Closed-Loop DBTL Platforms: How AI Agents Are Revolutionizing Drug Discovery
This article explores the transformative integration of AI agents into closed-loop Design-Build-Test-Learn (DBTL) platforms for drug discovery.
Closed-Loop DBTL Platforms: How AI Agents Are Revolutionizing Drug Discovery
Abstract
This article explores the transformative integration of AI agents into closed-loop Design-Build-Test-Learn (DBTL) platforms for drug discovery. Tailored for researchers and development professionals, it provides a comprehensive analysis of the foundational principles, methodological applications, and optimization strategies of these autonomous systems. By examining real-world implementations, performance metrics, and comparative insights from leading biotechs, the content offers a validated perspective on how agentic AI is compressing development timelines from years to months, enhancing precision, and reshaping the future of therapeutic development.
The New Discovery Engine: Understanding Closed-Loop DBTL and Agentic AI
The Design-Build-Test-Learn (DBTL) cycle has long been the cornerstone framework for biological engineering and drug discovery. This iterative process involves designing biological constructs, building them in the lab, testing their performance, and learning from the results to inform the next design cycle. However, traditional DBTL approaches have been persistently hampered by a critical bottleneck: they are slow, resource-intensive, and heavily reliant on deep human expertise at every stage [1]. The sequential nature of DBTL creates significant delays, with the "Build" and "Test" phases being particularly time-consuming, often requiring weeks or months for a single iteration.
A paradigm shift is now underway, moving from human-guided DBTL to fully autonomous LDBT (Learn-Design-Build-Test) workflows. This transformation is powered by artificial intelligence (AI) and laboratory automation, repositioning "Learning" to the beginning of the cycle [2]. Instead of starting with design based on limited human intuition, LDBT begins with machine learning models that have already learned from vast biological datasets. These AI-driven systems can then design optimized experiments, which are automatically built and tested by robotic platforms. This reordering creates a continuous, closed-loop system that dramatically accelerates discovery timelines while reducing costs and human labor requirements.
The LDBT Framework: Core Components and Workflow
The LDBT framework represents a fundamental reorganization of the scientific method for applied biology. By placing learning first, the system leverages accumulated knowledge before committing to specific experimental directions. This approach is enabled by several key technological advancements: the availability of massive biological datasets, sophisticated machine learning algorithms capable of extracting meaningful patterns from these datasets, and integrated robotic systems that can execute laboratory procedures with minimal human intervention [1] [2].
Table: Comparison of DBTL vs. LDBT Paradigms
| Feature | Traditional DBTL | Autonomous LDBT |
|---|---|---|
| Starting Point | Human hypothesis | AI-prioritized designs |
| Learning Phase | After testing results | Before design phase |
| Human Involvement | Required at all stages | Minimal oversight |
| Iteration Speed | Weeks to months | Days to weeks |
| Data Utilization | Limited to previous cycle | All available biological data |
| Scalability | Limited by human capacity | Limited by compute resources |
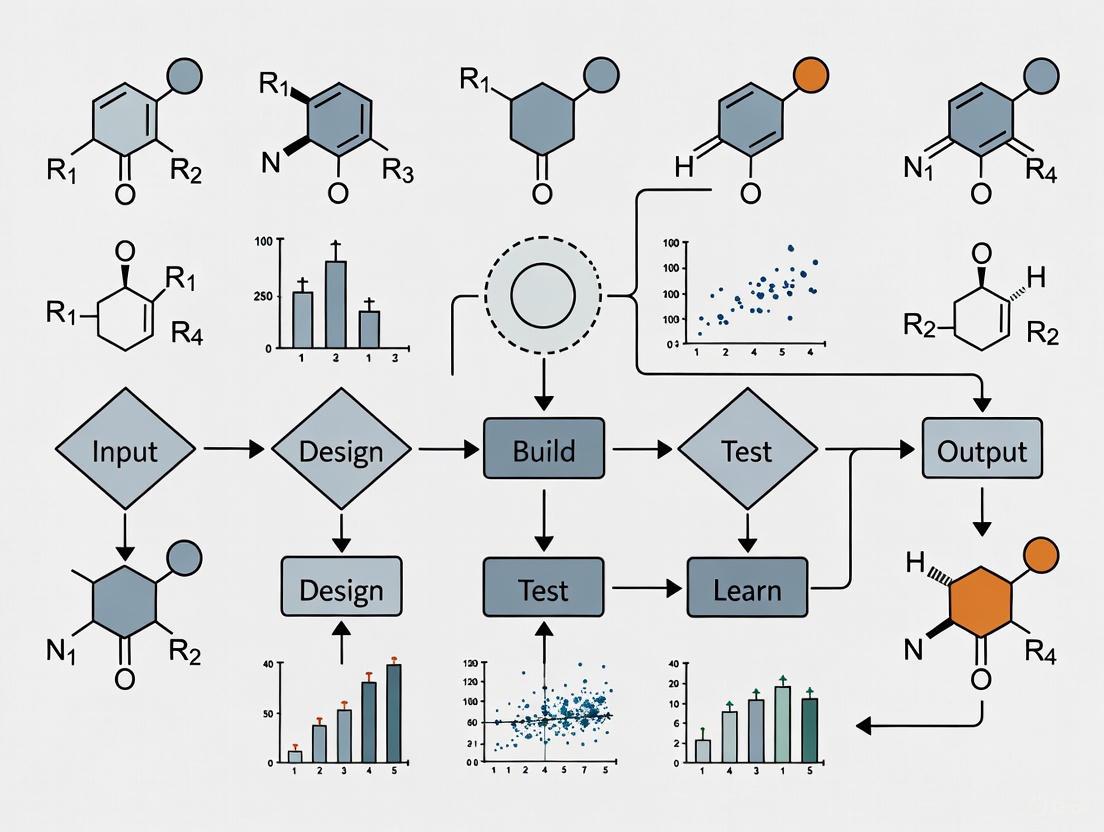
Workflow Visualization
The following diagram illustrates the core architecture and information flow of an autonomous LDBT system:
Implementation Protocols for Autonomous Enzyme Engineering
Case Study: AI-Driven Enzyme Optimization
A landmark 2025 study by Zhao et al. demonstrated a fully integrated LDBT platform for enzyme engineering [1]. The system was applied to two distinct enzymes with different engineering goals: Arabidopsis thaliana halide methyltransferase (AtHMT) and Yersinia mollaretii phytase (YmPhytase). The platform required only the protein sequence and a defined fitness metric, then operated autonomously through multiple iterations.
Table: Experimental Results from Autonomous Enzyme Engineering
| Enzyme | Engineering Goal | Iterations | Variants Screened | Key Improvement | Timeline |
|---|---|---|---|---|---|
| AtHMT | Ethyltransferase activity | 4 cycles | <500 | ~16-fold increase | 4 weeks |
| AtHMT | Substrate preference | 4 cycles | <500 | ~90-fold shift | 4 weeks |
| YmPhytase | Activity at neutral pH | 4 cycles | <500 | ~26-fold higher specific activity | 4 weeks |
Step-by-Step Experimental Protocol
Phase 1: Knowledge-Based Initial Design
Input Specification: Define the target protein sequence and quantitative fitness metric (e.g., enzymatic activity, thermostability, expression level).
Zero-Shot Library Design:
Library Prioritization: Rank variants by composite score balancing novelty, predicted fitness, and structural diversity.
Phase 2: Automated Build and Test
DNA Construction:
Protein Production:
High-Throughput Assaying:
- Implement coupled colorimetric or fluorescent assays compatible with microtiter plates or droplet systems.
- Measure relevant enzyme kinetics (kcat, KM) or stability parameters.
Phase 3: Continuous Learning and Optimization
Data Processing: Automate data collection, normalization, and quality control.
Model Retraining:
- Train supervised "low-N" regression models on experimental results [1].
- Update protein language models with new fitness landscape information.
Next-Generation Design:
- Apply active learning algorithms to select informative variants for subsequent rounds.
- Combine beneficial mutations into higher-order combinations.
- Return to Phase 1 for subsequent iterations until fitness target achieved.
Workflow Automation Architecture
The experimental protocol is executed through a tightly integrated system of AI agents and robotic automation:
Essential Research Reagents and Computational Tools
Successful implementation of LDBT workflows requires both specialized laboratory reagents and sophisticated computational tools. The table below details key components of the "scientist's toolkit" for autonomous enzyme engineering:
Table: Research Reagent Solutions for LDBT Implementation
| Category | Specific Tool/Reagent | Function | Implementation Notes |
|---|---|---|---|
| Computational Models | ESM-2 (Evolutionary Scale Modeling) | Protein language model for zero-shot mutation prediction | Pre-trained on millions of natural sequences; captures evolutionary constraints [1] |
| EVmutation | Epistasis model for predicting mutation interactions | Accounts for non-additive effects of combinations [1] | |
| ProteinMPNN | Structure-based sequence design | Input protein backbone, outputs optimized sequences [2] | |
| Automation Systems | iBioFAB (Illinois Biofoundry) | Fully automated genetic construction | Enables continuous processing without manual steps [1] |
| Cell-free expression systems | Rapid protein synthesis without living cells | Achieves >1 g/L protein in <4 hours; enables toxic protein production [2] | |
| Droplet microfluidics | Ultra-high-throughput screening | Screen >100,000 picoliter-scale reactions in parallel [2] | |
| Specialized Reagents | High-fidelity mutagenesis kits | Error-free DNA construction | ~95% accuracy eliminates sequencing verification [1] |
| Coupled enzyme assays | Quantitative activity measurement | Colorimetric/fluorescent readouts compatible with automation [2] |
Applications in Drug Discovery and Development
The LDBT framework demonstrates particular promise in pharmaceutical applications, where it accelerates multiple stages of the drug development pipeline. AI-driven platforms can analyze diverse biological data—including genomics, proteomics, and clinical records—to identify novel drug targets more effectively than traditional methods [3]. For example, machine learning models trained on datasets of 10,000–15,000 entries have been successfully employed for target proteins such as the main protease of SARS-CoV-2 (Mpro) in antiviral drug development and hERG in cardiotoxicity assessment [3].
In lead discovery and optimization, AI-powered virtual screening rapidly evaluates vast chemical libraries, significantly reducing reliance on resource-intensive high-throughput screening [3] [4]. Quantitative structure-activity relationship (QSAR) models and molecular docking simulations predict biological activity of novel compounds with high accuracy, guiding efficient synthesis priorities [4]. These approaches are particularly valuable for optimizing critical drug properties including solubility, stability, and bioavailability, with datasets of approximately 1,000–5,000 data points used for water solubility predictions [3].
The integration of LDBT approaches in pharmaceutical development addresses key industry challenges, including the typically extensive timelines (often exceeding 15 years) and high costs (averaging over $2.5 billion) associated with bringing a new drug to market [4]. By enabling more predictive and efficient discovery cycles, LDBT frameworks have the potential to significantly accelerate the delivery of novel therapeutics.
Artificial intelligence is undergoing a fundamental transformation in its role within scientific discovery, particularly in biomedical research and drug development. The field is rapidly evolving beyond the use of AI as specialized computational tools toward the emergence of Agentic AI systems that function as autonomous research partners [5] [6]. This transition represents a pivotal stage in the broader "AI for Science" paradigm, where AI systems progress from providing partial assistance to exercising full scientific agency [5]. Within the context of closed-loop Design-Build-Test-Learn (DBTL) platforms, this shift enables increasingly autonomous cycles of hypothesis generation, experimental design, execution, analysis, and iterative refinement—behaviors once regarded as uniquely human domains of scientific expertise [5].
Agentic AI systems in biomedical research combine large language models (LLMs), generative models, and machine learning tools with structured memory for continual learning [6]. Rather than removing humans from the discovery process, these systems augment human creativity and expertise with AI's ability to analyze massive datasets, navigate complex hypothesis spaces, and execute repetitive tasks at scale [6]. This collaboration is particularly transformative for drug discovery, where AI agents can plan discovery workflows, perform self-assessment to identify knowledge gaps, and integrate diverse biological principles and theories into their reasoning processes [6].
The Evolution from Traditional DBTL to LDBT and Agentic Workflows
The Traditional DBTL Cycle in Synthetic Biology and Drug Discovery
The established paradigm for biological engineering and drug discovery has followed the Design-Build-Test-Learn (DBTL) framework [7]. In this iterative cycle:
- Design: Researchers define objectives for desired biological function and design biological parts or systems using domain knowledge and computational modeling.
- Build: DNA constructs are synthesized, assembled into vectors, and introduced into characterization systems (in vivo chassis or in vitro cell-free systems).
- Test: Experimental measurement of engineered biological constructs' performance against design objectives.
- Learn: Analysis of collected data to inform the next design round, with cycles repeating until desired function is achieved [7].
This framework has structured approaches to protein engineering, pathway optimization, and therapeutic development, but faces limitations in speed and predictive power due to its reliance on empirical iteration rather than first-principles prediction.
The Emergence of Learning-Design-Build-Test (LDBT) and Agentic Science
Recent advances in machine learning and autonomous AI systems are driving a fundamental reorganization of this workflow. The proposed LDBT paradigm positions "Learning" at the beginning of the cycle, leveraging pre-trained models and foundational biological knowledge to generate more informed initial designs [7]. This approach leverages the growing success of zero-shot predictions from protein language models and other AI systems that can propose functional biological designs without additional training or experimental data [7].
The integration of Agentic AI transforms this further into a continuous, closed-loop system where AI agents manage the entire discovery process. These agents use LLMs and generative models to feature structured memory for continual learning and employ machine learning tools to incorporate scientific knowledge, biological principles, and theories [6]. This enables a transition toward a "Design-Build-Work" model that relies more heavily on first principles, similar to established engineering disciplines [7].
Table 1: Evolution from DBTL to Agentic Workflows
| Framework | Sequence | Key Characteristics | Role of AI |
|---|---|---|---|
| Traditional DBTL | Design → Build → Test → Learn | Empirical iteration, Human-driven design | Specialized computational tools |
| LDBT | Learn → Design → Build → Test | Zero-shot predictions, Pre-trained models | Machine learning-enhanced design |
| Agentic Science | Continuous autonomous cycling | Full scientific agency, Closed-loop operation | Autonomous AI research partners |
Diagram 1: Evolution from DBTL to Agentic Science
Quantitative Performance of AI-Driven Discovery Platforms
The implementation of AI-driven approaches, particularly in drug discovery, has demonstrated substantial improvements in efficiency and acceleration of early-stage research. Multiple AI-derived small-molecule drug candidates have reached Phase I trials in a fraction of the typical ~5 years needed for traditional discovery and preclinical work [8]. By the end of 2024, over 75 AI-derived molecules had reached clinical stages, representing exponential growth from the first examples appearing around 2018-2020 [8].
Table 2: Performance Metrics of Leading AI-Driven Drug Discovery Platforms
| Company/Platform | Key AI Approach | Reported Efficiency Gains | Clinical Stage Candidates | Notable Achievements |
|---|---|---|---|---|
| Exscientia | Generative AI for small-molecule design, "Centaur Chemist" approach | Design cycles ~70% faster, 10× fewer synthesized compounds; CDK7 inhibitor achieved candidate with only 136 compounds [8] | 8 clinical compounds designed by 2023 [8] | First AI-designed drug (DSP-1181) to enter Phase I trials (2020) [8] |
| Insilico Medicine | Generative AI for target discovery and molecule design | Idiopathic pulmonary fibrosis drug: target discovery to Phase I in 18 months [8] | Multiple candidates in Phase I trials [8] | Demonstrated end-to-end AI acceleration from target identification to clinical candidate [8] |
| Recursion | Phenotypic screening with AI-driven image analysis | Massive scale cellular phenotyping with machine learning classification [8] | Multiple candidates in clinical development [8] | Integrated platform combining biology and AI; merged with Exscientia in 2024 [8] |
| BenevolentAI | Knowledge-graph-driven target discovery | AI-identified novel targets and repurposing opportunities [8] | Several candidates in clinical trials [8] | Knowledge mining from scientific literature and experimental data [8] |
| Schrödinger | Physics-based simulations with machine learning | Combined physical principles with statistical learning for molecular design [8] | Platform used for multiple partnered programs [8] | Integrated computational platform for molecular design [8] |
The efficiency gains demonstrated by these platforms are particularly notable in lead optimization. Exscientia reports in silico design cycles approximately 70% faster and requiring 10× fewer synthesized compounds than industry norms [8]. In one specific example, their CDK7 inhibitor program achieved a clinical candidate after synthesizing only 136 compounds, whereas traditional programs often require thousands [8]. This represents a significant reduction in resource requirements and acceleration of early-stage discovery.
Core Capabilities and Technologies of Agentic AI Systems
Agentic AI systems in scientific discovery integrate multiple advanced capabilities that enable autonomous operation. These systems are characterized by five core capabilities that distinguish them from traditional computational tools:
Structured Memory for Continual Learning: Agentic AI systems maintain organized knowledge repositories that accumulate and integrate information across multiple experimental cycles, enabling progressive improvement and adaptation based on accumulated evidence [6].
Hypothesis Generation and Experimental Design: Using large language models and generative algorithms, these systems can formulate novel research questions and design appropriate experimental approaches to test them, moving beyond pattern recognition to genuine scientific inquiry [5] [6].
Workflow Planning and Execution: Agentic AI can plan multi-step discovery workflows, coordinate experimental processes, and manage resource allocation while adapting to intermediate results and unexpected findings [6].
Self-Assessment and Knowledge Gap Identification: These systems can critically evaluate their own understanding, identify limitations in their knowledge, and proactively design experiments to address those gaps [6].
