preprocessing data to mitigate noise before analysis? A key practice is the strategic integration of data from multiple cycles. Using data from previous DBTL iterations allows models to learn from a broader set of experiments, helping to distinguish between consistent signals and one-off noise events [10]. For visual data representations, ensuring high color contrast (a minimum ratio of 3:1 for graphical objects) in charts and graphs prevents misinterpretation and enhances accessibility, which is a form of noise reduction for the end-user [56] [57].
Troubleshooting Guides
Issue 1: High Variation in Replicate Measurements This is often a symptom of noise originating from the experimental protocol or equipment.
- Step 1: Verify Instrument Calibration. Check and recalibrate all measurement devices, including spectrophotometers, liquid handlers, and plate readers. Follow manufacturer guidelines precisely.
- Step 2: Review Sample Handling. Ensure consistent sample preparation, storage, and loading techniques across all replicates. Automated liquid handlers can minimize human-induced variation.
- Step 3: Audit Environmental Controls. Monitor and record conditions like temperature and humidity in the lab, as fluctuations can affect biological and chemical assays.
- Step 4: Implement Controls. Include positive and negative controls in every experiment batch. High variation in these controls indicates a systemic issue that needs addressing before analyzing experimental data.
Issue 2: Machine Learning Models Performing Poorly on New DBTL Cycles This suggests the model is overfitting to noisy data or failing to generalize.
- Step 1: Analyze Error Patterns. Examine whether prediction errors are random or systematic. Systematic errors may indicate an unaccounted-for variable or bias in the training data.
- Step 2: Expand Feature Space. Incorporate additional relevant data, such as multi-omics data (e.g., transcriptomics, proteomics), to provide more context and help the model isolate the true signal [54].
- Step 3: Switch or Ensemble Models. Transition to more robust algorithms like gradient boosting or random forests, which are better suited for noisy biological data [10]. Alternatively, create an ensemble of models to improve predictive stability.
- Step 4: Active Learning. Use the model to identify the most informative data points to test in the next DBTL cycle, strategically reducing uncertainty and noise in the subsequent dataset [10].
Issue 3: Inconsistent Experimental Results from Automated Lab Equipment Physical vibration and resonance in equipment can be a source of noise.
- Step 1: Inspect for Mechanical Looseness. Check all bolts, connectors, and moving parts (like linear guides) for proper tightness according to the equipment's maintenance manual [55].
- Step 2: Check Surface Flatness. Use precision tools like laser interferometers or levels to verify the flatness of the equipment's installation surface. An uneven surface can cause resonance and vibration [55].
- Step 3: Adjust Preload. If applicable (e.g., for linear guides), consult the manufacturer's guidelines to fine-tune the preload. Both insufficient and excessive preload can cause instability and noise [55].
- Step 4: Install Damping Accessories. Consider adding viscous or elastic dampers to the equipment frame. These accessories absorb vibrational energy and can reduce noise levels significantly [55].
Experimental Protocols
Protocol 1: Preprocessing High-Throughput Screening Data for Noise Reduction
Objective: To clean and normalize raw data from high-throughput assays (e.g., growth measurements, fluorescence) to minimize technical noise before downstream analysis.
Materials:
- Raw data file (e.g., CSV, TXT) from plate reader or cytometer.
- Statistical software (e.g., R, Python with Pandas).
- Computer workstation.
Methodology:
- Background Subtraction: For each plate or batch, subtract the average value of the negative controls from all experimental wells.
- Normalization: Normalize data to positive controls or plate medians to account for inter-plate variation. A common method is to convert readings to a Z-score or a percentage of the control.
- Outlier Detection: Apply statistical tests (e.g., Grubbs' test) or use interquartile range (IQR) methods to identify and flag technical outliers for review or exclusion.
- Data Transformation: Apply log or Box-Cox transformations to stabilize variance if the data is heavily skewed.
- Batch Effect Correction: If multiple batches were run, use algorithms like Combat or remove principal components associated with batch identity to harmonize the data.
Protocol 2: Establishing a Robust DBTL Cycle for Noisy Systems
Objective: To structure a DBTL cycle that efficiently converges on an optimal solution despite high experimental noise, using a model-guided approach.
Materials:
- DNA part library.
- Host organism (e.g., E. coli).
- Fermentation and analytics equipment.
- Computational resources for modeling (e.g., Python with scikit-learn).
Methodology:
- Initial Design: Build an initial, diverse set of strain designs (e.g., 50+ variants) by combinatorially assembling pathway genes from a predefined DNA library [10].
- Build & Test: Construct strains and measure the performance phenotype (e.g., product titer) in a controlled bioprocess model [10].
- Learn:
- Train a machine learning model (e.g., Gradient Boosting) on the dataset linking genetic designs to performance.
- Use a recommendation algorithm to select the next set of promising designs. This algorithm should balance exploration (testing novel designs) and exploitation (improving on the best ones) [10].
- Iterate: Repeat the Build-Test-Learn steps, using the model's recommendations to guide the design in each new cycle. Research indicates that starting with a larger initial cycle is more effective than spreading the same number of tests evenly across multiple cycles [10].
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function |
|---|---|
| High-Fidelity DNA Polymerase | Reduces errors during PCR and gene assembly, minimizing biological noise at the "Build" stage. |
| Validated Promoter Library | Provides a set of well-characterized genetic parts with known expression strengths, enabling precise control over enzyme levels in combinatorial designs [10]. |
| Multi-Omics Standards | Certified reference materials used to calibrate instruments and normalize data across different omics platforms (genomics, proteomics). |
| Viscous Dampers | Accessories for lab automation equipment that absorb vibrational energy, reducing physically transmitted noise [55]. |
| Standardized Growth Media | Chemically defined media ensures consistent and reproducible cell growth, reducing variability in the "Test" phase. |
Workflow Visualizations
DBTL Cycle with ML Integration
Data Preprocessing Pipeline
Technical Support & Troubleshooting Hub
This guide provides troubleshooting support for researchers implementing autonomous test-learn cycles, focusing on overcoming challenges related to experimental noise and system integration to achieve robust, self-optimizing biological systems.
Frequently Asked Questions (FAQs)
FAQ 1: Our autonomous cycle fails to converge to a stable optimum. The system seems to be chasing noise rather than a true signal. What can we do?
Answer: This is a classic symptom where experimental noise disrupts the learning algorithm's gradient estimation.
- Recommended Action: Implement a Bayesian optimization strategy with explicit noise modeling [15]. This approach uses a Gaussian Process as a probabilistic surrogate model that can distinguish between signal and noise, allowing it to be more robust to experimental variability. Furthermore, ensure your workflow includes adequate technical replicates to better quantify and account for this noise [15].
FAQ 2: How can we effectively balance the exploration of new conditions with the exploitation of known high-performance areas?
Answer: The balance between exploration and exploitation is managed by the acquisition function within a Bayesian optimization framework [15].
- Recommended Action: Select an acquisition function that aligns with your experimental goals. Common choices include Expected Improvement (EI) or Upper Confidence Bound (UCB). You can tune parameters within these functions to adopt a more risk-averse (favoring exploitation) or risk-seeking (favoring exploration) policy [15].
FAQ 3: We are experiencing bottlenecks in data collation and analysis between DBTL cycles, preventing full autonomy. How can this be resolved?
Answer: Manual data handling is a major bottleneck. A fully automated cycle requires a dedicated software framework.
- Recommended Action: Develop or adopt a framework that includes an importer to automatically retrieve measurement data from all devices and write it to a centralized database. This should be coupled with an optimizer module that selects the next experimental points without human intervention [4].
FAQ 4: Our robotic platform executes protocols perfectly, but the autonomous decisions for the next cycle seem suboptimal. Is the issue with the algorithm or the hardware?
Answer: When hardware is confirmed to be functioning, the issue typically lies in the learning algorithm or its configuration.
- Recommended Action: Begin by comparing your chosen learning algorithm against a baseline, such as a random search, to gauge its performance [4]. For complex, high-dimensional problems, ensure you are using an algorithm suited for such landscapes, like Bayesian optimization, which is effective in up to 20 dimensions [15].
Troubleshooting Guide: Common Experimental Issues
| Problem | Possible Cause | Solution |
|---|---|---|
| High data variability between technical replicates. | Inconsistent reagent quality; improper equipment calibration; inherent biological noise [58]. | Use fresh, quality-controlled reagents; implement regular equipment calibration; increase replicate number; use algorithms with heteroscedastic noise modeling [15]. |
| Optimization process gets stuck in a local optimum. | Over-reliance on exploitation; acquisition function not properly tuned [15]. | Adjust acquisition function parameters to favor exploration; consider restarting the optimization from a new, unexplored region of the parameter space. |
| Robotic platform cannot execute the full cycle without human intervention. | Lack of integrated software; disconnected data flow between "Test" and "Learn" phases [4]. | Implement a unified software framework with a scheduler to manage operations and a central database for seamless data transfer [4]. |
| Model predictions do not match experimental results. | Poorly chosen model kernel leading to overfitting or underfitting; insufficient initial data [15]. | Choose or design a kernel that matches the expected smoothness of your biological system; ensure you generate a sufficiently large and reproducible initial dataset [4]. |
Experimental Protocols for Autonomous Test-Learn Cycles
The following section details the core methodologies from published research that successfully established autonomous cycles, providing a template for your own experiments.
Protocol 1: Autonomous Optimization of Bacterial Protein Expression
This protocol is adapted from a study that transformed a static robotic platform into a dynamic one to optimize inducer concentration and feed release in bacterial systems [4].
1. Experimental Overview and Objective
- Primary Goal: To autonomously optimize the expression of a reporter protein (Green Fluorescent Protein, GFP) in Escherichia coli and Bacillus subtilis by dynamically adjusting system parameters over multiple test-learn cycles [4].
- Key Parameters Adjusted: Inducer concentration (e.g., Lactose/IPTG) and amount of enzyme for controlled feed release [4].
- Output Measurements: Fluorescence (GFP production) and cell density (OD600) [4].
2. Required Materials and Equipment
- Biological Materials: E. coli or B. subtilis strains with an inducible GFP construct [4].
- Robotic Platform: A fully integrated system with the following modules [4]:
- Cytomat shake incubator (37°C, 1,000 rpm)
- PheraSTAR FSX plate reader
- CyBio FeliX liquid handling robots (8-channel and 96-channel)
- Robotic arm with gripper for plate transport
- Storage carousels and refrigerated positions (4°C) for reagents
- Software Framework: Custom software for workflow management, including an importer for data retrieval and an optimizer for selecting subsequent measurement points [4].
3. Step-by-Step Workflow
- Step 1 (Test): The robotic system initiates cultivations in a 96-well microtiter plate (MTP). At the appropriate growth phase, it adds inducer and feed enzymes according to an initial set of conditions [4].
- Step 2 (Test): The plate reader periodically measures OD600 and fluorescence. Data is automatically sent to the database [4].
- Step 3 (Learn): The optimizer module analyzes the collected data. Using a learning algorithm (e.g., Bayesian optimization), it balances exploration and exploitation to select the next set of parameter combinations (inducer/feed) that are most likely to improve GFP yield [4].
- Step 4 (Loop): The software updates the protocol for the next cycle. The platform performs a new round of cultivation and induction using the newly chosen parameters, closing the loop without human intervention. This cycle repeats for multiple iterations [4].
Protocol 2: Bayesian Optimization for Metabolic Pathway Tuning
This protocol outlines the use of a Bayesian optimization framework, like BioKernel, for optimizing complex biological systems with limited experimental resources [15].
1. Experimental Overview and Objective
- Primary Goal: To optimize the output of a metabolic pathway (e.g., astaxanthin or limonene production) in a engineered microbial host by tuning the concentrations of multiple inducers [15].
- Key Parameters Adjusted: Concentrations of various pathway inducers (multi-dimensional input space) [15].
- Output Measurements: Quantifiable product titer (e.g., via spectrophotometry for pigments like astaxanthin) [15].
2. Required Materials and Equipment
- Biological Materials: Engineered production strain (e.g., E. coli Marionette strain with a heterologous pathway) [15].
- Standard Lab Equipment: Shake flasks or bioreactors, spectrophotometer.
- Software: Bayesian optimization framework (e.g., BioKernel) with features for heteroscedastic noise modeling and flexible acquisition function selection [15].
3. Step-by-Step Workflow
- Step 1 (Design): Define the parameter bounds for each inducer.
- Step 2 (Build & Test): Conduct cultivation and induction experiments based on an initial set of points or a single initial condition. Measure the final product titer.
- Step 3 (Learn): Input the experimental results into the Bayesian optimization software. The framework will:
- Model the entire optimization landscape using a Gaussian Process (GP), which provides a mean prediction and uncertainty (variance) for every point in the parameter space [15].
- Use an acquisition function (e.g., Expected Improvement) to determine the single most informative set of conditions to test next, balancing the need to explore uncertain regions and exploit promising ones [15].
- Step 4 (Loop): The software outputs the parameters for the next experiment. The cycle repeats, guiding the campaign toward an optimum in far fewer experiments than traditional grid searches [15].
Visualizing the Autonomous Workflow
The following diagram illustrates the fully automated, closed-loop process of an autonomous test-learn cycle.
Diagram 1: Autonomous Test-Learn Cycle Workflow
This flowchart depicts the core logic of a closed-loop DBTL cycle. The process begins with initial parameter definition, leading to automated cultivation and measurement. Data is automatically imported into a central database, which is then processed by a Bayesian Optimizer. The optimizer's decision automatically updates the robotic protocol for the next iteration, creating a continuous loop without human intervention [4] [15].
The Scientist's Toolkit: Research Reagent Solutions
The table below lists key materials and reagents essential for setting up and running autonomous optimization experiments for bacterial systems.
| Item | Function in the Experiment |
|---|---|
| Reporter Strain | A microbial strain (e.g., E. coli, B. subtilis) genetically engineered with a measurable reporter (e.g., GFP) under an inducible promoter. Serves as the biological system under test [4]. |
| Chemical Inducers | Molecules (e.g., IPTG, Lactose) that trigger the expression of the target gene/protein. Their concentration is a primary variable for optimization [4]. |
| Feed Enzymes | Enzymes used to control nutrient release (e.g., glucose from polysaccharides), allowing for dynamic control of growth rates and metabolic activity during cultivation [4]. |
| Microtiter Plates (MTP) | Standardized plates (e.g., 96-well) used for high-throughput, parallel cultivation of bacterial cultures on the robotic platform [4]. |
| Bayesian Optimization Software | Computational framework (e.g., BioKernel) that uses probabilistic models to guide experimental campaigns toward optimal outcomes with minimal resource expenditure [15]. |
FAQs on Model Selection and Performance
Q1: In the context of a noisy DBTL cycle, which ensemble method is generally more stable and accurate for small, categorical datasets?
For small datasets composed mainly of categorical variables, Random Forest (RF) generally provides more stable and accurate predictions [59]. Its bagging technique, which builds trees in parallel on random data subsets, is particularly effective at reducing model variance, a common issue with limited data [59] [60] [61]. In a direct comparison on a small dataset for demolition waste prediction, RF's predictions were more stable, though Gradient Boosting (GBM) could demonstrate excellent performance for specific waste types [59].
Q2: Why might my Gradient Boosting model be overfitting on our experimental dataset, and how can I prevent it?
Gradient Boosting is prone to overfitting, especially with noisy data or too many iterations, because its sequential trees focus on correcting previous errors [60]. To prevent this:
- Reduce Model Complexity: Use shallower trees (reduce
max_depth), and increasemin_samples_splitormin_samples_leaf[62]. - Use Regularization: Lower the
learning_rateand increase then_estimatorscorrespondingly [63] [62]. - Introduce Randomness: Utilize subsampling (
subsample < 1.0) to train each tree on a random fraction of the data, reducing variance [62].
Q3: What is a robust method for evaluating model performance when our experimental data is limited?
When data is scarce, Leave-One-Out Cross-Validation (LOOCV) is a highly effective technique [59]. In LOOCV, a model is trained on all data points except one, which is used for testing; this process is repeated until every data point has been the test subject once. This method maximizes training data usage for each iteration, providing a more reliable performance estimate for small datasets common in early-stage research [59].
Q4: How do the training methodologies of Random Forest and Gradient Boosting differ fundamentally?
The core difference lies in how they build and combine trees, as illustrated in the diagram below.
Q5: What key hyperparameters should I tune for Gradient Boosting to optimize performance on a small, noisy research dataset?
Hyperparameter tuning is critical for GBM. Focus on these key parameters [62]:
learning_rate: Controls the contribution of each tree. A lower rate (e.g., 0.01, 0.1) is more robust to noise but requires more trees [63] [62].n_estimators: The number of sequential trees. Use early stopping to find the optimal number and prevent overfitting [63] [64].max_depth/num_leaves: Restricts the complexity of individual trees. Shallower trees (e.g., depth of 3-8) are more generic and prevent overfitting [63] [62].subsample: Training on a fraction of the data (e.g., 0.8) introduces randomness and improves robustness [62].