Integration of Multi-Modal Data and Tools: Agentic AI seamlessly combines diverse data types (genomic, structural, phenotypic) and computational tools (simulation, analysis, prediction) within a unified reasoning framework [5] [6].
Experimental Protocols for AI-Enhanced Drug Discovery
Protocol: Cell-Free Protein Expression for High-Throughput Testing
Purpose: Rapid expression and testing of AI-designed protein variants using cell-free systems to accelerate the Build-Test phases of DBTL cycles [7].
Materials and Reagents:
- Cell-free transcription-translation system (crude lysate or purified components)
- DNA templates encoding target protein variants
- Reaction substrates for functional assays
- Microfluidic device or liquid handling robot
- Detection reagents (fluorogenic or colorimetric substrates)
Procedure:
- DNA Template Preparation: Synthesize DNA sequences encoding AI-designed protein variants without cloning steps [7].
- Reaction Assembly: Combine DNA templates with cell-free expression system components in microtiter plates or microfluidic droplets [7].
- Protein Expression: Incubate reactions at appropriate temperature (typically 30-37°C) for 2-4 hours to express target proteins [7].
- Functional Assay: Directly assay expressed proteins by adding relevant substrates to reactions, measuring output via fluorescence, absorbance, or other detection methods [7].
- Data Collection: Quantify protein function and expression levels using appropriate instrumentation [7].
- Data Integration: Feed results back to AI system for analysis and next-round design [7].
Applications: This protocol has been successfully applied in ultra-high-throughput protein stability mapping (776,000 variants) [7], enzyme engineering through iterative site saturation mutagenesis [7], and antimicrobial peptide screening (500 optimal variants selected from 500,000 computational designs) [7].
Protocol: Closed-Loop AI-Driven Small Molecule Optimization
Purpose: Iterative design and testing of small molecule therapeutics using AI-guided generative chemistry and automated synthesis [8].
Materials and Reagents:
- AI-driven molecular design platform (e.g., Exscientia's DesignStudio)
- Automated synthesis robotics (e.g., Exscientia's AutomationStudio)
- High-throughput screening assays (binding, functional, ADME)
- Target protein or cellular assays
- Compound management system
Procedure:
- Initial Design: AI generates initial compound designs based on target product profile (potency, selectivity, ADME properties) [8].
- Automated Synthesis: Robotics system synthesizes prioritized compounds (typically 100-200 compounds per cycle) [8].
- High-Throughput Testing: Compounds screened against primary target, counterscreens for selectivity, and early ADME assessment [8].
- Data Analysis: AI analyzes structure-activity relationships and identifies key molecular determinants of desired properties [8].
- Iterative Design: AI proposes next-generation compounds incorporating learning from previous cycle [8].
- Candidate Selection: Process repeats until compound meets all criteria for clinical candidate selection [8].
Applications: This approach enabled Exscientia to advance a CDK7 inhibitor to clinical candidate stage with only 136 synthesized compounds, compared to thousands typically required in traditional medicinal chemistry [8].
Diagram 2: Closed-Loop AI-Driven Small Molecule Optimization
Research Reagent Solutions for AI-Enhanced Discovery
Table 3: Essential Research Reagents and Platforms for AI-Driven Discovery
| Reagent/Platform | Function | Application in AI-Enhanced Workflows |
|---|---|---|
| Cell-Free Expression Systems | Protein synthesis without living cells | Enables rapid testing of AI-designed protein variants (>1 g/L in <4 hours); scalable from pL to kL [7] |
| DropAI Microfluidics | Picoliter-scale reaction containers | Allows screening of >100,000 reactions for massive data generation to train AI models [7] |
| Protein Language Models (ESM, ProGen) | Protein sequence and function prediction | Zero-shot prediction of beneficial mutations and protein functions; trained on evolutionary relationships [7] |
| Structure-Based Design Tools (ProteinMPNN) | Protein sequence design from structure | Designs sequences for specific backbones; combined with AlphaFold for 10× increase in design success [7] |
| Stability Prediction Tools (Prethermut, Stability Oracle) | Predicts effects of mutations on protein stability | Identifies stabilizing mutations and eliminates destabilizing variants before synthesis [7] |
| Automated Synthesis Robotics | Compound synthesis and testing | Closes the design-make-test-learn loop with minimal human intervention; enables rapid iteration [8] |
| Phenotypic Screening Platforms | High-content cellular imaging | Generates rich datasets for AI analysis of compound effects in biologically relevant systems [8] |
Implementation Challenges and Future Directions
Despite significant progress, Agentic AI in scientific discovery faces several substantial challenges. A critical question remains whether AI is "truly delivering better success, or just faster failures" [8]. While AI-designed compounds are reaching clinical trials more rapidly, none have yet received regulatory approval, with most programs remaining in early-stage trials [8]. This highlights the need for continued validation of AI-generated candidates in later-stage clinical development.
Additional challenges include:
- Data Quality and Bias: Training data limitations can propagate biases and constrain the chemical or biological space explored by AI systems [8].
- Explainability and Transparency: The "black box" nature of some complex AI models creates challenges for regulatory approval and scientific trust [8].
- Integration with Biological Complexity: Capturing the full complexity of biological systems, including cellular context and organism-level effects, remains difficult [7] [6].
- Regulatory Frameworks: Evolving guidelines from FDA and EMA on AI in drug development require careful navigation [8].
Future directions for Agentic AI in discovery include greater integration of multi-scale biological data, improved physical principles in generative models, and more sophisticated reasoning capabilities for hypothesis generation. As these systems mature, they are poised to transform areas ranging from virtual cell simulation and programmable control of phenotypes to the design of cellular circuits and development of novel therapies [6]. The ongoing merger of AI capabilities with experimental automation, exemplified by the integration of Exscientia's generative chemistry with Recursion's phenomics data, suggests continued acceleration toward more autonomous, efficient, and effective discovery platforms [8].
The paradigm of Design-Build-Test-Learn (DBTL) has long been the cornerstone of iterative engineering in biological sciences, particularly in protein engineering and drug development. The integration of artificial intelligence (AI) is now transforming this cycle into a closed-loop, autonomous research platform [2]. This evolution is powered by core AI agent architectures—ReAct, Reflection, and Multi-Agent Swarm Systems—that automate reasoning, enhance decision-making, and parallelize experimental workflows. By framing these architectures within the DBTL cycle, this article provides researchers and drug development professionals with application notes and protocols to harness AI for accelerated discovery.
A significant shift is emerging from the traditional DBTL cycle to an "LDBT" (Learn-Design-Build-Test) paradigm, where machine learning precedes design [2]. This approach leverages pre-trained models on vast biological datasets to make zero-shot predictions, potentially reducing the need for multiple iterative cycles and moving closer to a "Design-Build-Work" model. AI agent architectures are the computational engines that operationalize this shift, enabling the integration of prior knowledge and automated reasoning directly into the experimental design process.
Core AI Agent Architectures
ReAct (Reasoning + Acting)
The ReAct architecture integrates logical reasoning with actionable steps, allowing an AI agent to interact with its environment strategically.
- Principle of Operation: The agent operates in a loop: it reasons to deduce the next step, acts to execute that step (e.g., using a tool or querying an API), and observes the result, which informs the next cycle of reasoning [9]. This intertwining of thought and action is crucial for tackling complex problems requiring multi-step planning.
- Role in DBTL Platforms: Within a DBTL framework, a ReAct agent can autonomously manage the "Test" and "Learn" phases. For example, upon receiving experimental data ("Observe"), it can reason about the results, act by updating a machine learning model, and then use the refined model to design new variants for the next cycle.
Reflection (Self-Critique and Refinement)
The Reflection architecture equips an agent with a self-critique mechanism, enabling it to evaluate and improve its own outputs or plans before finalizing them.
- Principle of Operation: After generating an initial output (e.g., an experimental design or a piece of code), the agent switches to a "critical" mode. It analyzes its own work against a set of criteria (e.g., feasibility, safety, efficiency) and produces a reflective critique. This critique is then used to revise and refine the original output [10].
- Role in DBTL Platforms: Reflection is paramount for ensuring the quality and reliability of autonomous operations. A reflecting agent can critically assess its proposed designs for protein variants in the "Design" phase, checking for potential stability issues or expression problems, thereby reducing the cost of failed "Build" and "Test" steps.
Multi-Agent Swarm Systems
Multi-agent swarm systems involve multiple specialized AI agents collaborating to solve a problem that is beyond the capability of a single agent [10]. These systems are inspired by collective problem-solving observed in nature and human organizations.
- Principle of Operation: Multiple agents, each with a defined role, expertise, and tools, work together. Their collaboration is orchestrated through specific communication patterns, such as hierarchical, sequential, or concurrent workflows [10] [9].
- Role in DBTL Platforms: A swarm system is ideal for managing the entire, complex DBTL cycle. Different agents can be assigned to specialized sub-tasks—such as experimental design, robotic control, data analysis, and hypothesis generation—working in concert to accelerate the research pace.
Comparative Analysis of Architectures
The table below summarizes the key characteristics, strengths, and ideal use cases for each architecture within a research platform.
Table 1: Comparative Analysis of Core AI Agent Architectures for DBTL Platforms
| Architecture | Core Principle | Key Strengths | Common Use Cases in DBTL | Communication Pattern |
|---|---|---|---|---|
| ReAct | Interleaves chain-of-thought reasoning with actionable steps [9]. | High transparency; handles dynamic environments. | Automated data analysis; guiding single-instrument workflows. | Sequential, model-driven loop. |
| Reflection | Generates self-critique to refine initial outputs. | Improved output quality and reliability; reduces errors. | Validating experimental designs; critiquing code for robotic control. | Sequential, iterative refinement. |
| Multi-Agent Swarm | Specialized agents collaborate under an orchestrated pattern [10] [9]. | Divides complex tasks; enables parallel work; scalable. | Managing end-to-end DBTL cycles; complex problem-solving. | Hierarchical, Sequential, Concurrent, Mesh [10]. |
Multi-Agent Swarm System Patterns for DBTL
Multi-agent systems can be instantiated in several patterns, each suited to different experimental workflows.
Hierarchical Architecture
In this pattern, agents are organized in a tree-like structure. A high-level "orchestrator" agent breaks down a top-level goal (e.g., "improve enzyme activity") and delegates sub-tasks to specialized "worker" agents [10] [9].
- DBTL Application: An orchestrator manages the entire DBTL cycle. It could delegate the "Design" phase to a specialized design agent, the "Build" phase to an agent controlling liquid handlers, and the "Test" phase to an analysis agent, aggregating their results for the "Learn" phase.
The following diagram illustrates the hierarchical flow of tasks from a central orchestrator to specialized agents, which aligns with phases of a DBTL cycle.
Sequential Coordination
This architecture processes tasks in a linear order, where the output of one agent becomes the input for the next [10]. It is analogous to a traditional assembly line.
- DBTL Application: This pattern naturally maps to the classical DBTL cycle. A design agent passes variant sequences to a build agent, who passes physical constructs to a test agent, who finally passes assay data to a learn agent to plan the next cycle.
The DOT script below defines a sequential workflow where output from one specialized agent becomes the input for the next.
Agents as Tools Pattern
This is a specific and practical implementation of a hierarchical system. Specialized AI agents are wrapped as callable "tools" for a central orchestrator agent [9].
- Principle of Operation: The user interacts only with the orchestrator. The orchestrator's large language model (LLM) reads the docstrings of the available agent-tools to decide which specialist to invoke for a given query. The specialist agent executes the task and returns the result to the orchestrator.
- DBTL Application: A researcher can ask the orchestrator, "Design and run an experiment to find a more stable phytase variant." The orchestrator would then call a
protein_design_agent, alab_automation_agentto handle the build and test phases, and adata_analysis_agentto interpret results, seamlessly executing a full DBTL cycle.
Application Notes: Autonomous Enzyme Engineering
A landmark study in Nature Communications (2025) demonstrates the powerful integration of a multi-agent swarm system within a closed-loop DBTL platform for autonomous enzyme engineering [11].
Experimental Objectives and Workflow
The platform's goal was to engineer two enzymes: Arabidopsis thaliana halide methyltransferase (AtHMT) for improved ethyltransferase activity, and Yersinia mollaretii phytase (YmPhytase) for enhanced activity at neutral pH. The workflow integrated AI and robotics within a biofoundry environment, the Illinois Biological Foundry for Advanced Biomanufacturing (iBioFAB) [11].
Table 2: Key Research Reagent Solutions for Autonomous Enzyme Engineering
| Reagent / Solution | Function in the Experimental Workflow |
|---|---|
| Protein LLM (ESM-2) | An unsupervised model used in the "Learn/Design" phase to predict beneficial amino acid substitutions based on evolutionary sequences [11]. |
| Epistasis Model (EVmutation) | An unsupervised model analyzing local homologs to predict the fitness of protein variants, complementing the protein LLM for initial library design [11]. |
| HiFi Assembly Mix | Enzymatic mix for high-fidelity DNA assembly, creating mutant libraries with ~95% accuracy and eliminating the need for intermediate sequencing [11]. |
| Cell-Free Expression System | A rapid, flexible protein synthesis platform enabling high-throughput expression of protein variants without live cells [2] [11]. |
| Automated Assay Reagents | Specific substrates and buffers (e.g., for methyltransferase or phosphatase activity) configured for high-throughput, robotic handling and quantification in microplates [11]. |
Integrated AI and Robotic Protocol
Module 1: Learn & Design
- Step 1.1: The "Learn" phase begins by training a low-N machine learning model on existing variant fitness data [11]. In the first cycle, this is skipped in favor of zero-shot predictions.
- Step 1.2: The "Design" phase uses a combination of a protein LLM (ESM-2) and an epistasis model (EVmutation) to generate a diverse and high-quality initial library of protein variants [11]. For subsequent cycles, the ML model from Step 1.1 is used to propose new variants based on the latest experimental data.
Module 2: Build
- Step 2.1: The designed variant sequences are used to automatically generate instructions for a DNA synthesizer or to design primers for a high-fidelity (HiFi) assembly-based mutagenesis PCR [11].
- Step 2.2: A robotic liquid handler prepares the mutagenesis PCR reactions.
- Step 2.3: The platform executes DpnI digestion, DNA assembly, and high-efficiency transformation into a microbial host in a 96-well format [11].
- Step 2.4: A colony picker robot selects successful transformants and inoculates them into deep-well plates for protein expression.
Module 3: Test
- Step 3.1: After a defined incubation period, a central robotic arm transfers the culture plates to a centrifuge, and then another liquid handler prepares crude cell lysates or purifies the expressed protein.
- Step 3.2: The platform dispenses the lysates and assay reagents into microplates. The enzyme activity assay (e.g., measuring methyltransferase or phosphatase activity) is performed and quantified by a plate reader [11].
- Step 3.3: The raw assay data is automatically processed and stored in a central database.
Module 4: Learn & Consolidate
- Step 4.1: The processed data is used to train or retrain the machine learning model (e.g., a Bayesian optimizer or neural network), updating the understanding of the sequence-function landscape [11].
- Step 4.2: The cycle repeats from Module 1, using the newly trained model to design an optimized library for the next round.
The DOT script below represents the integrated workflow of AI and robotic modules, showing both sequential flow and parallel processes.
Key Experimental Outcomes
The autonomous platform delivered exceptional results within a condensed timeframe, demonstrating the efficiency of integrating AI agents with laboratory automation.
Table 3: Quantitative Outcomes of Autonomous Enzyme Engineering Campaign
| Engineered Enzyme | Engineering Goal | Fold Improvement | Campaign Duration & Scale |
|---|---|---|---|
| AtHMT | Improve substrate preference (Ethyl Iodide) | 90-fold | 4 weeks |
| AtHMT | Improve ethyltransferase activity | 16-fold | (Fewer than 500 variants constructed & characterized per enzyme) [11] |
| YmPhytase | Improve activity at neutral pH | 26-fold | 4 weeks |
The integration of ReAct, Reflection, and Multi-Agent Swarm architectures into DBTL platforms marks a transformative leap toward autonomous research. These AI agent frameworks provide the cognitive backbone for automating complex reasoning, ensuring robust output, and orchestrating collaborative, parallel experimentation. As demonstrated by the autonomous engineering of enzymes, the synergy between AI and robotics within a closed-loop system can drastically accelerate the pace of discovery, reducing a process that traditionally takes months to a matter of weeks. For researchers in drug development and synthetic biology, adopting these architectures is no longer a speculative future but a practical pathway to achieving unprecedented scale, efficiency, and innovation in their experimental workflows.
The emergence of megascale datasets and sophisticated artificial intelligence (AI) models is fundamentally reshaping the synthetic biology and drug development landscape. The traditional Design-Build-Test-Learn (DBTL) cycle, while systematic, often requires multiple, time-intensive iterations to engineer functional biological systems. A significant paradigm shift is now underway, repositioning the "Learn" phase to the forefront of this cycle. This new LDBT (Learn-Design-Build-Test) framework leverages vast, pre-existing datasets and powerful machine learning models to make accurate, zero-shot predictions, thereby streamlining the path to functional designs [7]. In this context, zero-shot learning (ZSL) refers to the capability of AI models to recognize, classify, or generate predictions for categories or tasks they have never explicitly encountered during training, breaking the traditional dependency on extensive, task-specific labeled datasets [12]. This approach is particularly transformative for closed-loop DBTL platforms governed by AI agents, where the initial learning phase can drastically reduce the number of empirical cycles required, accelerating the development of novel therapeutics, enzymes, and biosynthetic pathways.
The Core Components: Megascale Data and Zero-Shot AI
Megascale Datasets: Characteristics and Curation
Megascale datasets are characterized by their unprecedented volume, diversity, and depth, providing the foundational substrate for training robust foundational models in biology. These datasets span genomics, proteomics, transcriptomics, and phenotypic data from millions of biological entities. For zero-shot learning to be effective, the datasets must encompass broad evolutionary and functional information, allowing models to infer deep patterns and relationships.