Quantitative Performance Comparison
The following table summarizes the performance characteristics of Random Forest and Gradient Boosting in low-data regimes, synthesized from experimental findings [59] [60] [61].
| Performance Aspect | Random Forest | Gradient Boosting |
|---|---|---|
| Best for Small, Categorical Datasets | Yes (More stable and accurate) [59] | No (Can excel in specific cases) [59] |
| Overfitting Risk | Lower (Due to bagging and averaging) [60] [61] | Higher (Requires careful tuning) [60] [61] |
| Handling of Noisy Data | More robust [60] [61] | Less robust; can overfit to noise [60] |
| Hyperparameter Sensitivity | Low (Works well with defaults) [61] | High (Requires extensive tuning) [61] |
| Training Speed | Faster (Trees built in parallel) [61] | Slower (Sequential tree building) [61] |
| Key Tuning Parameters | n_estimators, max_depth, max_features [65] |
learning_rate, n_estimators, max_depth [62] |
Experimental Protocol for Model Evaluation in Low-Data Regimes
This protocol is designed to guide researchers in systematically comparing Random Forest and Gradient Boosting models with limited experimental data, a common scenario in early DBTL cycles.
Workflow Diagram:
Step-by-Step Methodology:
Data Preprocessing and Standardization [59] [66]:
- Handle missing values appropriately for your domain (e.g., imputation or removal).
- Standardize or normalize all features to ensure models are not skewed by variable scale.
- Encode categorical variables if necessary.
Performance Evaluation with LOOCV [59]:
- Given a small dataset size
n, createntraining/test splits. For each spliti:- Use a single sample
ias the test set. - Use the remaining
n-1samples as the training set. - This maximizes the training data used for each model fit.
- Use a single sample
- Given a small dataset size
Model Configuration and Hyperparameter Tuning [59] [62] [64]:
- Random Forest: Utilize bootstrap sampling and feature randomization at each split. Key parameters to tune include
n_estimators,max_depth, andmax_features[65]. - Gradient Boosting: Use a low
learning_rate(e.g., 0.01 to 0.1) coupled with a highern_estimators. Restrict tree complexity usingmax_depth(e.g., 3-6). Tune thesubsampleparameter. - Employ an efficient search strategy like Bayesian Optimization (e.g., with the Hyperopt library) or Random Search to find the optimal hyperparameters, as this can lead to significant performance improvements [64].
- Random Forest: Utilize bootstrap sampling and feature randomization at each split. Key parameters to tune include
Result Analysis:
- Calculate the average of your chosen performance metric (e.g., R², RMSE, ROC AUC) across all LOOCV folds for each model.
- Compare the average performance and the variance of the results to determine which model is both more accurate and stable for your specific dataset.
The Scientist's Toolkit: Essential Research Reagents
This table lists key software "reagents" and their functions for implementing and evaluating ensemble models in computational research.
| Research Reagent | Function / Application |
|---|---|
| Scikit-learn [65] [62] | A core Python library providing implementations of Random Forest (RandomForestRegressor/Classifier) and Gradient Boosting (GradientBoostingRegressor/Classifier), along with tools for model evaluation and hyperparameter tuning. |
| XGBoost / LightGBM [61] [64] | Optimized and highly efficient Gradient Boosting frameworks. They often provide faster training and better performance, supporting advanced features like built-in cross-validation and early stopping. |
| Hyperopt [64] | A Python library for Bayesian hyperparameter optimization. It is used to efficiently search the hyperparameter space and find the best configuration for a model, which is crucial for tuning sensitive algorithms like GBM. |
| dtreeviz [67] | A visualization library for interpreting decision trees from Random Forests and Gradient Boosting models. It helps researchers understand how a model makes predictions by visualizing the decision paths and leaf node statistics. |
Validation and Comparative Analysis: Case Studies in Metabolic Engineering and Beyond
Frequently Asked Questions (FAQs)
1. What is retrospective validation, and why is it critical for ML in research? Retrospective validation is a methodology for benchmarking a new machine learning model or experimental framework against existing, published datasets. Instead of collecting new data, you use historical data to test whether your new approach offers improvements in performance, efficiency, or cost-effectiveness. This is crucial for establishing credibility and demonstrating the value of your method within the scientific community, especially when resources for new, large-scale experiments are limited [15].
2. My model performs well on my internal data but fails on a published dataset. What could be wrong? This is a classic sign of a data shift or overfitting. The published dataset likely has a different statistical distribution. Key things to check:
- Data Quality: The published data may have different levels of noise, missing values, or systematic errors [68].
- Experimental Protocols: Differences in how data was generated (e.g., equipment, reagents, biological strains) can create significant shifts that your model hasn't learned [69].
- Feature Representation: Ensure you are processing and representing the features (e.g., data normalization, sequence encoding) in the same way as the original study.
3. How can I effectively use retrospective validation when my experimental resources are severely constrained? Retrospective validation is perfectly suited for low-resource scenarios. The core strategy is to use published data to simulate multiple rounds of experimentation computationally before doing any wet-lab work.
- Active Learning: Implement Active Learning (AL) strategies. An AL algorithm can select the most informative data points from a published dataset to "query" next, simulating which experiments would be most valuable to run. This helps you build a high-performance model with far fewer data points than traditional approaches [70].
- Bayesian Optimization: Use published data to build a surrogate model of your experimental landscape (e.g., how promoter combinations affect protein yield). Frameworks like Bayesian Optimization can then identify optimal conditions with dramatically fewer experimental iterations [15].
4. I've identified a suitable published dataset. What are the key steps to ensure my benchmarking is sound? A robust retrospective validation involves:
- Data Preprocessing: Carefully replicate the preprocessing steps (normalization, handling of missing values, outlier detection) described in the original publication [71].
- Noise Characterization: Quantify the experimental noise present in the published dataset, for example, by analyzing the variance between technical replicates. This allows you to simulate realistic noise in your validation [15].
- Performance Benchmarking: Compare your model's performance against the original study's results and other benchmark models using the same rigorous metrics (e.g., RMSE, AUC, R²) [71] [72].
- Temporal Validation: If the data spans multiple years, validate your model on the most recent data to ensure it remains relevant and hasn't been affected by temporal drift in the underlying processes [69].
Troubleshooting Guides
Problem: High Performance on Training Data, Poor Generalization to Test Splits and Published Sets
This typically indicates overfitting or data distribution mismatches.
- Possible Cause 1: The published dataset has a different feature distribution or higher noise levels.
- Solution: Perform a thorough exploratory data analysis (EDA) to compare the statistical properties (mean, variance, distributions) of your training data and the published set. Use techniques like Principal Component Analysis (PCA) to visualize if the datasets cluster separately. If a shift is found, consider retraining your model on a mixture of data sources or applying domain adaptation techniques [68] [69].
- Possible Cause 2: Your model is too complex and has learned the noise in your training data.
- Solution: Increase regularization (e.g., L1/L2 penalties), employ dropout if using neural networks, or simplify your model architecture. Using ensemble methods can also improve robustness [71].
Problem: Inability to Reproduce the Original Study's Baseline Performance
If you cannot match the original results, the issue is likely in your data processing pipeline.
- Possible Cause: Incorrect data preprocessing or misunderstanding of the dataset's train/test splits.
- Solution:
- Scrutinize the original paper's methods section for details on data splitting, normalization, and feature engineering.
- Check for data leaks. Ensure no information from the test set was used during your training or preprocessing.
- Reach out to the original authors for clarification or code if available. Many datasets are shared on platforms like Kaggle, OpenML, or Papers with Code, which often include community notebooks that can serve as a reference [73].
- Solution:
Problem: Navigating a Vast Design Space with Limited Experimental Budget
A common challenge in synthetic biology is optimizing a system with dozens of parameters (e.g., inducer concentrations) with only a few experiments possible.
- Possible Cause: Using inefficient search strategies like one-factor-at-a-time or grid search.
- Solution: Integrate Bayesian Optimization (BO) into your DBTL cycle.
- Methodology: BO uses a probabilistic surrogate model (like a Gaussian Process) to approximate the complex, unknown relationship between your inputs (e.g., DNA sequence, culture conditions) and outputs (e.g., protein yield). It then uses an acquisition function to recommend the next most promising experiment by balancing exploration (trying uncertain areas) and exploitation (refining known good areas) [15].
- Protocol:
- Define your objective function (what you want to optimize) and parameter bounds.
- Gather an initial small dataset (from published work or a small pilot experiment).
- For each iteration:
- Train the Gaussian Process model on all collected data.
- Use the acquisition function (e.g., Expected Improvement) to select the next parameter set to test.
- Run the experiment and record the result.
- Update the model with the new data [15].
- Case Study: A 2025 iGEM team used this approach to optimize a limonene production pathway. Their BO framework found the near-optimal condition after investigating only 18 unique parameter combinations, whereas the original paper's grid search required 83 combinations [15].