Table 1: Exemplary Megascale Datasets for Biological Zero-Shot Learning
| Dataset Name | Scale and Scope | Data Modalities | Primary Application in ZSL |
|---|---|---|---|
| LAD (Large-scale Attribute Dataset) [13] | 78,017 images; 230 classes; 359 attributes | Visual images, semantic attributes | Attribute-based classification and generalization to unseen object categories. |
| Protein Sequence Databases (e.g., UniRef) [7] | Millions of protein sequences from across phylogeny | Amino acid sequences, evolutionary relationships | Training protein language models (e.g., ESM, ProGen) for zero-shot function prediction and design. |
| Protein Structure Databases (e.g., PDB) [7] | Hundreds of thousands of experimentally determined structures | 3D atomic coordinates, secondary structure | Training structure-based models (e.g., AlphaFold, RoseTTAFold, ProteinMPNN) for zero-shot structure prediction and sequence design. |
Zero-Shot Learning Mechanisms in Biology
Zero-shot learning operates by leveraging semantic information and relationships between known and unknown classes to make predictions. In a biological context, this translates to several powerful mechanisms [12]:
- Semantic Embeddings and Attribute-Based Classification: Biological entities (e.g., proteins, cell types) are described by a set of human-interpretable attributes or features (e.g., structural motifs, functional domains, solubility, stability). Models are trained to map sequences or structures into a shared semantic space defined by these attributes, enabling them to infer the properties of unseen entities based on their proximity in this space.
- Generative Models: Techniques such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) can generate synthetic examples of unseen classes based on the learned distribution of seen classes. This is particularly useful for creating novel protein variants or chemical compounds that satisfy desired property constraints.
- Transfer Learning: Pre-trained models on massive, general datasets (e.g., all known protein sequences) can be applied with minimal fine-tuning to specialized tasks (e.g., predicting the stability of a specific enzyme family), effectively transferring knowledge from a source domain to a target domain.
Application Notes: Protocols for a Closed-Loop LDBT Platform
Integrating megascale data and zero-shot learning into a closed-loop platform requires a structured experimental and computational workflow. The following protocols and application notes detail this process.
Protocol 1: In silico Protein Engineering via Zero-Shot Prediction
Objective: To design a protein (e.g., an antibody or enzyme) with enhanced properties (e.g., stability, activity) using zero-shot models without initial experimental testing.
Learn (L): Model Selection and Context Priming
- Input: A megascale dataset of protein sequences and/or structures.
- Action: Select and employ a pre-trained protein language model (e.g., ESM-3, ProGen) or a structure-based design tool (e.g., ProteinMPNN, MutCompute). The model has already "learned" the fundamental principles of protein folding and function from its training data [7].
- Output: A foundational model capable of zero-shot inference.
Design (D): Zero-Shot Sequence Generation
- Input: A set of functional constraints and objectives for the target protein (e.g., "stabilize the active site," "maintain binding affinity to antigen X," "increase solubility").
- Action: Use the model to generate novel protein sequences that are predicted to meet the objectives. This can involve sampling from the model's distribution or using it to score and rank a library of candidate sequences. Tools like Stability Oracle or DeepSol can be integrated for specific property predictions [7].
- Output: A computationally designed library of protein variants.
Build (B): Rapid Synthesis with Cell-Free Systems
- Input: The computationally designed DNA sequences.
- Action: Synthesize DNA templates without intermediate cloning steps and express proteins using a cell-free gene expression (CFE) platform. This system leverages cellular machinery in vitro, enabling rapid (hours) and high-throughput protein production, even for potentially toxic proteins [7].
- Output: A physical library of synthesized protein variants.
Test (T): High-Throughput Functional Characterization
- Input: The synthesized protein library.
- Action: Assay protein function using high-throughput methods coupled with CFE, such as fluorescence-based activity assays, cDNA display for stability mapping, or affinity selection. Liquid handling robots and microfluidics can scale testing to hundreds of thousands of variants [7].
- Output: Quantitative functional data for each variant.
Closed-Loop Feedback: The experimental results from the Test phase are fed back into the Learn phase. This new, high-quality data can be used to fine-tune the foundational model, creating a more accurate and specialized AI agent for the next iteration of the cycle, thus closing the loop [7].
Diagram 1: The closed-loop LDBT cycle for protein engineering.
Protocol 2: AI-Driven Antibody-Drug Conjugate (ADC) Target Discovery
Objective: To prioritize novel, tumor-selective antigen targets for ADC development using AI and multi-omics megascale data in a zero-shot manner.
Learn (L): Multi-Omics Data Integration
- Input: Curated megascale datasets including genomic, transcriptomic, proteomic, and clinical data from both tumor and normal tissues.
- Action: Train or utilize a pre-trained AI model (e.g., graph neural networks, deep learning classifiers) to learn the complex patterns distinguishing tumor-specific, internalizing membrane proteins from other proteins [14].
- Output: A predictive model for ideal ADC target properties.
Design (D): Zero-Shot Target Prioritization
- Input: The complete human proteome or a specific set of uncharacterized membrane proteins.
- Action: Use the trained model to score and rank all input proteins based on their predicted "ideality" as an ADC target (e.g., high tumor expression, low normal tissue expression, high predicted internalization). This constitutes a zero-shot prediction for proteins not previously known to be ADC targets [14].
- Output: A shortlist of candidate antigen targets with associated predictive scores.
Build (B): Molecular Tool Generation
- Input: The shortlisted target genes.
- Action: Clone and express the target antigens. Generate candidate antibodies or binding scaffolds against these targets.
- Output: Recombinant antigens and antibody candidates.
Test (T): In vitro and In vivo Validation
- Input: The generated molecular tools.
- Action: Validate target expression via IHC, test antibody binding affinity and specificity, and critically, assess antigen-antibody complex internalization in relevant cell lines. Proceed to in vivo efficacy and safety studies for lead candidates [14].
- Output: Experimental confirmation of target suitability.
Closed-Loop Feedback: Validation results refine the AI model, improving its predictive power for subsequent target discovery campaigns and informing the AI agent's future search strategies.
Table 2: AI Models for Zero-Shot Target Identification in ADC Development [14]
| AI Methodology | Data Sources Utilized | ADC-Specific Challenge Addressed | ZSL Application |
|---|---|---|---|
| Graph Neural Networks (GNNs) | Genomics, transcriptomics, proteomics, molecular structures | Overcoming target heterogeneity and ensuring functional internalization | Predicting internalization efficiency and tumor-selectivity for uncharacterized proteins. |
| Natural Language Processing (NLP) | Scientific literature, patents, clinical trial databases | Aggregating fragmented evidence for novel targets | Inferring functional and expression patterns for less-studied targets from textual data. |
| Deep Learning (CNNs, Autoencoders) | Digital pathology images, multi-omics data | Assessing antigen density and spatial distribution from imaging | Quantifying expression patterns from tissue images for targets not in training data. |
Diagram 2: AI-driven ADC target discovery workflow.
The Scientist's Toolkit: Essential Research Reagents and Platforms
The practical implementation of the LDBT paradigm relies on a suite of specialized reagents, software, and platforms.
Table 3: Key Research Reagent Solutions for Megascale Zero-Shot Learning
| Item / Solution | Function / Application | Example / Specification |
|---|---|---|
| Cell-Free Expression System | Rapid, high-throughput protein synthesis without living cells. Enables Build phase for toxic or complex proteins. | E. coli or HeLa lysate-based systems; protein yields >1 g/L in <4 hours [7]. |
| Pre-trained Protein Language Model | Zero-shot prediction of protein function, stability, and mutation effects. Core of the Learn phase. | ESM-3, ProGen; trained on millions of sequences from UniRef [7]. |
| Structure Prediction & Design Tool | Zero-shot protein structure prediction and sequence design for a given backbone. Core of the Design phase. | AlphaFold2, ProteinMPNN; enables design without experimental structures [7]. |
| Droplet Microfluidics System | Ultra-high-throughput screening of biological assays. Critical for the Test phase at megascale. | Platforms like DropAI for screening >100,000 picoliter-scale reactions [7]. |
| Large-Scale Attribute Dataset | Benchmarking and training ZSL models for visual and semantic tasks in biology. | LAD dataset: 78K images, 230 classes, 359 attributes [13]. |
| AI-Optimized Distributed Training Framework | Training foundational models on megascale datasets across thousands of GPUs. | MegaScale system: achieves >55% Model FLOPs Utilization on 12,288 GPUs [15]. |
The fusion of megascale datasets and zero-shot learning within a reimagined LDBT cycle represents a cornerstone for the next generation of closed-loop, AI-agent-driven research platforms. This approach moves the field from a reliance on iterative, empirical experimentation toward a more predictive, first-principles-based engineering discipline. By establishing a robust data foundation and leveraging the generalized intelligence of models trained on this data, researchers and drug developers can dramatically accelerate the design of novel biological parts, therapeutic candidates, and optimized biosynthetic pathways, ultimately shrinking the timeline from concept to functional validation.
AI Agents in Action: Real-World Applications and Workflow Integration
The early stage of drug discovery, hit identification, aims to find chemical compounds that measurably modulate a biological target and are suitable for optimization into lead compounds [16]. This phase has been transformed by artificial intelligence (AI) and its integration into closed-loop Design-Build-Test-Learn (DBTL) platforms. These platforms use AI agents to autonomously design molecules, simulate their properties, and prioritize experiments, creating a continuous, data-driven cycle that dramatically accelerates research [7] [17] [18].
This article details practical protocols for two core methodologies—virtual screening and de novo molecular design—framed within an agentic AI-driven DBTL workflow. We provide structured data, ready-to-use experimental procedures, and key reagent solutions to enable implementation of these accelerated approaches.
Integrated DBTL Workflow for Hit Identification
The following diagram illustrates the overarching closed-loop DBTL workflow, showing the integration of agentic AI, virtual screening, and de novo design in an automated cycle for hit identification.
Diagram Title: Closed-Loop DBTL Workflow
Virtual Screening Protocols
Virtual screening uses computational methods to prioritize compounds from ultra-large libraries for experimental testing [16]. Integrated into a DBTL cycle, AI agents can autonomously manage this process, from initial docking to selecting compounds for synthesis and testing.
The HIDDEN GEM Protocol for Ultra-Large Library Screening
HIDDEN GEM is a novel methodology that integrates molecular docking, generative modeling, and similarity searching to efficiently identify hits from libraries containing billions of molecules [19].
Workflow and Quantitative Performance
The diagram below details the HIDDEN GEM cycle, which integrates initial docking, generative AI, and similarity searching to efficiently identify high-scoring compounds.
Diagram Title: HIDDEN GEM Screening Cycle
Table 1: HIDDEN GEM Performance Metrics for 16 Protein Targets [19]
| Metric | Result |
|---|---|
| Library Size Screened | 37 billion compounds (Enamine REAL Space) |
| Computational Resource | Single 44 CPU-core machine, one Nvidia GTX 1080 Ti GPU |
| Total Time | ~2 days per target |
| Enrichment Factor | Up to 1000-fold over random screening |
| Compounds Actually Docked | < 600,000 |
Step-by-Step Protocol
Initialization
- Input: Prepared protein structure (PDB format), defined binding site.
- Library: Use a small, diverse initial library like the Enamine Hit Locator Library (HLL, ~460,000 compounds) [19].
- Action: Dock all HLL compounds using software like Smina or AutoDock Vina. Retain the best score per compound.
Generation
- Fine-tuning: Use the top 1% of scoring compounds from Initialization to fine-tune a pre-trained generative model (e.g., a SMILES-based model trained on ChEMBL).
- Filter Model: Train a binary classification model to discriminate the top 1% from the remaining 99%.
- AI Generation: The fine-tuned model generates novel compounds. The filter model selects those predicted to be top-scoring.
- Output: Generate approximately 10,000 unique, novel compounds. This takes ~4 hours on a single NVIDIA GTX 1080 Ti GPU [19].
- Docking: Dock and score all generated compounds.
Similarity Search
- Query: Select up to 1,000 top-scoring compounds from the previous steps.
- Search: Perform a massive chemical similarity search (e.g., Tanimoto similarity) against the ultra-large screening library (e.g., Enamine REAL Space).
- Output: Select the 100,000 most similar, purchasable compounds from the large library. This step requires ~3,600 CPU-core hours [19].
Final Docking and Hit Nomination
- Dock and score the 100,000 selected compounds.
- The top-ranking compounds are nominated as validated virtual hits for the subsequent "Build" and "Test" phases.
Deep Learning-Based Virtual Screening with HydraScreen
HydraScreen is a deep learning-based scoring function that predicts protein-ligand affinity and pose confidence [20].
Workflow
The process involves generating multiple ligand poses and using a convolutional neural network (CNN) ensemble to analyze protein-ligand interactions and predict binding affinity.
Diagram Title: HydraScreen Affinity Prediction
Step-by-Step Protocol
Input Preparation
- Protein: Remove water and ions, add hydrogens and charges, repair truncated side-chains.
- Ligand: Sanitize structures and generate stereoisomers (store up to 16 stereoisomers per compound) [20].
Pose Generation
- Use docking software (e.g., Smina) to generate an ensemble of docked conformations for each protein-ligand pair.
Deep Learning Scoring
- Process each pose through the HydraScreen CNN ensemble.
- The model outputs an affinity estimate and a pose confidence score for each conformation.
Final Affinity Calculation
- Compute a final, aggregate affinity value using a Boltzmann-like average over the entire conformational ensemble [20].
Table 2: Prospective Validation of HydraScreen for IRAK1 Hit Identification [20]
| Metric | Performance |
|---|---|
| Hit Identification Rate | 23.8% of all active compounds found in top 1% of ranked library |
| Library Screened | 46,743 diversity compound library |
| Key Outcome | Identification of 3 potent (nanomolar) scaffolds, 2 of which were novel for IRAK1 |
De Novo Molecular Design Protocols
De novo design uses AI to generate novel molecular structures from scratch, optimized for specific target binding and drug-like properties [21]. Within a DBTL cycle, generative models are continuously refined with experimental data from the "Test" phase.
Core Strategies for De Novo Design
Table 3: De Novo Molecular Design Strategies [21]
| Strategy | Description | Primary DBTL Phase |
|---|---|---|
| Scaffold Hopping | Generating novel core structures while maintaining similar activity to a known hit. | Hit-to-Lead |
| Scaffold Decoration | Adding functional groups to a core scaffold to enhance interactions with the target. | Hit-to-Lead / Optimization |
| Fragment Growing | Expanding a small, validated fragment by adding atoms or functional groups. | Hit Identification |
| Fragment Linking | Joining two or more fragments that bind to different sub-pockets of the target. | Hit Identification |
| Chemical Space Sampling | Selecting a diverse subset of molecules from a vast virtual chemical space (~10^63 molecules) [21]. | Hit Identification |
Protocol for Generative AI-Driven De Novo Design
This protocol can be executed by an AI agent to automatically design new molecules based on experimental feedback.
Model Selection and Training
- Architecture: Choose a generative model architecture such as a Variational Autoencoder (VAE), Generative Adversarial Network (GAN), or a modern Transformer model.
- Pre-training: Pre-train the model on a large corpus of chemical structures (e.g., ChEMBL, ZINC) to learn fundamental chemical rules and structural patterns [22].
Goal-Directed Generation
- Reward Function: Define a multi-parameter reward function for Reinforcement Learning (RL) that incorporates predicted affinity, drug-likeness (e.g., Lipinski's Rule of Five), synthetic accessibility, and target selectivity [22] [21].
- AI Generation: The AI agent uses the generative model to propose new molecules, which are then scored by the reward function. The agent iteratively improves its proposals based on this feedback.
In Silico Validation
- Filters: Apply computational filters to prioritize generated compounds for synthesis. These include:
- ADMET Prediction: Use tools like DeepSol (solubility) or Stability Oracle (protein stability) to predict key properties [7].
- Pan-Assay Interference Compounds (PAINS) Filtering: Remove compounds with known promiscuous, non-selective motifs [20].
- Docking: Perform molecular docking as a preliminary check for binding mode and affinity.
- Filters: Apply computational filters to prioritize generated compounds for synthesis. These include:
Iterative DBTL Integration
- The top-ranked virtual compounds proceed to the "Build" phase (synthesis).
- Synthesized compounds are then "Tested" in biochemical or cellular assays.
- The resulting data is fed back into the "Learn" phase to retrain and refine the generative model, closing the loop and improving the next round of design [18].
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 4: Key Reagents and Tools for Accelerated Hit Identification
| Item / Resource | Function / Application |
|---|---|
| Ultra-Large Make-on-Demand Libraries (Enamine REAL Space, eMolecules eXplore) | Provide access to billions of synthesizable compounds for virtual screening [19]. |
| Diverse Screening Libraries (Enamine Hit Locator Library - HLL) | Smaller, curated libraries used for initial docking in workflows like HIDDEN GEM [19]. |
| DNA-Encoded Libraries (DELs) | Enable experimental screening of millions to billions of compounds in a single tube via affinity selection and NGS readout [16]. |
| Cloud-Based Robotic Labs (Strateos Cloud Lab) | Provide remote, automated platforms for high-throughput compound synthesis and testing, integrating with DBTL workflows [20]. |
| Cell-Free Expression Systems | Enable rapid, high-throughput synthesis and testing of proteins without the need for live cells, accelerating the "Build" and "Test" phases [7]. |
| Generative AI Platforms (e.g., for VAE, GAN, RL) | Core software for de novo molecular design, integrating with DBTL cycles for continuous learning [22] [21]. |
| Knowledge Graphs (e.g., Ro5's SpectraView) | Data systems that integrate biomedical data from publications, patents, and databases to aid in target evaluation and prioritization [20]. |
The integration of artificial intelligence (AI) into biological design is fundamentally reshaping the discovery and development of therapeutic proteins and antibodies. This paradigm moves beyond traditional, linear Design-Build-Test-Learn (DBTL) cycles to a more dynamic, AI-agent-driven closed-loop feedback system, often termed LDBT (Learn-Design-Build-Test). This framework leverages AI to learn from vast biological datasets, design novel biomolecules in silico, and rapidly validate them through high-throughput experiments, with data from each cycle feeding back to refine the AI models. This application note details the core protocols, quantitative results, and essential reagents driving this transformative approach, providing a practical resource for researchers and drug development professionals.