- Solution: Integrate Bayesian Optimization (BO) into your DBTL cycle.
Experimental Protocols & Data Presentation
Table 1: Summary of a Retrospective Validation Case Study (Limonene Production)
This table summarizes a real-world example of using retrospective validation to demonstrate efficiency gains. [15]
| Metric | Original Study (Grid Search) | Bayesian Optimization (BioKernel) | Improvement |
|---|---|---|---|
| Method Used | Exhaustive combinatorial search | Sequential model-based optimization | N/A |
| Points Investigated | 83 unique combinations | ~18 points | ~78% reduction |
| Convergence Criterion | Full grid evaluation | Normalized Euclidean distance to optimum < 10% | N/A |
| Key Advantage | Comprehensive | High sample efficiency | Dramatically fewer experiments |
Table 2: Essential Research Reagent Solutions for ML-Driven Biology
A toolkit for setting up an ML-driven experimental workflow. [15] [17] [70]
| Reagent / Solution | Function in ML-Driven Research |
|---|---|
| Cell-Free Transcription-Translation (TX-TL) Systems | Enables rapid, high-throughput testing of genetic constructs, decoupling testing from slow cell growth and generating data quickly for ML models [17]. |
| Standardized Genetic Parts (e.g., Marionette Array) | Provides a modular system with well-characterized, orthogonal parts. Essential for building a consistent dataset to train models on sequence-function relationships [15]. |
| Bayesian Optimization Software (e.g., BioKernel) | A no-code or code-based framework to implement Bayesian Optimization. It guides the selection of the next experiment to maximize information gain and accelerate optimization [15]. |
| Active Learning (AL) Framework | An ML strategy that iteratively selects the most "informative" samples to label (experiment on) next, minimizing experimental cost while maximizing model performance [70]. |
Workflow Diagrams for Retrospective Validation
The following diagram illustrates the core iterative process of using machine learning to guide biological experimentation, which is central to the modern DBTL cycle.
The ML-Guided DBTL Cycle
The diagram above shows the traditional Design-Build-Test-Learn (DBTL) cycle. A transformative approach, the LDBT (Learn-Design-Build-Test) cycle, places machine learning at the very beginning. This "learn-first" paradigm uses existing data to generate predictive models before any new design or experiment is conducted, making the entire process more efficient and less reliant on trial-and-error [17].
The diagram below details the specific workflow for conducting a robust retrospective validation study, from data preparation to final implementation.
Retrospective Validation Workflow
BioAutomata is a fully automated, algorithm-driven platform that closes the Design-Build-Test-Learn (DBTL) cycle for biosystems design, requiring minimal human intervention [5] [74]. It integrates robotic hardware with machine learning to optimize biological pathways, exemplified by the engineering of E. coli for increased lycopene production [5] [75].
The Scientist's Toolkit: Key Research Reagent Solutions
| Component Name | Function in the Experiment |
|---|---|
| Illinois Biological Foundry for Advanced Biomanufacturing (iBioFAB) | A fully automated robotic platform that executes the Build and Test phases, including DNA construction, cell transformation, and cultivation [5] [74]. |
| Lycopene Biosynthetic Pathway Genes | The target genes (e.g., crtE, crtB, crtI) from Pantoea agglomerans whose expression levels are fine-tuned to maximize lycopene yield [5] [75]. |
| Escherichia coli Host Strain | The production chassis (e.g., MG1655) engineered with a deleted yjiD gene to enhance lycopene precursor availability and enable colorimetric screening [5]. |
| Plasmids & Promoter Libraries | Vectors and regulatory parts (e.g., Anderson promoter library) used to construct combinatorial variants of the lycopene pathway with different expression strengths for each gene [5]. |
| Bayesian Optimization Algorithm | The core machine learning model that uses a Gaussian Process and Expected Improvement to decide which strain variants to build and test in the next cycle [5] [75]. |
Troubleshooting Guides and FAQs
This section addresses specific challenges researchers might face when implementing a DBTL cycle, with a focus on handling experimental noise.
FAQ 1: How does BioAutomata handle high experimental noise in the Test phase, and how can we validate its performance under these conditions?
Challenge: High variability in lycopene measurements (e.g., from extraction or analytics) can mislead the machine learning model, causing it to learn from noise rather than true biological signals.
Solutions:
- Algorithmic Robustness: The Bayesian Optimization algorithm in BioAutomata is explicitly designed for "expensive and noisy" experiments [5]. Its probabilistic model (Gaussian Process) incorporates an expected error term, which prevents it from becoming overconfident in data points and helps it remain robust to variability [75].
- Framework Validation: A kinetic model-based simulation framework, as described by van Lent et al., can be used to benchmark machine learning methods like BioAutomata under controlled noise conditions [10]. This allows researchers to test the platform's resilience to artificial noise before committing to costly wet-lab experiments.
- Technical Replication: Within the iBioFAB, implement built-in technical replicates for the lycopene assay of each strain. The system can be programmed to automatically discard and re-run tests where the coefficient of variation between replicates exceeds a predefined threshold (e.g., >15%).
FAQ 2: The model's recommendations seem to have stalled in a local optimum. How can we escape it?
Challenge: The learning algorithm is repeatedly selecting similar strains with minimal performance improvements, suggesting it is trapped.
Solutions:
- Adjust the Acquisition Function: The "Expected Improvement" function inherently balances exploitation (sampling near the current best hit) and exploration (sampling in uncertain regions) [5]. If stuck, you can manually adjust the algorithm's parameters to temporarily favor exploration, encouraging it to test riskier designs that might lead to a global optimum.
- Expand the Design Space: If possible, program the platform to include a wider range of regulatory parts (e.g., additional promoters with strengths outside the initially tested range) in the next Design phase. This gives the algorithm a broader space to explore.
- Incorporate Prior Knowledge: The platform can be manually paused to inject human expertise. For example, a researcher can pre-select a new set of promoter-gene combinations based on mechanistic knowledge of the pathway to "nudge" the algorithm into a more promising region of the design space.
FAQ 3: After multiple DBTL cycles, the predictive model's performance is not improving. What could be wrong?
Challenge: The machine learning model is failing to learn effectively from the accumulated data across cycles.
Solutions:
- Check for Training Set Bias: The initial library of built strains might have a biased distribution (e.g., mostly high-expression promoters). Research shows that gradient boosting and random forest models are particularly robust to such training set biases in the low-data regime typical of early DBTL cycles [10]. Consider switching to or incorporating these models within the learning phase.
- Review Data Quality: Re-examine the data for consistency. Drift in analytical instrument calibration over the weeks-long experiment can introduce systematic errors that corrupt the dataset. The platform should implement routine calibration checks for its spectrophotometers.
- Validate with a Simulated Framework: Use an in silico kinetic model of the pathway to generate a large, consistent dataset for testing the machine learning model's architecture and hyperparameters before applying it to real, noisy experimental data [10].
Experimental Protocols & Data
Detailed Methodology: BioAutomata-Driven Lycopene Pathway Optimization
Step 1: Initial Setup and Design
- Objective Function Definition: The goal is defined as maximizing lycopene titer in E. coli [5].
- Input Parameter Selection: The expression levels of the three lycopene biosynthetic genes (crtE, crtB, crtI) are chosen as the inputs to optimize [5].
- Library Design: A combinatorial DNA library is designed using a set of promoters with different strengths to systematically vary the expression level of each gene.
Step 2: Build
- The iBioFAB robotic platform automatically constructs the plasmid variants encoding the different pathway configurations and transforms them into the engineered E. coli production host [5] [74].
Step 3: Test
- The transformed strains are cultivated in deep-well plates under controlled conditions.
- After cultivation, cells are harvested, and lycopene is extracted using a standardized, automated protocol involving methanol.
- Lycopene concentration is quantified by measuring absorbance with a plate reader and comparing to a standard curve [5].
Step 4: Learn
- The lycopene titer data for the built strains is fed to the Bayesian optimization algorithm.
- A Gaussian Process model is updated to create a probabilistic prediction of the lycopene production landscape based on all data collected so far.
- The Expected Improvement acquisition function uses this model to select the next batch of strain designs that are most likely to improve lycopene titer, balancing exploration and exploitation [5] [75].
- These new designs are automatically sent back to the Build phase, closing the loop.
Quantitative Performance Data
Table 1: Key Performance Metrics of the BioAutomata Platform
| Metric | Performance Value | Context / Note |
|---|---|---|
| Design Space Reduction | Evaluated < 1% of possible variants | From over 10,000 possible pathway combinations down to about 100 built and tested [74]. |
| Efficiency vs. Random Screening | Outperformed random screening by 77% | Bayesian optimization found a higher-producing strain with significantly fewer experiments [5]. |
| Number of DBTL Cycles | Completed 2 fully automated cycles | Demonstrated fully closed-loop functionality from design to learning [74]. |
Table 2: Summary of Machine Learning Insights from Simulated DBTL Frameworks
| Insight | Finding / Recommendation | Source |
|---|---|---|
| Best Performing ML Models | Gradient Boosting and Random Forest | These models outperformed others in low-data scenarios and were robust to noise and bias [10]. |
| DBTL Cycle Strategy | A large initial cycle is favorable | When the total number of strains is limited, building more in the first cycle leads to better final performance than evenly distributing them [10]. |
| Framework Utility | Kinetic models enable consistent ML testing | Provides a controlled in-silico environment to benchmark methods and strategies before real-world application [10]. |
Workflow and Pathway Diagrams
BioAutomata DBTL Cycle
Lycopene Biosynthesis Pathway
FAQs: Autonomous DBTL Cycles
Q1: What is the key advantage of a fully autonomous Design-Build-Test-Learn (DBTL) cycle? A1: A fully autonomous DBTL cycle eliminates the need for human intervention between experimental iterations, dramatically speeding up the optimization process. It allows for continuous data generation and analysis, where a robotic platform directly uses results from one test round to program the next set of experiments, effectively closing the loop [4] [28].
Q2: Our automated platform collects data, but analysis is slow. How can machine learning (ML) help? A2: ML algorithms analyze large, reproducible datasets from robotic platforms to predict system behavior under different conditions. They help identify the most promising experimental parameters for the next cycle, striking a balance between exploring new possibilities (exploration) and refining known productive areas (exploitation) to accelerate finding the optimal solution [4] [28].
Q3: We observe high variability in our induction optimization results. What could be the cause? A3: Biological variability and batch-to-batch differences are common sources of noise that can challenge data analysis. Implementing an automated, high-throughput robotic platform minimizes human error and generates the large, consistent datasets needed to distinguish true signal from experimental noise, making the optimization process more robust [4] [28].
Q4: For a Bacillus subtilis expression system, are there alternatives to expensive chemical inducers? A4: Yes, you can utilize stress-induced expression systems. A SigB-dependent promoter (e.g., ohrB or gsiB) can be activated by applying environmental stresses such as heat shock, ethanol stress, salt stress, or glucose starvation. This provides a low-cost induction method, though expression levels may vary [76].
Troubleshooting Guides
Problem: Poor Bacterial Growth or Protein Yield in Microtiter Plates
| Potential Cause | Diagnostic Steps | Solution |
|---|---|---|
| Suboptimal Aeration | Check if condensation obscures wells; confirm shaking speed in incubator. | Ensure the platform's shake incubator is operating at the correct speed (e.g., 1,000 rpm used in the cited study [4] [28]). |
| Evaporation | Look for volume discrepancies in edge wells after incubation. | Use plates with seals or lids, and ensure the robotic platform's de-lidding station operates correctly to minimize exposure time [4] [28]. |
| Inconsistent Inoculation | Review liquid handler calibration logs; check for clogs in tips. | Recalibrate the liquid handling robots (e.g., CyBio FeliX) and use appropriate tip types for consistent volume transfer [4] [28]. |
Problem: Machine Learning Model Failing to Converge on an Optimal Solution
| Potential Cause | Diagnostic Steps | Solution |
|---|---|---|
| Insufficient Initial Data | Check the size of the dataset used for the first model training. | Start with a design-of-experiments (DoE) approach or a random search to generate a sufficiently broad initial dataset for the ML algorithm to learn from [4] [28]. |
| High Experimental Noise | Analyze replicate data for high variance; review platform consistency. | Use the robotic platform to run biological replicates to quantify and account for noise. Ensure all modules (incubator, plate reader) are properly maintained [4]. |
| Incorrect Balance of Exploration/Exploitation | Review the algorithm's parameter selection over iterations. | Adjust the optimizer module's objective function to better balance searching new parameter spaces (exploration) and refining known high-yield areas (exploitation) [4] [28]. |
Table 1: Optimization Results for Protein Production
Table summarizing key quantitative outcomes from the autonomous DBTL case study.
| Organism | Optimization Factor(s) | Target Product | Key Result | Source |
|---|---|---|---|---|
| E. coli | Inducer (Lactose/IPTG) & Feed Release Enzyme | Green Fluorescent Protein (GFP) | The platform successfully used an active-learning ML algorithm and random search over four autonomous iterations to maximize fluorescence. | [4] [28] |
| Bacillus subtilis | Inducer Concentration | Green Fluorescent Protein (GFP) | The autonomous system optimized the inducer concentration to maximize GFP fluorescence output. | [4] [28] |
Table 2: Induction Methods forBacillus subtilisExpression Systems
Table comparing different induction strategies for the SigB-dependent system [76].
| Induction Method | Promoter | *Fold Increase in Enzyme Activity | Notes |
|---|---|---|---|
| Glucose Starvation | ohrB | 14-fold | Induction occurs at transition to stationary phase; cost-effective. |
| Ethanol Stress | ohrB | 15-fold (in complex medium) | Maximum expression ~40 minutes post-induction. |
| Salt Stress (NaCl) | ohrB | 15.4-fold (in synthetic medium) | Highest controllability; best performance in synthetic medium. |
| Heat Shock | ohrB | 6-fold | A cheap and simple induction method. |
Compared to a non-induced control strain.
Signaling Pathway and Experimental Workflow
SigB Stress Response Pathway
Autonomous DBTL Workflow
Research Reagent Solutions
Table 3: Essential Materials for Automated Induction Optimization
| Item | Function / Application | Example from Study |
|---|---|---|
| 96-well Flat-bottom Microtiter Plates (MTP) | High-throughput cultivation vessel for bacterial growth in a robotic platform. | Used for cultivating E. coli and B. subtilis in the robotic platform [4] [28]. |
| Inducers (Lactose, IPTG) | Chemical triggers for initiating protein expression from specific promoters. | Used as input variables to optimize GFP production in E. coli [4] [28]. |
| Feed Release Enzyme | Enzyme that controls growth rates by releasing glucose from a polysaccharide. | Used as a dual-factor input with inducer for E. coli optimization [4] [28]. |
| SigB-dependent Promoter | Genetic part that induces protein expression in response to stress or starvation in B. subtilis. | ohrB promoter used for stress-induced xylanase production [76]. |
| Reporter Protein (GFP) | Easily measurable protein (via fluorescence) used as a marker for expression optimization. | Served as the target product for the autonomous optimization cycles [4] [28]. |
In data-driven biological research, particularly within Design-Build-Test-Learn (DBTL) cycles, hyperparameter tuning is a crucial step for developing accurate machine learning models. The presence of experimental noise—an inherent characteristic of biological data—poses significant challenges for traditional optimization methods. This technical support article provides a comparative analysis of Bayesian Optimization, Grid Search, and Random Search, with specific guidance for researchers handling noisy DBTL cycle data in fields such as metabolic engineering and drug development.
Core Concepts and Mechanisms
- Grid Search: This method performs an exhaustive search over a predefined grid of hyperparameter values. It evaluates every possible combination within the grid, providing a comprehensive search but becoming computationally prohibitive for high-dimensional spaces [77] [78] [79].
- Random Search: Instead of exhaustive evaluation, Random Search selects hyperparameter combinations randomly from specified distributions. This approach often finds good solutions with fewer iterations than Grid Search, especially when some hyperparameters have minimal impact on performance [77] [78] [79].
- Bayesian Optimization: This sequential model-based approach uses probabilistic surrogate models (typically Gaussian Processes) to approximate the objective function. It employs an acquisition function to balance exploration of uncertain regions with exploitation of promising areas, dramatically reducing the number of function evaluations required [77] [80] [15].
Quantitative Performance Comparison
The table below summarizes key performance characteristics of each method, particularly relevant for noisy experimental data:
Table 1: Performance Comparison of Hyperparameter Optimization Methods
| Method | Computational Efficiency | Noise Robustness | Typical Iterations Needed | Best For |
|---|---|---|---|---|
| Grid Search | Low - examines all combinations [77] | Low - no inherent noise handling | 648 combinations in one example [79] | Small parameter spaces (<5 parameters) |
| Random Search | Medium - random sampling [77] | Low - no inherent noise handling | ~60 for near-optimal solutions [79] | Medium spaces, quick prototyping |
| Bayesian Optimization | High - informed sequential choices [77] [80] | High - explicit noise modeling [81] [15] | 67 iterations in one benchmark [77] | Expensive experiments, noisy data |
Specialized Bayesian Approaches for Noisy Data
Recent advances in Bayesian Optimization specifically address experimental noise challenges:
- Heteroscedastic Noise Modeling: BioKernel, a Bayesian optimization framework developed for biological applications, incorporates heteroscedastic noise modeling to handle non-constant measurement uncertainty inherent in biological systems [15].