The Shift from DBTL to Closed-Loop LDBT
The conventional DBTL cycle, while effective, is often sequential and slow. The integration of AI proposes a paradigm shift to LDBT, where "Learning" precedes "Design" [7]. In this model, pre-trained AI models, informed by massive datasets, perform zero-shot predictions to generate initial designs, drastically accelerating the initial design phase and reducing reliance on iterative physical screening [7]. The "Build" and "Test" phases are accelerated using technologies like cell-free expression systems and yeast display, enabling megascale data generation [7]. This creates a closed-loop feedback system where experimental results continuously refine and improve the AI models, creating a self-optimizing discovery engine [7] [17].
The following diagram illustrates the workflow of this integrated, AI-agent-driven closed-loop system.
Quantitative Results in AI-Driven Therapeutic Protein Design
Recent breakthroughs demonstrate the efficacy of AI-driven platforms. The table below summarizes key performance metrics from published studies and industry partnerships as of 2025.
Table 1: Performance Metrics of AI-Designed Therapeutic Proteins and Antibodies
| Therapeutic Molecule / Platform | Target | Key AI Technology | Reported Affinity/Performance | Experimental Validation Method |
|---|---|---|---|---|
| De novo VHHs [23] | Influenza haemagglutinin, C. difficile toxin B (TcdB) | Fine-tuned RFdiffusion, ProteinMPNN | Initial designs: tens-hundreds of nM KD After maturation: single-digit nM KD | Yeast surface display, SPR, Cryo-EM |
| De novo scFvs [23] | TcdB, PHOX2B peptide–MHC | Fine-tuned RFdiffusion, ProteinMPNN | Binding confirmed, atomic-level accuracy of all six CDR loops | Cryo-EM |
| AI-designed Enzymes (IDT & Profluent) [24] | Various (Oncology, Epigenetics) | Profluent Bio's ProGen3 models | Accelerated development of "next-generation enzymes" | Proprietary enzymology validation & manufacturing |
| Small Molecule (Exscientia) [8] | CDK7 (Oncology) | Generative AI Design Platform | Clinical candidate from 136 synthesized compounds (vs. thousands typically) | Phase I/II clinical trials |
Detailed Experimental Protocols for AI-Driven Design
This section outlines a standardized protocol for the de novo design of antibodies, such as single-chain variable fragments (scFvs) and single-domain antibodies (VHHs), using a fine-tuned RFdiffusion network, as validated in recent landmark studies [23].
Protocol:De NovoAntibody Design via RFdiffusion
Principle: This protocol utilizes a RFdiffusion network, fine-tuned on antibody-antigen complex structures, to generate novel antibody variable regions that bind a user-specified epitope on a target antigen with atomic-level precision. The process keeps the framework region of the antibody constant while designing novel complementarity-determining region (CDR) loops and the overall binding orientation [23].
Workflow Overview:
- Learn (AI Pre-training & Conditioning): The RFdiffusion model, pre-trained on protein structures, is fine-tuned on antibody complex structures. For a new design, the target protein structure and a desired framework region are provided as conditioning inputs.
- Design (In Silico Generation): The conditioned model generates thousands of novel antibody structures. ProteinMPNN is then used to design sequences for these backbone structures.
- Build (Construct Synthesis): DNA sequences encoding the top-ranked designs are synthesized and cloned into expression vectors (e.g., for yeast display or bacterial expression).
- Test (Experimental Validation): Designed antibodies are expressed and tested for binding and affinity. High-resolution structural validation (e.g., Cryo-EM) confirms binding pose accuracy.
Materials and Equipment:
- Hardware: High-performance computing cluster with multiple GPUs.
- Software: Fine-tuned RFdiffusion, ProteinMPNN, RoseTTAFold2 (fine-tuned for antibody validation) [23].
- Target Data: High-resolution 3D structure of the target antigen (PDB file or AlphaFold2 prediction). Definition of target epitope residues.
- Biological Reagents: (See Section 5: "The Scientist's Toolkit" for a detailed list).
Step-by-Step Procedure:
Part A: Learn & Design (In Silico Phase)
- Input Preparation: Prepare a PDB file of the target antigen and a list of residue numbers defining the epitope of interest. Select a stable, humanized antibody framework (e.g., h-NbBcII10FGLA for VHHs [23]).
- Condition RFdiffusion: Input the target structure, epitope "hotspot" residues, and the framework structure into the fine-tuned RFdiffusion model. The framework is provided in a global-frame-invariant manner using the template track, allowing the model to design both CDR loops and the rigid-body docking orientation [23].
- Generate Structures: Run RFdiffusion to generate a large library (e.g., 10,000-100,000) of de novo antibody variable region structures bound to the target.
- Design Sequences: For each generated backbone structure, use ProteinMPNN to design a sequence that is likely to fold into that structure. This results in a library of candidate antibody sequences.
- In Silico Filtering: Filter the designed sequences using a fine-tuned RoseTTAFold2 network. This network, provided with the target structure and epitope, re-predicts the structure of the designed antibody-antigen complex. Designs with high predicted confidence (self-consistency with the original design) and low predicted cross-reactivity are selected for experimental testing [23].
Part B: Build & Test (Experimental Phase)
- DNA Synthesis and Cloning: Synthesize DNA sequences encoding the top 100-500 filtered designs. Clone these sequences into an appropriate expression vector (e.g., for yeast surface display or bacterial expression).
- High-Throughput Screening: For scFvs or VHHs, use yeast surface display to screen for binders. Induce expression of the designed antibodies on the yeast surface and label with fluorescently-tagged antigen. Use fluorescence-activated cell sorting (FACS) to isolate yeast populations displaying antigen-binding antibodies [23].
- Affinity Measurement: Express and purify positive hits from E. coli or mammalian systems. Determine binding affinity (KD) using surface plasmon resonance (SPR) or bio-layer interferometry (BLI).
- Affinity Maturation (if needed): For designs with modest affinity, employ an affinity maturation process. This can be done using continuous evolution systems like OrthoRep to generate higher-affinity binders (e.g., moving from nanomolar to single-digit nanomolar KD) while maintaining epitope selectivity [23].
- Structural Validation: To confirm atomic-level accuracy, determine the high-resolution structure of the designed antibody in complex with its antigen using cryo-electron microscopy (cryo-EM) or X-ray crystallography. Compare the experimental structure with the computational model [23] [25].
Integrated Closed-Loop System Architecture
For an AI-driven discovery platform to function as a true closed-loop system, the computational and experimental components must be seamlessly integrated. The following diagram outlines the architecture of such a system, as exemplified by platforms like the Digital Catalysis Platform (DigCat) [17] and industry partnerships [24].
The Scientist's Toolkit: Research Reagent Solutions
Successful execution of these protocols relies on a suite of specialized reagents and computational tools. The following table catalogs essential solutions for AI-driven therapeutic protein design.
Table 2: Essential Research Reagents and Tools for AI-Driven Protein Design
| Item Name | Function/Application | Specific Example / Vendor |
|---|---|---|
| Fine-tuned RFdiffusion | Generative AI model for creating de novo antibody and protein structures bound to a specified target. | Custom fine-tuned version as described in [23]; available from academic sources (e.g., Baker Lab/IPD). |
| ProteinMPNN | AI-based protein sequence design tool that predicts sequences for a given protein backbone structure. | Publicly available; used for designing sequences for RFdiffusion-generated backbones [23] [7]. |
| RoseTTAFold2 (Fine-tuned) | AI structure prediction tool, fine-tuned on antibody complexes, used for in silico validation and filtering of designs. | Custom fine-tuned version for antibody-antigen complex prediction [23]. |
| Yeast Surface Display System | High-throughput platform for screening and isolating antibody binders from large libraries. | Commercial systems available; used for screening ~9,000 AI-designed VHHs/scFvs per target [23]. |
| Cell-Free Protein Synthesis System | Rapid, in vitro expression system for protein production without living cells, accelerating the Build-Test phases. | Various commercial kits (e.g., based on E. coli lysate); enables mg/mL yields in hours for testing [7]. |
| Surface Plasmon Resonance (SPR) | Label-free technique for quantifying binding kinetics (KD, kon, koff) of designed proteins. | Instruments from vendors like Cytiva (Biacore) or Sartorius (Octet); used for affinity measurement of purified binders [23]. |
| Humanized VHH Framework | A stable, optimized single-domain antibody scaffold used as a starting framework for de novo VHH design. | e.g., h-NbBcII10FGLA framework [23]. |
| OrthoRep System | A yeast-based platform for continuous in vivo mutagenesis and evolution, used for affinity maturation of initial designs. | Used to mature initial AI-designed VHHs from nanomolar to single-digit nanomolar affinity [23]. |
The integration of robotic platforms and cell-free systems is revolutionizing high-throughput testing, creating a foundation for fully autonomous research environments. This synergy is pivotal for operationalizing the closed-loop Design-Build-Test-Learn (DBTL) paradigm, where artificial intelligence (AI) agents direct experimental workflows with minimal human intervention [26]. Wet-lab automation has evolved from simple robotic liquid handlers to sophisticated, interconnected systems capable of executing complex experimental protocols. When combined with the speed and flexibility of cell-free protein synthesis (CFPS), these platforms enable an unprecedented scale of experimentation, allowing for the rapid exploration of biological hypotheses. This article details the application of these technologies within AI-driven discovery platforms, providing specific protocols and resource guides to implement these systems in modern research and drug development pipelines.
Robotic Platforms for High-Throughput Testing
Core Components of an Automated Workstation
A high-throughput screening (HTS) robotics laboratory is typically built around an integrated system of components designed to handle microtiter plates (e.g., 96, 384, or 1536-well formats) [27] [28]. These systems minimize hands-on time, enhance data quality, and reduce reagent waste by using smaller amounts of materials [28]. A standard platform includes:
- Liquid Handling Robots: These are the core workhorses for pipetting. Modern systems employ acoustic dispensing and pressure-driven methods for nanoliter-precision transfer, making workflows incredibly fast and less error-prone compared to manual pipetting [27].
- Robotic Arms: These transport microtiter plates between different stations on the platform, creating a seamless, end-to-end automated workflow [28].
- Plate Readers and Imaging Systems: These devices capture experimental outcomes. The trend has moved from simple absorbance readouts to high-content imaging (HCI) that can capture multi-parametric data on cell morphology, signaling, and other phenotypic changes [27].
- Integrated Software: A central software suite schedules and coordinates all instruments via a robotic arm, ensuring robust and reliable operation [11].
Application Note: Automated Clone Screening
Objective: To automate the screening of thousands of microbial or mammalian clones for a target protein or gene of interest, significantly reducing laborious manual methods and creating a unified data repository [29].
Protocol:
- Target Identification: Begin with a defined target—a receptor, protein, or gene in a biological pathway.
- Automated Culture Inoculation: A robotic arm picks and transfers colonies from an agar plate into deep-well plates containing growth medium.
- Liquid Handling for Induction: After a growth period, a liquid handler automatically adds inducters to trigger protein expression.
- Sample Preparation: The system harvests cells and performs lysis to release the target protein for analysis.
- Assay and Analysis: The robotic arm moves the assay plate to a plate reader or imager for automated quantification of the target's activity or expression.
- Data Centralization: All data from multiple processes are automatically pulled into a central software repository for analysis and decision-making [29].
Cell-Free Systems as an Enabling Technology
Cell-free protein synthesis (CFPS) systems have emerged as a powerful tool for high-throughput testing because they bypass the need for live cells, offering unparalleled speed and flexibility [2] [30]. These systems utilize the protein biosynthesis machinery from cell lysates (e.g., E. coli, yeast, mammalian) or purified components to activate in vitro transcription and translation [30].
Key Advantages for High-Throughput Workflows:
- Rapid Protein Production: Achieve high-yield protein synthesis (>1 g/L) in less than 4 hours, without the time-consuming steps of cloning and transformation [2].
- Direct DNA Template Use: Synthesized DNA templates can be added directly to CFPS reactions, drastically accelerating the testing cycle [2].
- Tolerance to Toxicity: CFPS can express proteins that would be toxic to a living cell, expanding the range of testable molecules [30].
- Ultra-Miniaturization: Reactions can be scaled down to picoliter volumes, enabling the testing of millions of conditions in a single campaign [2] [31].
Integrated Experimental Protocols
This section provides a detailed methodology for implementing a closed-loop DBTL cycle for protein engineering, leveraging robotic automation and cell-free systems.
Protocol 1: Automated, Cell-Free Protein Engineering Cycle
Objective: To autonomously engineer a protein for a desired function (e.g., improved enzyme thermostability) through iterative, AI-directed DBTL cycles. This protocol is based on the SAMPLE (Self-driving Autonomous Machines for Protein Landscape Exploration) platform and the Illinois Biological Foundry for Advanced Biomanufacturing (iBioFAB) [31] [11].
The Scientist's Toolkit: Key Research Reagent Solutions
| Component | Function in the Protocol | Specific Example / Note |
|---|---|---|
| BL-7S Plasmids [30] | Overexpress a subset of translation factors in a specialized, high-yield CFPS system. | Found in Addgene (https://www.addgene.org/Cheemeng_Tan/). |
| Amino Acid Mixture [30] | Provides building blocks for in vitro protein synthesis. | A pre-mixed solution of all 20 standard amino acids. |
| Nucleotide Triphosphates (ATP, GTP, UTP, CTP) [30] | Provides energy and substrates for transcription and translation. | Critical for the CFPS reaction supplement. |
| Creatine Phosphate & Kinase [30] | An energy regeneration system to sustain prolonged protein synthesis. | Maintains ATP levels in the cell-free reaction. |
| Liquid Handling Robot | Automates all pipetting steps for nanoliter to microliter volumes. | Enables high-throughput assembly of CFPS reactions. |
| Microfluidic Dispenser | Allows for ultra-low-volume (nanoliter) reaction assembly to conserve precious reagents. | e.g., μCD (microfluidic cap-to-dispense) system [30]. |
| Robotic Arm | Integrates individual instruments (thermocyclers, incubators, plate readers) into a single workflow. | Physically moves plates between stations without human intervention. |
Detailed Methodology:
Module 1: AI-Driven Design and DNA Construction (Build)
- Design: An AI agent (e.g., using a protein language model like ESM-2 or a Bayesian optimization algorithm) analyzes existing data and proposes a library of protein sequence variants to test next [31] [11].
- DNA Assembly: The robotic system executes an automated mutagenesis PCR protocol to construct the designed variants.
- The system prepares PCR reactions in a 96-well plate format using a liquid handler.
- Following PCR, a DpnI digestion step is performed to eliminate the template DNA.
- The assembled DNA is then amplified via polymerase chain reaction (PCR). The success of gene assembly and PCR is verified in real-time using a fluorescent dye like EvaGreen [31].
Module 2: Cell-Free Protein Synthesis (Test)
- Reaction Assembly: A liquid handling robot or a specialized microfluidic printer (e.g., the μCD system) dispenses nanoliter volumes of the CFPS reaction supplement and the amplified DNA expression cassettes into assay plates [30] [31]. This step is performed with high accuracy to create hundreds of unique reactions.
- Protein Expression: The plate is incubated at a controlled temperature (e.g., 30-37°C) for a defined period (typically 3-6 hours) to allow for protein synthesis [31].
Module 3: Automated Functional Assay (Test)
- Assay Initiation: The robotic arm moves the plate from the incubator to a liquid handler, which adds the appropriate substrates and buffers to initiate the enzyme activity assay.
- Activity Measurement: The plate is transferred to a plate reader, which performs a colorimetric or fluorescent readout of the enzyme's function over time. For thermostability screening, the system may heat the samples and measure the loss of activity (T50) to determine melting curves [31].
Module 4: Data Analysis and Learning
- Data Processing: The raw data from the plate reader is automatically processed and formatted.
- Model Update: This new experimental data—linking protein sequence to functional output—is fed back to the AI agent. The agent updates its internal model (e.g., a Gaussian Process model) to refine its understanding of the sequence-function landscape [31].
- New Cycle: The updated AI agent then designs a new, more informed set of protein variants, and the cycle repeats autonomously.
Workflow Visualization
The following diagram illustrates the integrated, closed-loop workflow described in the protocol.
Quantitative Performance of Autonomous Platforms
The efficiency gains from integrating these technologies are quantifiable. The table below summarizes published performance metrics from recent autonomous protein engineering campaigns.