- Intra-step Noise Optimization: A novel Bayesian optimization workflow integrates noise optimization directly into automated experimental cycles by introducing measurement time as an additional parameter, simultaneously optimizing both the target property and associated measurement noise [81].
Experimental Protocols and Implementation
DBTL Cycle Integration Framework
The following diagram illustrates how hyperparameter optimization integrates within noisy experimental DBTL cycles:
Diagram 1: Bayesian Optimization in Noisy DBTL Cycles
Protocol: Bayesian Optimization for Noisy DBTL Data
Purpose: To optimize hyperparameters for machine learning models trained on noisy DBTL cycle data [10] [15]
Materials and Reagents:
- Experimental data from previous DBTL cycles with measured noise characteristics
- Computing environment with Bayesian optimization libraries (Optuna, Scikit-Optimize)
- Validation dataset held out from training process
Procedure:
- Characterize Experimental Noise: Quantify noise levels in your experimental data. For biological measurements, this may include technical replicates to estimate variance [15].
- Define Search Space: Specify hyperparameter ranges based on model requirements. Use continuous distributions where appropriate.
- Select Surrogate Model: Choose Gaussian Process regression with noise-handling capabilities [15].
- Configure Acquisition Function: Select Expected Improvement or Upper Confidence Bound, adjusting exploration/exploitation balance based on experimental costs [15].
- Run Iterative Optimization:
- For n iterations (typically 50-100 for biological problems):
- Train model with proposed hyperparameters
- Evaluate performance using cross-validation
- Update surrogate model with results
- Validate Optimal Configuration: Test best hyperparameters on held-out validation set.
Troubleshooting:
- For slow convergence: Increase exploration parameter in acquisition function
- For unstable results: Incorporate stronger noise priors in Gaussian Process
- For high-dimensional spaces: Use specialized kernels or dimensionality reduction
Table 2: Key Research Reagent Solutions for Optimization Experiments
| Resource | Type | Function | Example Applications |
|---|---|---|---|
| Optuna [77] | Software Framework | Bayesian optimization implementation | Hyperparameter tuning for drug target classification |
| Scikit-learn [78] [79] | Library | Provides GridSearchCV and RandomizedSearchCV | Comparative method implementation |
| HSAPSO [82] | Optimization Algorithm | Hierarchically Self-Adaptive Particle Swarm Optimization | Drug target identification with 95.5% accuracy |
| BioKernel [15] | Bayesian Framework | No-code Bayesian optimization for biological systems | Metabolic pathway optimization |
| Gaussian Process [81] [15] | Statistical Model | Surrogate function for Bayesian optimization | Modeling noisy experimental responses |
Frequently Asked Questions: Troubleshooting Experimental Optimization
Q1: My DBTL cycle data has significant experimental noise. Which optimization method should I prioritize?
A1: Bayesian Optimization is specifically designed for noisy, expensive-to-evaluate functions. Implement a Gaussian Process surrogate model with explicit noise modeling, such as the heteroscedastic noise capabilities in BioKernel [15] or the intra-step noise optimization framework [81]. These approaches directly address experimental noise rather than treating it as a nuisance.
Q2: How do I handle high-dimensional hyperparameter spaces in metabolic engineering applications?
A2: For spaces beyond 10-15 parameters, Random Search often outperforms Grid Search due to better coverage per evaluation [77] [79]. Bayesian Optimization remains effective for up to 20 dimensions with proper tuning [15]. Consider hierarchical methods like HSAPSO [82] or dimensionality reduction for very high-dimensional spaces.
Q3: We have limited computational resources but need good hyperparameters quickly. What's the best approach?
A3: Start with Random Search (50-100 iterations) for a quick baseline [79]. If resources allow, follow with Bayesian Optimization (50-70 iterations) to refine results [77] [80]. The Scikit-learn implementation of RandomizedSearchCV provides a practical starting point [78].
Q4: How do we validate that our optimization method is effectively handling experimental noise?
A4: Implement forward validation using historical DBTL cycle data. Compare optimized hyperparameters across different noise levels and dataset sizes. Successful methods should maintain performance stability as noise characteristics change [10] [15].
Q5: What are the signs that our Bayesian Optimization implementation isn't converging properly?
A5: Indicators include: (1) acquisition function values not decreasing over iterations, (2) excessive exploration without exploitation, or (3) high variance in cross-validation scores. Solutions include adjusting the acquisition function, incorporating better noise priors, or increasing the number of initial random points [80] [15].
Based on comparative analysis and experimental results:
- For noisy DBTL data: Bayesian Optimization with explicit noise modeling provides superior performance, as demonstrated in drug discovery (95.5% accuracy) [82] and metabolic engineering [10].
- For rapid prototyping: Random Search offers better efficiency than Grid Search for most applications [77] [79].
- For high-cost experiments: Bayesian Optimization reduces experimental burden by 5-7x compared to traditional methods [80] [15].
Select optimization methods based on your experimental constraints, noise characteristics, and computational resources, using the provided protocols and troubleshooting guides to implement effective solutions for your research context.
Frequently Asked Questions
Q: What are the most common sources of noise in high-throughput DBTL cycles? Biological variability, measurement inconsistencies from instruments like plate readers, and environmental fluctuations in equipment such as incubators are common noise sources. This non-biological variability can be introduced by methodological variations between different experimenters or sites, as well as by batch-to-batch differences in reagents or consumables [83] [4].
Q: How can I determine if my DBTL process is robust to experimental noise? A key method is to test your machine learning models and optimization algorithms with simulated data where the level and type of noise can be controlled. Research shows that algorithms like gradient boosting and random forest demonstrate particular robustness to training set biases and experimental noise, making them good candidates for noisy biological data [10].
Q: What is a simple way to quickly assess noise levels in my experimental setup? Conduct replicate experiments. A high degree of variability in the output measurements (e.g., product titer, fluorescence, cell density) between identical designs is a strong indicator of significant experimental noise. Implementing a semi-automated pipeline can significantly improve repeatability and provide the high-quality data required for machine learning to be effective [14].
Q: My ML model performs well on training data but fails in the next DBTL cycle. Could noise be the cause? Yes. This can happen if the training data contains biases or unaccounted-for noise, causing the model to learn spurious correlations rather than the underlying biological signal. Using a framework to simulate and test ML performance over multiple DBTL cycles can help identify and mitigate this issue [10].
Troubleshooting Guides
Problem: High variability in output measurements obscures the performance of engineered strains. This problem manifests as inconsistent titer, yield, or rate (TYR) measurements for strains with identical genetic designs, making it difficult to rank them correctly.
- Step 1: Identify the source. Systematically check your process.
- Biological Replicates: Are the replicates (cultures started from separate colonies) also highly variable? If yes, the noise may be biological in origin (e.g., mutations, stochastic gene expression).
- Technical Replicates: If technical replicates (aliquots of the same culture measured multiple times) show high variability, the issue likely lies with your measurement instrument or liquid handling steps.
- Step 2: Implement controls.
- Use a control strain with known performance in every experimental plate to normalize for inter-batch variability.
- Fully document media recipes, growth conditions, and instrument calibration schedules.
- Step 3: Increase automation. Where possible, use liquid handling robots and automated cultivation platforms to minimize human-induced variation in pipetting, incubation, and measurement [4] [14].
- Step 4: Apply robust statistical models. Switch to statistical methods like mixed model analyses or hierarchical linear models that are better suited to partition and account for different sources of variability, rather than traditional analysis of variance which can mask individual differences [84].
Problem: Optimization algorithm performance plateaus or becomes unstable after several DBTL cycles. The algorithm fails to find improved designs or its recommendations appear random, often due to noise overwhelming the true signal.
- Step 1: Evaluate your algorithm's noise robustness. Test different machine learning methods (e.g., Random Forest, Gradient Boosting) using a simulated kinetic model of your pathway where you can control the noise level. Studies have shown these methods can perform well in low-data, noisy regimes [10].
- Step 2: Re-calibrate the exploration-exploitation balance. Your algorithm may be over-exploring (jumping to random points due to noise) or over-exploiting (getting stuck in a local optimum). Actively adjust the parameters that control this balance in your recommendation tool [10] [4].
- Step 3: Review the data quality. Ensure that the data used for training is reliable. It can be beneficial to have a larger initial DBTL cycle to build a more robust foundational model before moving to smaller, iterative cycles [10].