Table 1: Performance Metrics of AI-Powered, Automated Platforms
| Platform / Study | Engineering Goal | Key Quantitative Outcome | Timeframe & Scale |
|---|---|---|---|
| SAMPLE Platform [31] | Improve glycoside hydrolase thermal tolerance. | Identified enzymes >12°C more stable than starting sequences. | Agents converged on optima after testing <2% of the full sequence landscape. |
| iBioFAB Platform [11] | Improve substrate preference and activity of two distinct enzymes (AtHMT & YmPhytase). | 90-fold improvement in substrate preference; 16-26 fold improvement in activity. | 4 rounds of engineering completed in 4 weeks, testing <500 variants per enzyme. |
| Generalized AI Platform [8] | Accelerate small-molecule drug discovery. | Achieved clinical candidate after synthesizing only 136 compounds (vs. thousands typically). | Compressed target-to-candidate timeline to ~18 months in a reported case. |
Integration with Closed-Loop DBTL and AI Agents
The true power of wet-lab automation is realized when it is embedded within a closed-loop DBTL framework managed by an AI agent. In this paradigm, the "Learn" phase is not just a passive analysis step but the driver of the entire cycle [2]. We propose a shift from the classic DBTL to an LDBT (Learn-Design-Build-Test) cycle, where machine learning models that have been pre-trained on vast biological datasets precede and guide the initial design, potentially leading to functional solutions in a single cycle [2].
Visualization of the LDBT Paradigm Shift
The following diagram contrasts the traditional and emerging paradigms.
In this LDBT framework, cloud-based AI agents can power a global closed-loop feedback system. For example, the Digital Catalysis Platform (DigCat) demonstrates this by using an AI agent to propose new catalysts, which are then synthesized and tested by automated platforms worldwide. The resulting experimental data is fed back into the cloud platform to continuously improve the AI models, creating a global knowledge cycle [17].
The confluence of robotic wet-lab automation and cell-free systems has created a powerful engine for high-throughput testing. This combination provides the physical infrastructure necessary to realize the vision of fully autonomous research laboratories. By implementing the detailed protocols and leveraging the specialized toolkits outlined in this article, researchers can construct platforms capable of executing self-driving scientific discovery. These systems, governed by intelligent AI agents in a closed-loop LDBT cycle, are already demonstrating dramatic accelerations in the pace of engineering proteins and discovering new therapeutics, marking a transformative shift in the operational methodology of modern biology and drug development.
Application Note
This application note provides a detailed protocol for implementing a closed-loop Design-Build-Test-Learn (DBTL) platform, powered by artificial intelligence (AI) agents, to accelerate drug discovery from target identification to the Investigational New Drug (IND) application stage. The paradigm of AI-driven drug discovery represents a fundamental shift from traditional, linear workflows to an integrated, iterative process that can drastically compress development timelines. By leveraging AI agents that reason, plan, and act upon vast datasets and specialized tools, research and development (R&D) efficiency is significantly enhanced [32] [33]. This document deconstructs a landmark case—the 18-month journey of an AI-discovered idiopathic pulmonary fibrosis (IPF) drug candidate, INS018_055, developed by Insilico Medicine [8] [34]. We outline the core principles, experimental protocols, and reagent solutions that enabled this achievement, providing a reproducible framework for researchers and drug development professionals.
A closed-loop DBTL platform, orchestrated by AI agents, is a system where the output of one cycle directly and automatically informs the input of the next. This creates a continuous, self-improving discovery engine. AI agents are software programs that can interact with their environment, collect data, and use that information to perform self-determined tasks to meet a predetermined goal with a degree of autonomy [35]. In drug discovery, these agents can manage specialized tasks such as target identification, compound generation, and experimental planning, often interacting with other agents under the supervision of an orchestrating agent with an overarching goal [35].
The core components of such a platform include:
- Design: AI agents use generative models and reasoning to propose novel molecular structures that satisfy a multi-parameter target product profile (TPP) [32] [22].
- Build: The designed molecules are synthesized, either virtually (for prioritization) or physically via automated, robotics-mediated laboratories [8].
- Test: AI agents coordinate in silico, in vitro, and ex vivo assays—including high-content phenotypic screening on patient-derived samples—to generate robust biological data [8] [22].
- Learn: ML models analyze the test results to identify patterns and refine the molecular design rules, thereby closing the loop and initiating the next, optimized cycle [8] [36].
Case Study: Insilico Medicine's INS018_055
Insilico Medicine's generative-AI-designed drug for idiopathic pulmonary fibrosis (IPF) progressed from target discovery to Phase I clinical trials in just 18 months, a fraction of the typical 5-year timeline for traditional discovery and preclinical work [8]. This program serves as a validated proof-of-concept for the closed-loop, AI-agent-driven approach. The drug candidate, INS018_055, a small molecule targeting TNIK, has since advanced to Phase IIa trials [34]. This acceleration was achieved by leveraging an end-to-end AI platform that compressed the design-make-test-learn cycle, demonstrating the potential of AI to redefine the speed and scale of modern pharmacology [8].
Protocols
Protocol 1: AI-Driven Target Identification and Validation
This protocol details the use of AI agents for the initial identification and validation of a novel therapeutic target.
2.1.1 Primary Materials and Reagents
- AI Agent Platform: A computational framework like ToolUniverse, capable of connecting AI agents to hundreds of scientific tools, databases, and ML models [32].
- Biological and Chemical Databases: Access to comprehensive, curated databases such as PubChem, ChemBank, DrugBank, ChEMBL, and genomic/proteomic data repositories [36] [32].
- Literature Mining Tools: Natural Language Processing (NLP) agents configured to read and comprehend scientific literature, clinical trial registries (e.g., ClinicalTrials.gov), and patent databases to identify potential targets and existing knowledge [32] [33].
2.1.2 Experimental Procedure
- Hypothesis Generation: The AI agent is prompted with a high-level goal (e.g., "Identify novel targets involved in IPF pathogenesis"). The agent uses its Tool Manager to access literature review and profiling tools, scanning biomedical literature and omics data to generate a list of candidate proteins and pathways [32].
- Target Prioritization: The agent employs specialized tools to analyze the candidate list. This includes examining gene expression patterns across tissues (e.g., to assess potential for off-target effects), analyzing drug-target interaction networks, and leveraging knowledge graphs to understand the biological context of each target [32] [34].
- Starting Compound Association: The agent queries chemical databases to retrieve known drugs or compounds that act on the prioritized target (e.g., HMG-CoA reductase for cholesterol-lowering drugs). This establishes a starting point for chemical optimization [32].
- Validation and Output: The AI agent produces a comprehensive report on the top-ranked target, including its biological rationale, association with the disease, and a preliminary assessment of its "druggability."
Diagram 1: AI-Driven Target Identification Workflow.
Protocol 2: Generative Chemistry and Multi-Parameter Optimization
This protocol covers the de novo design and iterative optimization of lead compounds using generative AI within a closed loop.
2.2.1 Primary Materials and Reagents
- Generative Models: Access to advanced AI architectures such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), or transformer-based models trained on large chemical libraries (e.g., >10^60 molecules) [36] [22].
- Predictive AI Models: Tools for Quantitative Structure-Activity Relationship (QSAR) modeling, ADMET (Absorption, Distribution, Metabolism, Excretion, Toxicity) prediction (e.g., ADMET-AI, Boltz-2 for binding affinity), and synthetic accessibility scoring [32] [22] [34].
- Reinforcement Learning (RL) Framework: An environment where an AI "agent" can iteratively propose molecular structures and receive "rewards" for optimizing properties like binding affinity, selectivity, and solubility [22] [34].
2.2.2 Experimental Procedure
- Define Target Product Profile (TPP): Establish a detailed TPP with ideal and minimum thresholds for key attributes: potency (e.g., IC50), selectivity, ADMET properties, and physicochemical parameters (e.g., logP, solubility) [37].
- De Novo Molecular Generation: Use generative AI models (e.g., GANs, VAEs) to create novel molecular structures in silico that are not present in existing databases but are predicted to bind to the validated target [22].
- Virtual Screening and Ranking: Screen the generated library against the TPP using a battery of predictive AI models. This includes:
- Iterative Optimization via Reinforcement Learning (RL): The AI agent acts in an RL environment. It proposes a molecule (action), receives a score based on the TPP (reward), and updates its strategy to generate improved compounds in the next cycle. This loop continues until candidates meet the pre-defined optimization criteria [22] [34].
- Output: A shortlist of optimized, synthetically accessible lead compounds ready for in vitro testing.
Table 1: Key AI Models for Compound Optimization
| AI Model Type | Primary Function | Example Tools/Architectures |
|---|---|---|
| Generative Adversarial Network (GAN) | Generates novel, drug-like molecular structures | GAN, Wasserstein-GAN [22] |
| Variational Autoencoder (VAE) | Learns a compressed chemical space for molecule generation and optimization | VAE [22] |
| Reinforcement Learning (RL) | Iteratively optimizes molecules for multi-parameter goals | Deep Q-Learning, Actor-Critic Methods [22] [34] |
| Convolutional Neural Network (CNN) | Predicts bioactivity and ADMET properties from molecular structures | CNN, Deep Neural Networks (DNNs) [36] [22] |
| Random Forest (RF) | Classifies compounds and predicts activity in QSAR modeling | RF [36] [34] |
Protocol 3: Integrated In Silico and Ex Vivo Validation
This protocol describes a hybrid validation approach that combines high-fidelity computational predictions with biologically relevant ex vivo testing.
2.2.1 Primary Materials and Reagents
- Physics-Based Simulation Tools: Software for molecular docking, molecular dynamics (MD) simulations, and binding free energy calculations (e.g., Schrödinger's suite) [8] [34].
- Phenotypic Screening Platform: Access to high-content imaging systems and automated, robotics-mediated laboratories (e.g., "AutomationStudio") for in vitro assay [8].
- Patient-Derived Biological Samples: Biobanked patient tissue samples or primary cells (e.g., patient-derived tumor samples for oncology candidates) for ex vivo testing to enhance translational relevance [8].
2.2.2 Experimental Procedure
- High-Fidelity Binding Confirmation: Subject the top AI-designed candidates to rigorous molecular docking and MD simulations to confirm stable binding modes and interactions with the target protein and to rule out potential liabilities [34].
- In Vitro Potency and Selectivity Assay: Synthesize the top-ranked compounds and test them in target-specific biochemical and cell-based assays to confirm potency and selectivity.
- Ex Vivo Efficacy Testing: Test the compounds in more complex, biologically relevant systems. For example, using patient-derived cell or tissue models (e.g., patient tumor samples treated ex vivo) can provide critical insights into efficacy in a human context [8].
- Data Integration and Loop Closure: The results from all validation steps are fed back into the AI platform's learning module. The ML models are retrained on this new, high-quality data, refining their predictive accuracy for the subsequent design cycle and closing the DBTL loop [8] [36].
Diagram 2: The Closed-Loop DBTL Cycle.
Protocol 4: IND-Enabling Studies and Regulatory Strategy
This protocol frames the pre-IND and IND application process as a strategic, AI-informed opportunity rather than a mere regulatory hurdle [37].
2.4.1 Primary Materials and Reagents
- Regulatory Guidance Databases: Digitized and AI-accessible versions of FDA, EMA, and other relevant regulatory guidelines.
- Automated Document Generation Systems: AI agents capable of assembling and formatting the vast documentation required for an IND submission, including the CMC (Chemistry, Manufacturing, and Controls), non-clinical pharmacology, and toxicology sections [35].
- Predictive Toxicological Models: Advanced in silico tools and in vitro models (e.g., organ-on-chip) qualified under initiatives like the FDA Modernization Act 3.0 to predict human-relevant toxicity [22].
2.4.2 Experimental Procedure
- Early Regulatory Engagement: Leverage the pre-IND meeting with regulatory agencies to present the AI-driven product narrative and development plan, seeking alignment on key elements such as the TPP and biomarker strategy [37].
- AI-Optimized Study Design: Use AI agents to design efficient and predictive IND-enabling studies. This includes using statistical planning agents to ensure robust study power and "intelligent clinical-trial design" agents to model trial outcomes [35].
- Compilation and Submission: Utilize AI agents to automate the compilation of the IND application, ensuring consistency, accuracy, and completeness across all modules. The successful IND submission validates the entire discovery platform and transforms the candidate into a corporate asset [37].
The Scientist's Toolkit
Table 2: Essential Research Reagent Solutions for an AI-Driven DBTL Platform
| Tool Category | Example | Function in the Workflow |
|---|---|---|
| AI Agent Platform | ToolUniverse [32] | Provides an environment for AI agents to interact with hundreds of scientific tools, databases, and models, enabling end-to-end workflow execution. |
| Generative Chemistry | GANs & VAEs [22] | Core AI architectures for the de novo design of novel molecular structures with desired properties. |
| Predictive ADMET Model | ADMET-AI [32] | Predicts absorption, distribution, metabolism, excretion, and toxicity of candidate molecules early in the design phase, de-risking candidates. |
| Binding Affinity Predictor | Boltz-2 [32] | Estimates the strength of interaction between a small molecule and its target protein, a key metric for potency. |
| Chemical Database | ChEMBL [32] | A large, open-access database of bioactive molecules with drug-like properties, used for training AI models and finding starting points for design. |
| Automated Synthesis Lab | AutomationStudio [8] | A robotics-mediated laboratory that physically synthesizes AI-designed molecules, closing the "Build" phase of the DBTL loop. |
| High-Content Screening | Ex Vivo Patient Sample Testing [8] | Uses patient-derived biological samples to test compound efficacy in a clinically relevant model, improving translational predictions. |
The case of INS018_055's 18-month path to IND demonstrates that AI-agent-driven closed-loop DBTL platforms are no longer a theoretical concept but a practical and powerful reality in modern drug discovery. By integrating reasoning AI with automated experimental systems, this approach achieves unprecedented compression of early-stage timelines and enhances the precision of candidate selection. The protocols and tools detailed herein provide a foundational roadmap for research organizations aiming to adopt this transformative paradigm, ultimately accelerating the delivery of effective therapeutics to patients.
Navigating Implementation: Challenges and Strategies for Optimizing AI-Driven Platforms
The advent of closed-loop Design-Build-Test-Learn (DBTL) platforms, powered by artificial intelligence (AI), signals a paradigm shift in drug discovery, compressing timelines that traditionally spanned years into mere months [8]. These platforms operate through iterative cycles: AI agents design novel molecular structures, robotics platforms build and synthesize these compounds, and high-throughput systems test them, generating vast data streams that the AI subsequently learns from to inform the next design cycle [8]. However, the performance and reliability of these platforms are critically dependent on the quality of their training data. This application note addresses the central data-centric challenges—heterogeneity, quality, and bias—that can compromise the efficacy of AI-driven DBTL platforms. We provide detailed protocols and analytical frameworks to help researchers and drug development professionals engineer robust, fair, and generalizable predictive models.
Quantitative Landscape of Data Challenges in AI-Driven Discovery
A systematic analysis of the current AI-driven drug discovery landscape reveals specific trends and pain points related to data. The following tables summarize key quantitative findings from recent literature, highlighting the distribution of AI applications and the prevalence of specific data-related issues.
Table 1: Distribution of AI Applications Across Drug Development Stages (Analysis of 173 Studies) [38]
| Development Stage | Number of Studies | Percentage | Primary Data Types and Common Challenges |
|---|---|---|---|
| Preclinical | 68 | 39.3% | Multi-omics data, HTS, chemical structures; High data heterogeneity & integration challenges. |
| Transitional (Preclinical to Phase I) | 19 | 11.0% | In silico toxicology, PK/PD data; Quality assurance for IND submission is critical. |
| Clinical Phase I | 40 | 23.1% | Early clinical trial data; Small sample sizes can introduce sampling bias. |
| Clinical Phase II | 28 | 16.2% | Efficacy and safety data; Site-specific measurement bias across clinical centers. |
| Clinical Phase III | 18 | 10.4% | Large-scale, multi-center trial data; Requires robust handling of demographic & site biases. |
Table 2: Prevalence and Impact of Data Hurdles in AI Drug Discovery
| Data Challenge | Manifestation in DBTL Platforms | Reported Impact on Model Performance |
|---|---|---|
| Data Heterogeneity | Multi-modal data from genomics, proteomics, HCS, chemical assays [8] [39]. | Reduces predictive accuracy; models fail to integrate cross-modal signals effectively. |
| Site-Specific Bias | Variations in experimental protocols, equipment, and demographics across labs/hospitals [40] [41]. | Model performance degrades when validated on external datasets (AUROC drops of 0.05-0.15 reported) [41]. |
| Demographic Bias | Under-representation of certain ethnic groups in training data [40] [41]. | Leads to unfair outcomes and poorer predictive accuracy for underrepresented subgroups. |
| Algorithmic Bias | Models learning spurious correlations from biased data [40]. | Exacerbates existing healthcare disparities; reduces clinical applicability and trust. |
Experimental Protocols for Data Quality Assurance and Bias Mitigation
Protocol 1: Multi-Modal Data Integration for Heterogeneous Datasets
Objective: To standardize and integrate diverse data types (e.g., genomic, transcriptomic, proteomic, phenotypic imaging) into a unified representation for AI agent training within a DBTL platform.
Materials:
- Research Reagent Solutions:
- Data Normalization Tools (R/Python): For batch effect correction and scaling (e.g., ComBat, SCTransform).
- Multi-Omics Integration Software: Such as MOFA+ or Seurat for identifying shared factors across data types.
- Cloud Computing Infrastructure (e.g., AWS): Essential for scalable data processing and storage [8].
- Containerization (Docker/Singularity): To ensure computational reproducibility across different research environments.
Methodology:
- Data Pre-processing:
- Independently clean and normalize each data modality. For RNA-seq data, this includes quality control, adapter trimming, alignment, and generation of gene count matrices.
- Apply batch effect correction algorithms to remove technical variance introduced by different experimental dates or equipment.
- Feature Engineering:
- Reduce dimensionality within each modality using techniques like Principal Component Analysis (PCA) or autoencoders.
- Extract biologically relevant features from high-content cellular images using convolutional neural networks (CNNs).
- Multi-Modal Integration:
- Employ a multi-omics integration framework to project the reduced features from each modality into a shared latent space.
- This latent representation captures the shared biological state across all data types, providing a holistic input for the AI agent's predictive models.
- Validation:
- Assess integration quality by measuring the concordance of the latent space with known biological groupings.
- Evaluate the downstream predictive performance of a model trained on the integrated data versus models trained on single modalities.
The following workflow diagram illustrates this multi-modal data integration pipeline:
Protocol 2: Adversarial Debiasing for Clinical Outcome Prediction
Objective: To train a clinical outcome prediction model that is robust to biases related to sensitive features such as patient ethnicity or data collection site.
Materials:
- Research Reagent Solutions:
- Adversarial Debiasing Framework: A TensorFlow/PyTorch implementation incorporating a predictor network and an adversary network [40] [41].
- Fairness Metrics Library: Code to calculate equalized odds, demographic parity, and other fairness criteria.
- Electronic Health Record (EHR) Datasets: Multi-site data, annotated with clinical outcomes and sensitive attributes.
Methodology:
- Model Architecture:
- Construct a predictor network whose objective is to accurately predict the primary clinical outcome (e.g., COVID-19 status).
- In parallel, construct an adversary network that takes the predictor's embeddings or predictions as input and tries to predict the sensitive attribute (e.g., ethnicity or hospital site).
- Training Procedure:
- Train the two networks in an adversarial manner. The goal of the predictor is to "fool" the adversary by learning representations that are informative for the primary task but uninformative for discerning the sensitive attribute.
- This is achieved via a gradient reversal layer or a min-max optimization process, where the predictor aims to maximize the adversary's loss while minimizing its own prediction loss.
- Evaluation:
- Quantify model performance using standard metrics like Area Under the Receiver Operating Characteristic Curve (AUROC).
- Quantify fairness using the equalized odds metric, which requires that the model's true positive and false positive rates are equal across different subgroups [40] [41]. A fair model will show minimal disparity in these rates.
The architecture and information flow of this adversarial training framework are detailed below:
The Scientist's Toolkit: Essential Research Reagents and Computational Solutions
Table 3: Key Research Reagents and Computational Tools for Data Hurdle Mitigation
| Category | Item / Software | Function in Overcoming Data Hurdles |
|---|---|---|
| Data Generation & Management | Automated Synthesis Robotics [8] | Standardizes the "Build" phase, reducing operational variability in compound generation. |
| High-Throughput Screening (HTS) Platforms [38] | Generates large-scale, consistent phenotypic data for the "Test" phase. | |
| Cloud Data Warehouses (e.g., AWS) [8] | Centralizes storage and enables scalable processing of massive, heterogeneous datasets. | |
| Data Processing & Integration | Multi-Omics Integration Tools (MOFA+, Seurat) | Identifies shared sources of variation across genomic, proteomic, and other data types. |
| Batch Effect Correction Algorithms (ComBat) | Removes non-biological technical variation introduced across different experimental batches. | |
| Bias Mitigation & Fairness | Adversarial Debiasing Frameworks [40] [41] | Actively removes influence of sensitive attributes (e.g., ethnicity, site) during model training. |
| Reinforcement Learning (RL) with Fairness Rewards [41] | Uses specialized reward functions to optimize for both accuracy and fairness metrics like equalized odds. | |
| Fairness Metrics Libraries (AIF360, Fairlearn) | Provides standardized metrics to quantify bias and monitor model fairness. |
The integration of Artificial Intelligence (AI) into the design-build-test-learn (DBTL) cycle is revolutionizing biological research and drug development, creating highly automated, closed-loop platforms [42]. These "AI scientists" can autonomously plan and execute experiments, analyze data, and refine hypotheses at a scale and speed impossible for human researchers alone [42]. However, this unprecedented power introduces novel risks, including AI hallucination (the generation of factually incorrect or nonsensical outputs), the amplification of data biases, and the potential for automated systems to operate outside safe parameters [43] [44] [42]. The "black box" nature of many complex AI models further complicates their direct application in critical, regulated environments like drug development [44]. This application note establishes that a Human-in-the-Loop (HITL) framework is not merely beneficial but essential for ensuring the reliability, safety, and ethical integrity of research conducted on these platforms. This protocol provides detailed methodologies for implementing effective HITL oversight, combining AI's computational power with human expertise to create a robust governance structure for closed-loop DBTL systems [43] [45].
Quantitative Validation of HITL Systems
Empirical data underscores the performance gains achieved by integrating human oversight with AI. The following tables summarize validation metrics from AI-assisted research workflows and the tangible business impacts of HITL implementation.
Table 1: Performance Metrics of AI Tools with Human Oversight in Research Workflows
| AI Tool Function | Reported Metric | Performance with HITL | Source / Context |
|---|---|---|---|
| Boolean Search Generation | Recall | 76.8% - 79.6% | Smart Search AI vs. expert gold standard [46] |
| Literature Screening | Recall | 82% - 97% | Supervised machine learning tools [46] |
| PICO Elements Extraction | F1 Score | 0.74 | Population, Interventions, Comparators, Outcomes [46] |
| Study Data Extraction | Accuracy | 74% (Type), 78% (Location), 91% (Size) | AI extraction requiring human curation [46] |
| AI-Probed Responses | Thoughtfulness Increase | 293% | Oura case study on AI-generated follow-up questions [47] |
Table 2: Business and Operational Impact of HITL Integration
| Area of Impact | Outcome | Quantitative or Qualitative Result |
|---|---|---|
| Operational Efficiency | Time Savings | 50% in Abstract Screening; 70-80% in qualitative extraction [46] |
| Research Productivity | Productivity Gain | ~40% improvement for highly skilled workers [45] |
| Drug Development | Timeline Acceleration | 40% faster to bring a new molecule to preclinical candidate stage [45] |
| Cost Reduction | R&D Cost Savings | Up to 30% for molecule-to-candidate process [45] |
| Model Reliability | Quality Assurance | 23% of companies at large global firms evaluate AI output daily [45] |
Experimental Protocols for HITL Oversight
The following protocols provide a scaffold for implementing HITL governance at critical points within a closed-loop DBTL platform.
Protocol for AI-Assisted Literature Review and Data Extraction
This protocol outlines a HITL workflow for systematic literature review, a foundational step in the "Learn" phase of the DBTL cycle [46].
I. Research Question Formulation and Search Strategy
- Objective: To comprehensively identify all relevant studies using AI-generated Boolean queries with human refinement.
- Materials: AutoLit or similar SLR software with API access to databases (e.g., PubMed, Embase).
- Methodology:
- Input the Research Question into the AI's "Smart Search" tool.
- The AI will engage in a Generator-Critic loop, prompting the user for all Population, Interventions, Comparators, and Outcomes (PICOs) and other constraints [46].
- The AI generates three candidate Boolean queries. The human researcher selects one based on their domain knowledge.
- The selected query is run against connected databases. Human oversight is required to review a sample of results and iteratively refine the query using the software's "Search Exploration" feature, which breaks down the frequency of concepts in the results [46].
II. Screening and Data Extraction with Active Learning
- Objective: To efficiently screen titles/abstracts and full texts, and extract data with continuous human validation.
- Methodology:
- Dual Screening: The AI ranks records by predicted relevance. Human reviewers screen titles and abstracts, with their decisions used to continuously retrain the AI model [46].
- Full-Text Review: A similar HITL process is applied to full-text articles.
- Data Extraction: The AI pre-populates data extraction fields (e.g., PICOs, study details). A human researcher must review and curate every extracted data point for accuracy before it is used in analysis. For systematic reviews, this human curation is mandatory [46].
Protocol for Synthetic Data Generation and Model Guardrailing
This protocol addresses the data crisis in AI training and the risk of model collapse, particularly relevant for the "Design" and "Learn" phases [43].
I. Synthetic Data Augmentation for Edge Cases
- Objective: To generate synthetic data to address class imbalance and improve model robustness for rare events.
- Materials: Synthetic data platform (e.g., for generating images of rare manufacturing defects or novel protein structures).
- Methodology:
- Audit Data Gaps: The human research team identifies specific "weak" classes or edge cases where the model underperforms due to insufficient real-world data [43].
- Generate Synthetic Data: Use the platform to generate thousands of variations of the edge case (e.g., rare defects under different lighting, novel protein folds).
- HITL Validation: A domain expert must validate a representative sample of the synthetic data for fidelity and relevance before it is used to augment the training set [43].
- Retrain and Validate: Retrain the model on the augmented dataset and validate performance on a held-out test set of real-world data.
II. Preventing Model Collapse via HITL Review
- Objective: To maintain model integrity and prevent degradation when training on AI-generated data.
- Methodology:
- Blended Data Pipeline: Establish a training data pipeline that blends real-world data (serving as ground truth), high-quality synthetic data, and weakly supervised data [43].
- Active Learning Loop: Implement a system where the AI identifies data points where it is uncertain or performing poorly. These points are prioritized for human review and correction [43].
- Continuous Monitoring: Human experts regularly review a sample of the model's outputs against established quality metrics to detect early signs of drift or collapse, triggering a retraining cycle with fresh, validated data [43].
Protocol for AI-Driven Experimental Workflow Execution
This protocol governs the wet-lab execution of AI-planned experiments in an automated biofoundry, covering the "Build" and "Test" phases [42].
I. Pre-Run Experimental Design Approval
- Objective: To ensure AI-proposed experiments are scientifically sound and safe before execution.
- Materials: AI "lab assistant" platform, automated biofoundry with robotic systems.
- Methodology:
- The AI proposes an experimental workflow, including genetic designs, culture conditions, and analytical steps.
- A lead scientist must review and approve the entire experimental plan. This review specifically checks for:
- Record Keeping: A record of this approval, including the reviewer's name and date, must be kept as part of the experiment's audit trail [48].
II. Runtime Monitoring and Intervention
- Objective: To provide continuous oversight of automated experiments.
- Methodology:
- A human operator is designated to monitor the automated system's status during runtime.
- The system is programmed to flag predefined anomalies (e.g., unexpected sensor readings, growth curves) for human intervention.
- The human operator has the authority to pause or abort the experiment if it deviates from approved parameters or if a safety concern arises [42].
Workflow Visualization of HITL in DBTL Cycles
The following diagram illustrates the integrated HITL oversight points within a closed-loop DBTL platform, highlighting the critical junctures where human expertise is required.
HITL Oversight in Automated DBTL Platform
The Scientist's Toolkit: Essential Research Reagents and Solutions for HITL Implementation
Effective HITL governance requires both technical and procedural components. The following table details key elements for establishing these protocols.
Table 3: Essential Components for Implementing HITL Oversight Protocols
| Item / Solution | Function / Description | Role in HITL Protocol |
|---|---|---|
| AutoLit / SLR Software | AI-powered systematic literature review platform. | Automates search, screening, and data extraction while enforcing human curation points for validation [46]. |
| Synthetic Data Platform | Generates artificial datasets that mimic real-world statistical properties. | Creates data for edge cases and rare events; requires human experts to validate output fidelity [43]. |
| Automated Biofoundry | Integrated robotic system for automated laboratory workflows. | Executes AI-designed "Build" and "Test" protocols; requires human pre-approval and runtime monitoring [42]. |
| AI Lab Assistant (e.g., CRISPR-GPT) | LLM-powered agent for experimental design and troubleshooting. | Provides step-by-step instructions; outputs must be critically reviewed by scientists to prevent hallucination-driven errors [42] [49]. |
| Model Auditing & Version Control | Framework for tracking model performance, data provenance, and changes. | Enables transparency, reproducibility, and identification of model drift, forming the basis for human-led retraining decisions [43] [46]. |
| Standard Operating Procedure (SOP) | Documented procedure for HITL review and approval. | Formally defines responsibilities, checkpoints, and record-keeping requirements, ensuring regulatory compliance [48]. |
The advent of artificial intelligence (AI) and automation is revolutionizing biomedical research, particularly in protein engineering and drug discovery. Traditional approaches often operate in silos, where computational design and experimental validation are sequential and disconnected processes. This fragmentation leads to inefficiencies, prolonged development timelines, and suboptimal outcomes. The integration of disparate systems into closed-loop Design-Build-Test-Learn (DBTL) platforms, powered by autonomous AI agents, represents a paradigm shift. These platforms create a seamless, iterative feedback cycle where AI-driven design directly informs automated experiments, and experimental results continuously refine computational models. This article details application notes and protocols for implementing such integrated systems, providing researchers with practical methodologies for bridging computational and experimental workflows within the context of AI-agent-driven research.
Application Notes: Implementing Closed-Loop DBTL Platforms
Core Architecture and Workflow Integration
Successful integration of computational and experimental systems requires a cohesive architectural framework. The fundamental shift involves transitioning from a linear DBTL cycle to a Learning-Design-Build-Test (LDBT) paradigm, where machine learning precedes and directly informs the design phase [7]. This reordering leverages pre-trained AI models to generate more intelligent initial designs, reducing the number of iterative cycles needed.
The core architecture of a closed-loop platform integrates several key components:
- AI-Driven Design Agents: Utilize large language models (LLMs) and specialized machine learning tools for initial protein variant design.
- Automated Biofoundries: Robotic platforms handle the physical construction and testing of biological designs.
- Data Management Systems: Centralized platforms aggregate experimental results for continuous model training.
- Closed-Loop Feedback Controllers: AI agents analyze results and autonomously propose subsequent design iterations.
The Digital Catalysis Platform (DigCat) exemplifies this approach, integrating over 400,000 experimental data points with AI models to create an autonomous design workflow accessible via cloud-based interfaces [17]. Similar architectures have been successfully applied to protein engineering, demonstrating the generalizability of this framework.
Quantitative Performance Metrics
Recent implementations of integrated AI-agent-driven platforms demonstrate significant improvements in engineering efficiency. The table below summarizes key performance metrics from published studies:
Table 1: Performance Metrics of Integrated AI-Driven Platforms
| Platform/System | Engineering Target | Timeframe | Improvement | Variants Tested | Key Technologies |
|---|---|---|---|---|---|
| Generalized Autonomous Enzyme Engineering Platform [11] | Arabidopsis thaliana halide methyltransferase (AtHMT) | 4 weeks | 90-fold improvement in substrate preference; 16-fold improvement in ethyltransferase activity | <500 variants | iBioFAB, ESM-2, EVmutation, low-N ML models |
| Generalized Autonomous Enzyme Engineering Platform [11] | Yersinia mollaretii phytase (YmPhytase) | 4 weeks | 26-fold improvement in activity at neutral pH | <500 variants | iBioFAB, ESM-2, EVmutation, low-N ML models |
| Cloud Synthesis Platform (DigCat) [17] | Catalyst materials | N/A | High prediction accuracy validated against experimental results | N/A | LLM-integrated workflow, microkinetic modeling, cloud infrastructure |
| AI-Enhanced Cell-Free Testing [7] | Various proteins and pathways | Substantially accelerated | Enabled zero-shot prediction and single-cycle engineering | Ultra-high-throughput (e.g., 776,000 variants [7]) | Cell-free systems, protein language models, droplet microfluidics |
Key Implementation Challenges and Solutions
Implementing integrated systems presents several technical challenges that require specific solutions:
- Data Heterogeneity: Disparate data sources often have incompatible formats and schemas. Solution: Implement middleware with standardized data transformation protocols and use computational frameworks like Rosetta that can integrate multiple data types [50].
- Workflow Integration: Connecting computational and experimental systems requires both physical and digital integration. Solution: Develop modular workflow systems like the iBioFAB's seven automated modules that can be individually programmed and troubleshooted [11].
- Model-Experiment Discrepancies: AI predictions often diverge from experimental results. Solution: Implement active learning frameworks where discrepancies are explicitly analyzed and fed back to improve models [17].
- Privacy and Security: Integrating sensitive data requires careful handling. Solution: Deploy privacy-enhancing technologies (PETs) such as homomorphic encryption and federated learning that enable secure data collaboration without sharing raw data [51].
Experimental Protocols
Protocol 1: Autonomous Protein Engineering Using Integrated AI-Biofoundry Platform
This protocol describes the end-to-end process for autonomous enzyme engineering, adapted from the generalized platform detailed in [11].
Computational Design Phase
Objective: Generate diverse, high-quality protein variants using AI models. Materials and Reagents:
- Wild-type protein sequence
- Computational resources (CPU/GPU cluster)
- Protein language models (ESM-2)
- Epistasis models (EVmutation)
Procedure:
- Input Preparation: Provide wild-type protein sequence and define engineering objective (e.g., improved activity, stability).
- Variant Generation: a. Run ESM-2 to predict amino acid likelihoods at each position based on evolutionary context. b. Execute EVmutation to identify co-evolutionary patterns and epistatic relationships. c. Combine results from both models to generate a ranked list of 180-200 variants for initial testing. d. Apply filters based on structural constraints (e.g., active site preservation).
- Output Generation: Export variant sequences in FASTA format for synthesis.
Diagram: Computational Design Workflow
Automated Construction and Testing Phase
Objective: Physically construct and characterize designed variants with minimal human intervention. Materials and Reagents:
- Oligonucleotides for gene synthesis
- HiFi assembly mix
- Expression vectors
- Expression hosts (E. coli or other)
- Assay reagents specific to protein function
- iBioFAB or equivalent biofoundry platform
Procedure:
- Library Construction: a. Implement HiFi-assembly based mutagenesis to create variant libraries without intermediate sequence verification. b. Transform constructs into expression hosts using automated microbial transformations. c. Pick colonies and inoculate expression cultures in 96-well format.
- Protein Expression: a. Induce protein expression under optimized conditions. b. Harvest cells and prepare crude lysates using automated protocols.