- Step 4: Incorporate noise directly into the model. Use a technique like Design of Experiments (DOE) to explicitly study how controllable factors (e.g., type of bearing, grease in a mechanical system) interact with and can minimize the effect of noise factors (e.g., load). The goal is to find a "sweet spot" where the output is less sensitive to noise variations [85].
Key Performance Metrics Table
The following table summarizes quantitative and qualitative metrics for evaluating the success of your noise-handling strategies.
| Metric Category | Specific Metric | Description and Application in DBTL Cycles |
|---|---|---|
| Data Quality | Coefficient of Variation (CV) | Measures relative variability of replicates. A low CV indicates consistent data generation, crucial for reliable learning [14]. |
| Signal-to-Noise Ratio (SNR) | Quantifies how much the signal of interest (e.g., production titer) stands above background noise. A higher SNR makes optimization easier. | |
| Model Performance | Prediction Accuracy on Test Sets | Evaluates how well a model trained on one cycle predicts outcomes in the next. High accuracy indicates robustness to noise [10]. |
| Recommendation Success Rate | The proportion of recommended designs in a cycle that lead to a performance improvement. A key metric for the effectiveness of the "Learn" phase [10] [14]. | |
| Process Efficiency | Number of Cycles to Target | The number of DBTL cycles required to reach a pre-defined performance target (e.g., a specific titer). Fewer cycles indicate a more efficient and less noise-sensitive process. |
| Experimental "Cost" per Cycle | The total number of strains built and tested in each cycle. Strategies that use ML to recommend fewer, higher-quality designs are more efficient [10]. |
Experimental Protocol: Assessing Algorithm Robustness to Noise
This protocol uses a kinetic model to benchmark machine learning algorithms for DBTL cycles under controlled noise conditions, as described in the research [10].
1. Objective To evaluate and select machine learning algorithms that maintain robust performance in recommending optimal strain designs when trained on data containing simulated experimental noise.
2. Materials and Software
- Kinetic Modeling Software: A platform like the symbolic kinetic models in Python (SKiMpy) package to simulate a metabolic pathway [10].
- Machine Learning Libraries: Libraries for algorithms such as Random Forest, Gradient Boosting, and others for comparison.
- Data Simulation Script: A custom script to generate combinatorial library data and add synthetic noise.
3. Methodology
- Step 1: Model a Reference Pathway. Use the kinetic modeling software to build a mechanistic model of a representative metabolic pathway (e.g., a linear pathway producing a compound "G") integrated into a core cellular model [10].
- Step 2: Generate Combinatorial Library Data. Simulate a large library of strain designs by varying enzyme concentrations (Vmax parameters) and record the resulting product flux for each design.
- Step 3: Introduce Synthetic Noise. To the clean simulated product flux data, add random Gaussian noise to represent experimental measurement error. The standard deviation of the noise should be set as a percentage of the mean signal to reflect realistic conditions.
- Step 4: Execute Simulated DBTL Cycles.
- Cycle 0 (Initial Design): Randomly select an initial subset of strains from the noisy library to build and "test."
- Learn & Recommend: Train each ML algorithm on the collected noisy data. Use a recommendation algorithm to select the next set of promising strains for the next cycle.
- Cycle N: "Test" the recommended strains by getting their noisy performance data from the simulation. Retrain the models and repeat for multiple cycles.
- Step 5: Evaluate Performance. Track the key metrics from the table above (e.g., Prediction Accuracy, Recommendation Success Rate) for each algorithm over the simulated cycles. The algorithm that most consistently and quickly identifies the highest-producing strain is the most robust.
DBTL Cycle with Noise Handling
The following diagram illustrates how noise-handling strategies are integrated into each stage of the DBTL cycle.
The Scientist's Toolkit: Essential Reagents & Solutions
This table lists key resources used in advanced, automated DBTL workflows for handling noise.
| Item Name | Function in the Workflow | Specific Example / Citation |
|---|---|---|
| Automated Cultivation Platform | Provides highly reproducible cell growth and expression conditions by tightly controlling temperature, humidity, and shaking, thereby reducing environmental noise. | BioLector system, Cytomat shake incubator [4] [14]. |
| Automated Liquid Handler | Precisely dispenses media components and inoculants, minimizing human error and variation in sample preparation. | CyBio FeliX liquid handling robots [4]. |
| Plate Reader | Enables high-throughput, quantitative measurement of output phenotypes such as fluorescence (e.g., GFP) and optical density (OD). | PheraSTAR FSX plate reader [4]. |
| Kinetic Modeling Software | Creates in silico models of metabolic pathways to simulate DBTL cycles and benchmark ML algorithms without the cost of real experiments. | Symbolic Kinetic Models in Python (SKiMpy) [10]. |
| Automated Recommendation Tool (ART) | A machine learning software that uses an active learning process to recommend the next best experiments, balancing exploration and exploitation. | Used to optimize media composition and inducer concentrations [14]. |
Conclusion
Effectively managing experimental noise is not merely a technical hurdle but a fundamental requirement for successful DBTL cycles in biomedical research. The integration of robust machine learning methodologies, particularly Bayesian optimization and Gaussian processes, provides a powerful framework for learning from noisy, high-dimensional biological data. When combined with automated, replicable experimental platforms and strategic workflow design, these approaches enable researchers to navigate complex design spaces with greater confidence and efficiency. The future of biomedical discovery, from next-generation cell factories to novel therapeutic development, hinges on our ability to close the loop on autonomous, noise-resilient DBTL cycles, dramatically reducing the time and resources required to bring innovations from the lab to the clinic.
References
- 1. Drug Discovery Assays Support—Troubleshooting [https://www.thermofisher.com/us/en/home/technical-resources/technical-reference-library/drug-discovery-development-support-center/drug-discovery-assays-support/drug-discovery-assays-support-troubleshooting.html]
- 2. Characterizing noise structure in single-cell RNA-seq ... [https://www.nature.com/articles/ncomms9687]
- 3. Teaching Your Lab Staff to Successfully Troubleshoot [https://www.labmanager.com/teaching-your-lab-staff-to-successfully-troubleshoot-32784]
- 4. Closing the loop: establishing an autonomous test-learn ... [https://www.frontiersin.org/journals/bioengineering-and-biotechnology/articles/10.3389/fbioe.2024.1528224/full]
- 5. Towards a fully automated algorithm driven platform for ... [https://www.nature.com/articles/s41467-019-13189-z]
- 6. Challenges in measuring and understanding biological noise [https://pmc.ncbi.nlm.nih.gov/articles/PMC7611518/]
- 7. Engineering Success | TJI-Seoul - iGEM 2025 [https://2025.igem.wiki/tji-seoul/engineering.html]
- 8. Method of variability optimization in pharmacokinetic data ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4048666/]
- 9. Excipient variability in drug products [https://pharma.iff.com/resources/managing-excipient-variability-in-drug-development-our-answers-to-important-questions]
- 10. Simulated Design–Build–Test–Learn Cycles for Consistent ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10510747/]
- 11. Our Capabilities [https://www.debutbiotech.com/our-capabilities]
- 12. The Relationship Between Biological Noise and Its Application [https://pmc.ncbi.nlm.nih.gov/articles/PMC12024716/]
- 13. Challenges and Opportunities in Smart Biosensing for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12455640/]
- 14. Machine learning-led semi-automated medium ... [https://www.nature.com/articles/s42003-025-08039-2]
- 15. Model: Bayesian Optimisation for Biology | Imperial - iGEM 2025 [https://2025.igem.wiki/imperial/Model]
- 16. Jiangnan-China - iGEM 2025 [https://2025.igem.wiki/jiangnan-china/supplementary-material]
- 17. LDBT: Machine Learning Meets Rapid Cell-Free Testing [https://bioengineer.org/ldbt-machine-learning-meets-rapid-cell-free-testing/]
- 18. Eliciting the impacts of cellular noise on metabolic trade- ... [https://www.nature.com/articles/s41467-019-08717-w]
- 19. Quantifying Dynamic Regulation in Metabolic Pathways with ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6531928/]