- Functional Assays: a. Perform enzyme activity assays in high-throughput format. b. Measure fitness parameters (e.g., substrate conversion, thermal stability) relevant to engineering goals. c. Collect raw data and process to calculate variant fitness scores.
Diagram: Automated Build-Test Workflow
Learning and Model Refinement Phase
Objective: Update AI models with experimental data to improve prediction accuracy. Materials and Reagents:
- Experimental fitness data
- Computational resources for model retraining
- Low-data machine learning models (e.g., Bayesian optimization)
Procedure:
- Data Processing: Clean and normalize experimental fitness data.
- Model Retraining: a. Combine initial AI predictions with experimental results. b. Train supervised machine learning models (e.g., random forest, gradient boosting) on the combined dataset. c. Validate model performance using cross-validation.
- Next-Generation Design: a. Use refined models to propose improved variants for subsequent round. b. Prioritize variants based on predicted fitness and diversity metrics.
Protocol 2: Cell-Free Protein Engineering with AI Integration
This protocol leverages cell-free systems for ultra-high-throughput testing, enabling rapid DBTL cycles [7].
Cell-Free Build-Test Workflow
Objective: Rapidly test AI-designed protein variants without cellular constraints. Materials and Reagents:
- Cell-free transcription-translation system
- DNA templates for variant proteins
- Microfluidic device or liquid handling robot
- Assay reagents compatible with cell-free system
Procedure:
- DNA Template Preparation: Synthesize DNA encoding variant proteins using automated methods.
- Cell-Free Reactions: a. Set up picoliter- to microliter-scale cell-free reactions in droplet microfluidics platform or 96-well format. b. Incubate to allow protein expression (typically 2-4 hours).
- Functional Screening: a. Measure protein activity directly in cell-free system using fluorescence, absorbance, or other readouts. b. Sort or select variants based on performance thresholds.
- Data Collection: Automate data capture and processing for model refinement.
The Scientist's Toolkit: Essential Research Reagents and Platforms
Table 2: Key Research Reagent Solutions for Integrated Computational-Experimental Platforms
| Category | Specific Tool/Platform | Function | Application Notes |
|---|---|---|---|
| Computational Design Tools | ESM-2 (Evolutionary Scale Modeling) [11] | Protein language model predicting amino acid probabilities based on evolutionary sequences | Used for zero-shot prediction of beneficial mutations; requires no additional training for basic applications |
| Computational Design Tools | EVmutation [11] | Infers epistatic relationships and co-evolutionary patterns from multiple sequence alignments | Identifies structurally and functionally constrained positions; complements language models |
| Computational Design Tools | ProteinMPNN [50] [7] | Structure-based neural network for designing sequences that fold into desired backbones | Higher success rates compared to traditional physics-based design; integrates with AlphaFold validation |
| Computational Design Tools | Rosetta [50] | Comprehensive software suite for macromolecular modeling and design | Extensive community support; particularly effective for protein-protein interactions and complex structures |
| Automation Platforms | iBioFAB (Illinois Biological Foundry) [11] | Fully automated biofoundry for end-to-end biological experimentation | Implements modular workflow with 7 automated steps from DNA construction to assay |
| Automation Platforms | Cloud-based Synthesis Platforms [17] | Remote access to automated synthesis and testing capabilities | Enables global collaboration; exemplified by DigCat platform with cloud-based prediction interfaces |
| Experimental Systems | Cell-free Expression Systems [7] | In vitro transcription-translation systems for rapid protein production | Enables >1 g/L protein in <4 hours; scalable from pL to kL; suitable for toxic proteins |
| Experimental Systems | Microfluidic Droplet Platforms [7] | Ultra-high-throughput screening of protein variants | Enables screening of >100,000 variants in picoliter-scale reactions; reduces reagent costs |
| Privacy and Collaboration | Privacy-Enhancing Technologies (PETs) [51] | Cryptographic tools for secure data collaboration | Includes homomorphic encryption, federated learning; enables collaboration without sharing raw data |
The integration of disparate computational and experimental systems into closed-loop DBTL platforms represents a transformative advancement in biomedical research. By implementing the protocols and application notes detailed herein, researchers can establish autonomous engineering systems that dramatically accelerate the development of novel enzymes, therapeutic proteins, and catalytic materials. The continuous feedback between AI-driven design and automated experimentation creates a virtuous cycle of improvement, reducing reliance on expensive trial-and-error approaches. As these platforms become more sophisticated and accessible, they have the potential to reshape the entire biotechnology and pharmaceutical development landscape, enabling more rapid translation of basic research into practical applications that address pressing challenges in health, energy, and sustainability.
In the evolving landscape of drug development and synthetic biology, closed-loop Design-Build-Test-Learn (DBTL) platforms powered by AI agents represent a transformative paradigm. These systems promise to accelerate innovation cycles, yet their value must be quantified through rigorous performance assessment. For researchers, scientists, and drug development professionals, establishing a comprehensive KPI framework is not merely an administrative exercise but a fundamental requirement for justifying continued investment, guiding platform optimization, and demonstrating competitive advantage. The transition from traditional, linear R&D to an iterative, AI-driven "factory" model necessitates new diagnostic tools that capture both operational efficiency and scientific output [52].
This application note provides a standardized framework for defining, tracking, and interpreting KPIs specific to autonomous DBTL platforms. By synthesizing recent advances in AI-powered R&D intelligence, robotic automation, and platform valuation, we present actionable protocols for benchmarking success across the complete innovation lifecycle—from molecular design to validated therapeutic candidates.
Core KPI Framework: Quantifying the Closed-Loop Advantage
A robust assessment of platform efficiency requires monitoring metrics across four interconnected domains: Cycle Velocity, Experimental Throughput, Decision Quality, and Economic Impact. The following table synthesizes key quantitative benchmarks from operational AI-driven platforms, providing baseline targets for performance evaluation.
Table 1: Core KPI Framework for Closed-Loop DBTL Platforms
| KPI Domain | Specific Metric | Calculation Method | Reported Benchmark | Data Source |
|---|---|---|---|---|
| Cycle Velocity | DBTL Cycle Time Compression | (Manual cycle time - Automated cycle time) / Manual cycle time | 50-70% reduction [53] | Platform analytics |
| AI Design-to-Build Time | Time from AI model inference to physical DNA sequence readiness | Hours (vs. weeks traditionally) [1] | Workflow timestamps | |
| Automated Experiment Duration | Total hands-off time for build-test phases | 4 weeks for 4 full DBTL cycles [1] | Robotic scheduler logs | |
| Experimental Throughput | Variants Screened per Cycle | Number of constructs built and tested per iteration | >100,000 reactions using droplet microfluidics [2] | Laboratory Information Management System (LIMS) |
| Data Points Generated Daily | Volume of structured experimental measurements | 776,000 protein variants characterized [2] | Data platform analytics | |
| Library Design Efficiency | Ratio of functional variants to total variants tested | ~500 variants screened to achieve 26-fold activity improvement [1] | Experimental results vs. design logs | |
| Decision Quality | Model Prediction Accuracy | Correlation between predicted and measured variant performance | Successful zero-shot prediction of enzyme function [2] | Model validation datasets |
| Experimental Success Rate | Percentage of experiments yielding usable, high-quality data | ~95% mutagenesis accuracy enabling continuous workflow [1] | Data quality flags in LIMS | |
| Hypothesis Confirmation Rate | Proportion of AI-generated designs validating experimental hypotheses | 10.9% of experiments start with AI-generated ideas [54] | Experimental outcomes vs. hypotheses | |
| Economic Impact | Cost per Variant Tested | Total experimental cost / number of variants | 30-70% cost reduction for advanced setups [55] | Financial system integration |
| R&D Productivity Gain | Research output per scientist FTE | 50% reduction in researcher time spent searching/analyzing [53] | Time-tracking and output metrics | |
| Platform Attrition Improvement | Increase in candidate success rates versus traditional methods | 1-3 percentage point increase in early-phase success probability [52] | Portfolio tracking |
Experimental Protocols for KPI Validation
Protocol: Measuring Cycle Time Compression in an Automated DBTL Pipeline
Background: Quantifying the acceleration afforded by closed-loop operation requires precise measurement of temporal metrics across complete innovation cycles. This protocol establishes a standardized method for tracking cycle time compression in protein engineering campaigns.
Materials:
- Robotic automation platform (e.g., iBioFAB) [1]
- AI design module (e.g., protein language models like ESM-2) [2] [1]
- Laboratory Information Management System (LIMS) with timestamping
- Target enzyme sequence and high-throughput assay system
Procedure:
- Baseline Establishment: Execute one complete DBTL cycle manually, recording time requirements for:
- Design Phase: Literature review, hypothesis generation, and manual variant selection (typically 2-3 weeks)
- Build Phase: Manual cloning, transformation, and sequence verification (typically 3-4 weeks)
- Test Phase: Manual protein expression, purification, and assay (typically 2-3 weeks)
- Learn Phase: Data analysis and interpretation (typically 1-2 weeks)
Automated Cycle Implementation: Initiate automated DBTL platform with identical engineering objective:
- Design Phase: Activate AI-driven design using pre-trained protein language models (ESM-2) and epistasis models (EVmutation) to generate initial variant library [1]
- Build Phase: Deploy automated gene synthesis and cloning via robotic platform with high-fidelity mutagenesis
- Test Phase: Implement continuous cultivation in microtiter plates with automated induction, sampling, and fluorescence measurement [56]
- Learn Phase: Execute automated data analysis and next-round variant selection using machine learning regression models
Data Collection: Extract precise timestamps from platform scheduler for each phase transition
- Calculation: Compute cycle time compression using: [(Manual Cycle Time - Automated Cycle Time) / Manual Cycle Time] × 100%
- Validation: Repeat for multiple engineering campaigns to establish statistical significance
Expected Outcomes: Successful implementation typically demonstrates 50-70% reduction in total cycle time, with the largest gains in Build and Test phases [53]. The autonomous enzyme engineering platform by Zhao et al. completed four iterative cycles in just four weeks, representing an order-of-magnitude acceleration versus manual operations [1].
Protocol: Assessing Experimental Throughput and Data Generation Rates
Background: The value of autonomous platforms scales with their capacity to generate high-quality experimental data. This protocol measures throughput metrics essential for quantifying platform capacity and efficiency.
Materials:
- Liquid handling robotics (e.g., CyBio FeliX systems) [56]
- Microtiter plate readers and integrated incubation systems
- High-throughput screening assay compatible with automation
- Data management infrastructure capable of handling large datasets
Procedure:
- Platform Calibration: Validate robotic fluid handling accuracy and precision across full operational volume range
- Throughput Benchmarking: Configure platform for maximum parallel processing:
- Utilize 96-well or 384-well microtiter plates for cultivation and testing
- Implement continuous operation with staggered cultivation start times
- Activate all integrated measurement modalities (e.g., OD600, fluorescence) [56]
- Data Collection: Over a standardized 24-hour operational period, record:
- Number of variants constructed and transformed
- Number of individual assays performed
- Volume of raw data points generated (including all measurement timepoints)
- Percentage of successful assays (data quality flags)
- Quality Validation: Randomly select subsets for manual verification of key results
- Calculation: Compute daily throughput metrics and compare to manual baseline capabilities
Expected Outcomes: Advanced platforms demonstrate exceptional throughput, with examples including characterization of 776,000 protein variants for stability mapping [2] and screening of >100,000 picoliter-scale reactions using droplet microfluidics [2]. The robotic platform described by Torres-Acosta et al. enables continuous cultivation and measurement of hundreds of parallel cultures with minimal human intervention [56].
Workflow Visualization: Mapping the KPI Assessment Framework
The following diagrams illustrate the logical relationships between platform components, KPI measurement points, and the continuous improvement cycle enabled by effective benchmarking.
Diagram 1: KPI Framework for DBTL Platforms
Diagram 2: Data Flywheel Effect in AI-Driven Platforms
The Scientist's Toolkit: Essential Research Reagents and Platforms
Successful implementation of the KPI framework requires specific technological infrastructure. The following table details essential solutions for establishing and benchmarking autonomous DBTL platforms.
Table 2: Essential Research Reagent Solutions for Autonomous DBTL Platforms
| Category | Specific Solution | Function | Implementation Example |
|---|---|---|---|
| AI Design Platforms | Protein Language Models (ESM-2) | Zero-shot prediction of protein function and stability | Pre-trained models used for initial library design without experimental data [1] |
| Structure-Based Design Tools (ProteinMPNN) | Sequence design for specific structural scaffolds | Designing stable enzyme variants with altered functions [2] | |
| Multimodal AI Platforms (Cypris) | Centralized analysis of patents, research, and competitive intelligence | Consolidating 500M+ data points for R&D strategy [53] | |
| Laboratory Automation | Integrated Robotic Platforms (iBioFAB) | Fully automated gene synthesis, cloning, and expression | Continuous operation with ~95% mutagenesis accuracy [1] |
| Liquid Handling Systems (CyBio FeliX) | Precise fluid transfer for high-throughput assays | Automated cultivation and induction in microtiter plates [56] | |
| Plate Readers with Incubation | Continuous monitoring of culture growth and protein production | Integrated OD600 and fluorescence measurement [56] | |
| Data Infrastructure | Vector Databases (Pinecone) | High-performance storage and retrieval of embedding vectors | Enabling semantic search across experimental results [57] |
| Orchestration Frameworks (LangChain) | Coordination of multi-step AI reasoning processes | Building complex experimental design workflows [57] | |
| Laboratory Information Management Systems | Structured storage of experimental metadata and results | Tracking provenance across complete DBTL cycles [56] |
The KPI framework presented herein enables objective assessment of closed-loop DBTL platform performance, transforming subjective claims of capability into quantifiable metrics of efficiency and output. For research organizations seeking to validate platform investments or benchmark against industry standards, consistent application of these protocols provides the evidentiary foundation required for strategic decision-making.
As autonomous platforms continue to evolve, the most successful organizations will be those that not only implement these measurement systems but also create feedback loops that directly connect KPI performance to platform refinement. In this context, benchmarking becomes not merely an assessment tool but an integral component of the continuous improvement cycle that defines next-generation biopharmaceutical R&D.
Proof and Performance: Validating AI Platforms and Comparing Industry Leaders
The integration of artificial intelligence (AI) into drug discovery has catalyzed a paradigm shift, enabling the rapid identification and design of novel therapeutic candidates. A decade after the deep learning revolution, the field is now focused on a critical juncture: translating computationally designed molecules into clinically successful drugs [58]. The traditional drug development process is notoriously inefficient, with nearly 90% of drug candidates failing due to insufficient efficacy or unforeseen safety concerns [59]. AI-driven approaches promise to enhance this process through accelerated preclinical timelines and improved decision-making, yet the ultimate validation of these approaches hinges on successful navigation through human clinical trials [60].
The emergence of closed-loop Design-Build-Test-Learn (DBTL) platforms, enhanced by AI agents, represents a transformative approach to biotherapeutic development. These integrated systems leverage machine learning, automation, and continuous learning cycles to compress development timelines and optimize candidate selection [2] [11]. This Application Note examines the current landscape of AI-designed candidates progressing through clinical-stage validation, providing structured quantitative data, detailed experimental methodologies, and visual workflows to guide researchers in tracking and validating AI-generated therapeutic candidates from preclinical development to human trials.
Current Landscape of AI-Designed Clinical Candidates
Quantitative Analysis of AI Drugs in Clinical Trials
As of 2024, the clinical pipeline for AI-discovered therapeutics is growing but remains early in its evolution. Independent analyses reveal that leading AI drug discovery companies have advanced numerous candidates into human trials, though none have yet achieved full clinical approval [58]. The distribution across development phases demonstrates the forward momentum of AI-driven approaches while highlighting the significant validation hurdles that remain, particularly in later-stage trials where efficacy demands are more stringent.
Table 1: Clinical-Stage AI-Designed Drug Candidates (2024 Analysis)
| Development Phase | Number of Candidates | Notable Outcomes |
|---|---|---|
| Phase I | 17 | One program terminated [58] |
| Phase I/II | 5 | One program discontinued [58] |
| Phase II | 9 | One with non-significant results [58] |
| Phase II/III | 0 | None reached this advanced phase [58] |
| Clinically Approved | 0 | No novel AI-discovered drugs approved [58] |
Broader industry analyses that employ more inclusive definitions of AI involvement in drug discovery suggest an expanded pipeline of approximately 67 molecules in clinical trials, with one repurposed generic molecule already launched [58]. This discrepancy in reporting underscores the emerging nature of the field and the challenge in establishing standardized metrics for evaluating AI's contribution to therapeutic development.
Emerging Efficacy and Safety Profiles
Early clinical data suggests that AI-discovered drugs in Phase I clinical trials may demonstrate improved safety profiles compared to traditionally developed drugs, with estimates indicating success rates of 80-90% for AI-developed drugs versus 40-65% for drugs discovered via traditional methods [59]. This enhanced early-stage safety profile may be attributable to more predictive toxicology models and comprehensive in silico profiling during candidate optimization.
However, this promising safety record has not yet translated to demonstrable improvements in clinical efficacy. The majority of initial AI-derived molecules act on previously established targets, with Phase 2/proof-of-concept success rates remaining around 40%—comparable to traditionally developed molecules [60]. This suggests that while AI has accelerated preclinical discovery and improved initial safety profiling, fundamental challenges in predicting human efficacy persist.
AI-Driven Discovery Models and Clinical Translation Frameworks
Preclinical Development Models
AI-driven drug discovery companies typically employ one of three strategic models, each with distinct risk profiles and clinical translation pathways [58]. Understanding these models is essential for contextualizing clinical validation results and establishing appropriate benchmarking criteria.