- 20. Simulated Design-Build-Test-Learn Cycles for Consistent ... [https://www.broadinstitute.org/publications/broad1340736]
- 21. Diagnosing and fixing common problems in Bayesian ... [https://arxiv.org/html/2406.07709v1]
- 22. Diagnosing and fixing common problems in Bayesian ... [https://openreview.net/forum?id=V4aG4wsoIt]
- 23. Bayesian optimization with experimental failure for high- ... [https://www.nature.com/articles/s41524-022-00859-8]
- 24. Batched Bayesian Optimization for Drug Design in Noisy ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9472273/]
- 25. Bayesian optimization for material discovery processes with ... [https://pubs.rsc.org/en/content/articlehtml/2022/me/d1me00154j]
- 26. Bayesian Optimization over Multiple Experimental Fidelities ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11869128/]
- 27. Uncertainty Quantification in Probabilistic Machine ... [https://arxiv.org/abs/2509.05877]
- 28. Closing the loop: establishing an autonomous test-learn cycle ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11795046/]
- 29. Text has enhanced contrast | ACT Rule | WAI [https://www.w3.org/WAI/standards-guidelines/act/rules/09o5cg/]
- 30. Elements must meet minimum color contrast ratio thresholds [https://dequeuniversity.com/rules/axe/4.8/color-contrast]
- 31. Color contrast accessibility requirements explained [https://blog.pope.tech/2022/11/08/color-contrast-accessibility-requirements-explained/]
- 32. Estimation of heteroscedastic measurement noise variances [https://www.sciencedirect.com/science/article/abs/pii/S0169743906001869]
- 33. An automated Design-Build-Test-Learn pipeline for ... [https://www.nature.com/articles/s42003-018-0076-9]
- 34. Exploring Bayesian Optimization [https://distill.pub/2020/bayesian-optimization]
- 35. Exploration-Exploitation Trade-Offs [https://www.emergentmind.com/topics/exploration-exploitation-trade-offs]
- 36. A generalized platform for artificial intelligence-powered ... [https://www.nature.com/articles/s41467-025-61209-y]
- 37. The Autonomous Lab: AI Platforms Redefining Enzyme ... [https://www.ailurus.bio/post/the-autonomous-lab-ai-platforms-redefining-enzyme-engineering]
- 38. Best Practices For Implementing Design Of Experiments ... [https://enertherm-engineering.com/best-practices-for-implementing-design-of-experiments-doe-in-industrial-settings/]
- 39. What is Design of Experiments (DOE)? [https://safetyculture.com/topics/design-of-experiments]
- 40. , Design , Taguchi, Plackett Burman of Experiments DOE [https://www.six-sigma-material.com/Design-of-Experiments.html]
- 41. Advanced Robust Design Strategies in DOE [https://www.numberanalytics.com/blog/advanced-robust-doe-strategies]
- 42. ( Design ) - MATLAB & Simulink of Experiments DOE [https://ww2.mathworks.cn/help/stats/design-of-experiments.html]
- 43. Troubleshooting Problems Affecting Tooling During Tablet ... [https://www.pharmtech.com/view/troubleshooting-problems-affecting-tooling-during-tablet-manufacture]
- 44. Troubleshooting Lab Operations: Be Proactive, Not Reactive [https://www.biopharminternational.com/view/troubleshooting-lab-operations-be-proactive-not-reactive]
- 45. Design of Experiments (DoE) [https://www.sptlabtech.com/applications/design-of-experiments-doe]
- 46. Frequently Asked Questions on Drug Development and ... [https://www.fda.gov/drugs/cder-small-business-industry-assistance-sbia/small-business-assistance-frequently-asked-questions-drug-development-and-investigational-new-drug]
- 47. How to ensure lab reproducibility with automation [https://automata.tech/blog/how-to-ensure-lab-reproducibility-with-automation/]
- 48. Automation in the Life Science Research Laboratory [https://www.frontiersin.org/journals/bioengineering-and-biotechnology/articles/10.3389/fbioe.2020.571777/full]
- 49. Automation of cDNA Synthesis and Labelling Improves ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC2763127/]
- 50. How to troubleshoot automation problems in the lab [https://biosero.com/blog/7-ways-to-troubleshoot-automation-problems-in-the-lab/]
- 51. How Automation Overcomes Variability & Limitations in ... [https://dispendix.com/blog/how-automation-overcomes-variability-limitations-in-hts-troubleshooting]
- 52. Automation in Drug Discovery [https://frontlinegenomics.com/automation-in-drug-discovery/]
- 53. Streamlining Biotech Drug Discovery with Lab Automation ... [https://www.wakoautomation.com/streamlining-biotech-drug-discovery-with-lab-automation-solutions]
- 54. Digital to Biological Translation: How the Algorithmic Data ... [https://www.mdpi.com/2674-0583/3/4/17]
- 55. The Root Causes and Solutions of Noise Problems in ... [https://www.limonrobot.com/the-root-causes-and-solutions-of-noise-problems-in-linear-guides]
- 56. Understanding Success Criterion 1.4.11: Non-text Contrast [https://www.w3.org/WAI/WCAG21/Understanding/non-text-contrast.html]
- 57. Data Visualizations, Charts, and Graphs - Digital Accessibility [https://accessibility.huit.harvard.edu/data-viz-charts-graphs]
- 58. How to Troubleshoot Experiments that Just Aren't Working [https://go.zageno.com/blog/how-to-troubleshoot-experiments-that-just-arent-working]
- 59. Comparison of Random Forest and Gradient Boosting ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8392226/]
- 60. Gradient Boosting vs. Random Forest: Which Ensemble ... [https://medium.com/@hassaanidrees7/gradient-boosting-vs-random-forest-which-ensemble-method-should-you-use-9f2ee294d9c6]
- 61. Random Forest vs Gradient Boosting-Choose Like an Expert [https://vedanganalytics.com/random-forest-vs-gradient-boosting-choose-like-an-expert/]
- 62. Gradient Boosting | Hyperparameter Tuning Python [https://www.analyticsvidhya.com/blog/2016/02/complete-guide-parameter-tuning-gradient-boosting-gbm-python/]
- 63. A Visual Guide to Tuning Gradient Boosted Trees [https://towardsdatascience.com/a-visual-guide-to-tuning-gradient-boosted-trees/]
- 64. Bayesian Hyperparameter Optimization of Gradient ... [https://medium.com/@maslovavictoria/bayesian-hyperparameter-optimization-of-gradient-boosting-machine-6f51996ff5f1]
- 65. Random Forest | TDS Archive [https://medium.com/data-science/random-forest-explained-a-visual-guide-with-code-examples-9f736a6e1b3c]
- 66. Comparing 13 Algorithms on 165 Datasets (hint: use ... [https://www.machinelearningmastery.com/start-with-gradient-boosting/]
- 67. Visualizing and interpreting decision trees [https://blog.tensorflow.org/2023/06/visualizing-and-interpreting-decision.html]
- 68. The effects of data quality on machine learning ... [https://www.sciencedirect.com/science/article/pii/S0306437925000341]
- 69. Diagnostic framework to validate clinical machine learning ... [https://www.nature.com/articles/s43856-025-00965-w]
- 70. Advancing genetic engineering with active learning [https://pmc.ncbi.nlm.nih.gov/articles/PMC12236445/]
- 71. Machine learning-based academic performance prediction ... [https://www.nature.com/articles/s41598-025-12353-4]
- 72. A Retrospective Validation of a Federated Machine ... [https://www.sciencedirect.com/science/article/pii/S2667102625000907]
- 73. 5 Best Machine Learning Repository Datasets (2025) [https://averroes.ai/blog/machine-learning-repository-datasets]
- 74. Artificial intelligence to run the chemical factories of the future [https://news.illinois.edu/artificial-intelligence-to-run-the-chemical-factories-of-the-future/]
- 75. Towards a fully automated algorithm driven platform for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6853954/]
- 76. of Bacillus Induction expression system using environmental... subtilis [https://annalsmicrobiology.biomedcentral.com/articles/10.1007/s13213-013-0719-5]
- 77. Bayesian vs Grid vs Random Search | Keykabs [https://keylabs.ai/blog/hyperparameter-tuning-grid-search-random-search-and-bayesian-optimization/]
- 78. 3.2. Tuning the hyper-parameters of an estimator [https://scikit-learn.org/stable/modules/grid_search.html]
- 79. Grid Search vs Random Search: Which One Should You ... [https://www.blog.trainindata.com/grid-search-vs-random-search-which-one-should-you-use/]
- 80. Grid Search vs. Random Search vs. Bayesian Optimization [https://blog.dailydoseofds.com/p/grid-search-vs-random-search-vs-bayesian]
- 81. Measurements with noise: Bayesian optimization for co ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d4dd00391h]
- 82. Automated drug design for druggable target identification ... [https://www.nature.com/articles/s41598-025-18091-x]
- 83. 2. Noise in Clinical Trials and Observational Studies - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC10011845/]
- 84. Noisy Data: Incorporating Variability into Your Analysis [https://tlr-hub.asha.org/cred/noisy-data-incorporating-variability-into-your-analysis/]
- 85. Using Design of Experiments to Minimize Noise Effects [https://blog.minitab.com/en/blog/applying-statistics-in-quality-projects/using-design-of-experiments-to-minimize-noise-effects]