Table 2: AI-Driven Drug Discovery Company Models and Characteristics
| Company Model | Target/Molecule Strategy | Risk Profile | Clinical Translation Pathway |
|---|---|---|---|
| Repurposing/In-Licensing | AI-derived hypotheses applied to known drugs or generics | High target choice risk, Low chemistry risk | Bypasses early development; rapid initiation of Phase II studies [58] |
| New Entities for Established Targets | AI-driven design for validated targets | Low target choice risk, High chemistry risk | Focus on best-in-class molecules; competition with established players [58] |
| Novel Molecules for Novel Targets | End-to-end AI platforms for novel target and molecule discovery | High target choice risk, Moderate chemistry risk | First-in-class programs; one company completed Phase IIa demonstrating safety and efficacy [58] |
The choice of development model significantly influences both the speed of clinical entry and the nature of validation requirements. Companies focusing on drug repurposing can rapidly advance to Phase II trials but carry substantial biological validation risk, while those pursuing novel target discovery face longer development timelines but potentially greater competitive advantages upon success [58].
Timeline Acceleration through AI-Enhanced Workflows
AI-driven platforms have demonstrated remarkable efficiency in compressing preclinical development timelines. Published examples highlight the potential for substantial acceleration, though with variability depending on program novelty and target validation status [58].
Table 3: Reported Timelines for AI-Driven Preclinical Development
| Program Type | Reported Timeline | Outcome | Validation Status |
|---|---|---|---|
| Novel target for Idiopathic Pulmonary Fibrosis | 18 months to preclinical candidate | Completed Phase IIa with demonstrated safety and dose-dependent efficacy [58] | Peer-reviewed publication [58] |
| Benchmark programs (n=22) | Average 12-18 months to IND-enabling studies | Advanced to IND-enabling studies [60] | Company report [60] |
| REC-1245 | 18 months from discovery to IND-enabling studies | Advanced to IND-enabling studies [60] | Company report [60] |
| Other published example | 12 months from initiation to completion | Not specified | Peer-reviewed publication [58] |
| Non-peer-reviewed claims | 9 months | Not specified | Non-peer-reviewed announcement [58] |
Independent analysis models predict that AI integration can reduce costs and timelines by 40-50% for programs built around established chemical families and well-understood targets, with slightly more modest efficiencies (35-40% faster, 25-30% cheaper) for programs involving new molecules or unvalidated targets [60].
Autonomous Experimental Platforms for AI-Driven Validation
Integrated AI-Biofoundry Workflow for Protein Engineering
Recent advances have demonstrated fully autonomous platforms for enzyme engineering that integrate machine learning with biofoundry automation. The following workflow illustrates a generalized platform for AI-powered autonomous enzyme engineering that has successfully improved enzyme activity by 16- to 26-fold within four weeks through iterative DBTL cycles [11].
This automated platform exemplifies the LDBT (Learn-Design-Build-Test) paradigm, where machine learning precedes and directly informs the design phase, potentially reducing the need for multiple iterative cycles [2]. The system requires only an input protein sequence and a quantifiable fitness measurement, enabling broad applicability across diverse protein engineering challenges [11].
Protocol: Autonomous Enzyme Engineering for Therapeutic Proteins
Application: Engineering therapeutic enzymes for improved properties (e.g., specificity, pH stability, catalytic efficiency)
Experimental Workflow:
Learn Phase - Initial Computational Design
- Input Requirements: Wild-type protein sequence and defined fitness function (e.g., enzymatic activity, substrate preference, pH stability)
- Computational Tools:
- Library Design: Combine unsupervised models to generate 180-200 variants for initial screening, maximizing diversity and quality [11]
Design Phase - Library Construction Planning
- Primer Design: Design primers for HiFi-assembly based mutagenesis
- Automation Planning: Format instructions for robotic liquid handling systems
- Plate Mapping: Assign variant locations in 96-well or 384-well plates
Build Phase - Automated Library Construction (iBioFAB Platform)
- Module 1: Mutagenesis PCR setup with automated liquid handling [11]
- Module 2: DpnI digestion to remove template DNA [11]
- Module 3: Automated transformation in 96-well format [11]
- Module 4: Robotic colony picking to 96-well deep-well plates [11]
- Module 5: Plasmid purification via automated miniprep [11]
- Module 6: Protein expression induction and culture [11]
Test Phase - High-Throughput Functional Characterization
- Module 7: Automated cell lysis and crude lysate collection [11]
- Functional Assay: Implementation of plate-based enzyme activity assay
- Data Collection: Automated absorbance/fluorescence measurement
- Fitness Quantification: Normalization to wild-type activity
Learn Phase - Model Retraining and Iteration
- Data Integration: Compile screening data for all tested variants
- Model Retraining: Update machine learning model with experimental results
- Next Cycle Design: Select top variants for additional mutagenesis or design new variants based on learned sequence-function relationships
- Iteration: Conduct 3-4 cycles of optimization to achieve target fitness improvement [11]
Key Advantages:
- Eliminates sequence verification steps through high-fidelity assembly (~95% accuracy) [11]
- Enables continuous operation through modular, automated workflows
- Achieves significant functional improvements (16-26x) within 4 weeks [11]
- Requires construction and testing of <500 variants per enzyme [11]
Molecular Docking and Virtual Screening in Target Validation
Computational Protocol for Target Identification
Molecular docking serves as a foundational computational tool in AI-driven drug discovery, predicting the binding affinity of ligands to receptor proteins and facilitating the identification of molecular targets for therapeutic candidates [61]. The docking process involves two critical steps: sampling ligand conformations within the protein's active site and ranking these conformations using scoring functions [62].
Table 4: Molecular Docking Software and Methodologies
| Software | Sampling Algorithm | Scoring Function | Applications in Therapeutic Discovery |
|---|---|---|---|
| AutoDock Vina | Gradient optimization | Empirical scoring function | High-speed docking; suitable for virtual screening [61] |
| Glide | Systematic conformational search | Physics-based scoring with MM/GBSA | High-accuracy pose prediction; lead optimization [61] |
| GOLD | Genetic algorithm | GoldScore, ChemScore | Flexible ligand docking; protein-ligand interaction mapping [61] |
| DOCK | Shape-based matching | Force field-based scoring | Binding site identification; blind docking studies [61] |
The utility of molecular docking extends beyond conventional small-molecule drug discovery to nutraceutical research, where it helps authenticate molecular targets of bioactive compounds in disease management [61]. This approach has been successfully applied to identify molecular targets for nutraceuticals in diverse disease models, including sickle cell disease, cancer, cardiovascular disorders, and neurodegenerative conditions [61].
Advanced Docking Considerations for Complex Targets
Contemporary docking approaches address several challenges in target validation:
- Flexible Receptor Docking: Implementation of Local Move Monte Carlo (LMMC) approaches to account for backbone flexibility in receptors, overcoming limitations of rigid receptor models [62]
- Blind Docking: Utilization of cavity detection programs (GRID, POCKET, SurfNet) to identify putative active sites when binding location is unknown [62]
- Consensus Scoring: Application of multiple scoring functions (force field-based, empirical, knowledge-based) to improve binding affinity prediction reliability [61]
The integration of molecular docking with AI-driven approaches enhances the initial target validation phase, providing computational evidence for target engagement before proceeding to resource-intensive experimental validation.
Functional Validation in Human-Relevant Systems
Addressing the Translational Gap through Human-Focused Assays
A critical challenge in AI-driven drug development is the translation between preclinical success and clinical efficacy. Currently, nearly 95% of drugs fail between Phase 1 and approval, primarily due to lack of efficacy in human populations [60]. This translational gap often stems from reliance on genetically identical cell lines or animal models that inadequately capture human biological diversity and physiological complexity [60].
AI approaches that leverage high-dimensional, functional data from primary human cells show promise in bridging this translational gap. Convolutional neural networks and vision transformers can extract high-dimensional features from images of cell-based functional assays, transforming them into quantitative representations (image embeddings) that capture complex biological responses [60]. When applied to primary human cells, these approaches enable measurement of human-relevant responses to therapeutic interventions during preclinical development.
Multi-Modal Data Integration for Enhanced Prediction
The integration of diverse data types provides a more comprehensive foundation for predicting human responses:
- High-Content Imaging: Quantitative analysis of cellular morphology, subcellular localization, and phenotypic responses in primary human cells [60]
- Protein-Protein Interaction Networks: Mapping of signaling pathway alterations in response to candidate compounds [60]
- 3D Culture Systems: Implementation of organoid or organ-on-a-chip technologies for physiological context [60]
- Multi-Omics Integration: Combining functional data with genomics, transcriptomics, and proteomics from human clinical trials [60]
This multi-modal approach enables the definition of physiological states during preclinical development that are directly translatable to human conditions encountered in clinical trials, facilitating improved target validation and candidate selection [60].
The Scientist's Toolkit: Essential Research Reagents and Platforms
Table 5: Key Research Reagent Solutions for AI-Driven Therapeutic Validation
| Reagent/Platform | Function | Application Context |
|---|---|---|
| iBioFAB Automated Platform | End-to-end automation of biological workflows | Protein engineering, pathway optimization, variant characterization [11] |
| Cell-Free Expression Systems | In vitro transcription/translation without living cells | High-throughput protein synthesis, toxic protein production [2] |
| ESM-2 Protein Language Model | Transformer model trained on global protein sequences | Variant fitness prediction, zero-shot mutation design [11] |
| EVmutation Epistasis Model | Statistical model of co-evolutionary patterns | Identification of functionally constrained residues [11] |
| AutoDock Vina | Molecular docking software | Binding pose prediction, virtual screening [61] |
| High-Throughput Screening Assays | Microtiter plate-based functional assays | Enzymatic activity profiling, compound screening [11] |
| Primary Human Cell Systems | Genetically diverse human cell sources | Physiologically relevant toxicity and efficacy testing [60] |
| Droplet Microfluidics | Picoliter-scale reaction compartments | Ultra-high-throughput screening (>100,000 reactions) [2] |
The integration of AI into therapeutic development, particularly through closed-loop DBTL platforms, has demonstrated significant acceleration of preclinical timelines and improvement in early-stage safety profiles. However, the field continues to face challenges in translating these advances to enhanced clinical efficacy rates. Successful clinical-stage validation of AI-designed candidates will require continued refinement of human-relevant validation systems, establishment of transparent industry benchmarks, and thoughtful integration of AI as a tool that enhances rather than replaces scientific reasoning [58] [60]. As these platforms evolve, the reordering of the traditional DBTL cycle to LDBT—where learning precedes design—may ultimately transform therapeutic development into a more predictive engineering discipline, potentially achieving the long-sought goal of first-principles drug design [2].
The application of artificial intelligence (AI) in drug discovery has evolved from an experimental concept to a core component of modern pharmaceutical research and development. AI-driven platforms are now instrumental in accelerating the identification of novel targets, the design of optimized drug candidates, and the prediction of clinical outcomes. These systems leverage machine learning, generative models, and sophisticated data analytics to create more efficient, cost-effective discovery pipelines compared to traditional methods. This analysis focuses on three leading companies—Exscientia, Insilico Medicine, and Recursion Pharmaceuticals—that have developed distinct technological approaches to AI-driven drug discovery. Each platform embodies a unique interpretation of the Design-Build-Test-Learn (DBTL) cycle, a foundational framework for iterative optimization in biological engineering. Their platforms demonstrate how closed-loop AI systems can integrate data from diverse biological and chemical sources to generate novel therapeutic hypotheses and accelerate candidates toward clinical validation. The following sections provide a detailed comparative analysis of their platform architectures, technical capabilities, experimental protocols, and therapeutic outputs, with specific emphasis on their implementation of DBTL cycles for drug discovery applications.
Platform Architectures & Comparative Analysis
Company Platforms and Technical Approaches
The three companies have developed distinct technological architectures that reflect their unique approaches to AI-driven drug discovery:
Insilico Medicine employs Pharma.AI, a comprehensive, end-to-end platform that utilizes generative AI and deep learning across the entire drug discovery value chain. Its modular architecture includes Biology42 for target identification from multi-omics data, Chemistry42 for novel molecular generation, and Medicine42 for clinical outcome prediction and optimization. The platform specifically leverages Large Language of Life Models (LLLMs) trained on biological and chemical data to generate novel molecular structures with desired properties [63] [64] [65].
Recursion Pharmaceuticals operates the Recursion Operating System (Recursion OS), a platform centered on high-content cellular phenotyping and computer vision. The system employs automated, high-throughput microscopy to capture detailed morphological changes in diseased versus treated cells, generating massive-scale biological datasets. Sophisticated machine learning algorithms then distil these phenotypic profiles into trillions of searchable relationships across biology and chemistry, enabling target-agnostic drug discovery [66] [67].
Exscientia utilizes a "Centaur Chemist" approach that strategically combines AI algorithms with human medicinal chemistry expertise. Its platform specializes in generative design for small-molecule optimization, leveraging AI to propose candidate compounds that satisfy multiple design constraints simultaneously. The system integrates diverse data sources including chemical structures, bioassay results, and literature knowledge to inform its design decisions [68].
Table 1: Comparative Analysis of AI Drug Discovery Platform Architectures
| Feature | Insilico Medicine | Recursion Pharmaceuticals | Exscientia |
|---|---|---|---|
| Core Platform | Pharma.AI | Recursion OS | Centaur Chemist AI |
| Primary Approach | Generative AI & Deep Learning | Phenotypic Screening & Computer Vision | Generative Chemistry & Human-AI Collaboration |
| Key Modules | Biology42, Chemistry42, Medicine42, Science42 | Phenomics, BioHive-2 Supercomputer, Digital Chemistry | Design Studio, Centaur Chemist, Patient Al |
| Data Foundation | Multi-omics, chemical databases, clinical data | Cellular imaging, CRISPR screens, chemical libraries | Chemical structures, bioassay data, literature knowledge |
| Automation Level | High automation with robotic labs | Extremely high (millions of experiments weekly) | Moderate, with human expert integration |
| DBTL Implementation | Fully automated generative cycle | Data-rich phenomic cycle | Human-in-the-loop optimization cycle |
Quantitative Performance Metrics
The efficiency gains achieved by these AI platforms are substantiated by quantitative metrics that demonstrate accelerated timelines and reduced resource requirements compared to traditional drug discovery approaches:
Insilico Medicine has demonstrated exceptional efficiency, nominating 22 preclinical candidates from 2021-2024 at an average pace of just 12 to 18 months per program [64]. This represents a significant acceleration compared to the traditional early-stage drug discovery timeline of 2.5 to 4 years [64]. The platform achieved this while synthesizing and testing only 60 to 200 molecules per program, far fewer than conventional medicinal chemistry campaigns typically require [64]. The company's lead program, TNIK inhibitor Rentosertib (ISM001-055), advanced from target discovery to clinical stage in approximately 18 months [65].
Exscientia has similarly demonstrated accelerated timelines, with its platform capable of advancing drug candidate molecules from target identification to clinical trials in approximately 18 months, compared to five years typically required through traditional methods [68]. This acceleration was exemplified by DSP-1181, which in 2020 became the first AI-designed drug to enter clinical trials [68].
Recursion Pharmaceuticals leverages its exceptional experimental scale, conducting up to millions of wet lab experiments weekly [67] supported by BioHive-2, one of the most powerful supercomputers in the world dedicated to life sciences research [68]. This massive scale enables the generation of one of the world's largest proprietary biological and chemical datasets, which in turn powers their AI-driven discovery efforts.
Table 2: Quantitative Performance Metrics and Clinical Pipeline Comparison
| Metric | Insilico Medicine | Recursion Pharmaceuticals | Exscientia |
|---|---|---|---|
| Discovery Timeline | 12-18 months per program [64] | Not explicitly quantified | ~18 months to clinical trials [68] |
| Molecules Tested | 60-200 per program [64] | Large-scale screening (trillions of relationships) [67] | Reduced compared to traditional approaches |
| Clinical Pipeline | 5+ programs in clinical stages [63] [64] | 6 active development projects [69] | 8 compounds in clinical stages (2023) [68] |
| Notable Programs | Rentosertib (TNIK), ISM5411 (PHD1/2), USP1 inhibitor [63] [64] | REC-617 (CDK7), REC-4881 (MEK1/2), REC-7735 (PI3Kα) [67] | CDK7 inhibitor, LSD1 inhibitor, DSP-1181 (OCD) [68] |
| Business Model | Internal pipeline + SaaS platform licensing | Internal pipeline + strategic partnerships | Internal pipeline + partnerships + merged with Recursion |
Experimental Protocols & Workflows
Protocol 1: Generative AI-Driven Target Identification and Compound Design (Insilico Medicine)
This protocol outlines the methodology for AI-driven target discovery and molecule generation, as implemented in Insilico Medicine's Pharma.AI platform for programs such as their TNIK inhibitor Rentosertib [68] [64].
Purpose: To identify novel therapeutic targets and generate optimized small molecule inhibitors using generative AI and multi-parameter optimization.
Workflow Overview:
- Target Identification via Biology42: Process multi-omics data (genomics, transcriptomics, proteomics) using deep learning models to identify novel disease-associated targets. For fibrosis, the platform identified TNIK (Traf2- and Nck-interacting kinase) as a key regulator [68].
- Generative Molecular Design via Chemistry42: Employ generative adversarial networks (GANs) and reinforcement learning to design novel molecular structures targeting TNIK. The system generates structures with desired properties including target affinity, selectivity, and drug-like characteristics.
- In Silico Screening & Optimization: Screen generated compounds through virtual assays predicting binding affinity, pharmacokinetics, and toxicity. Iteratively refine structures using multi-parameter optimization.
- Synthesis & Experimental Validation: Synthesize top-ranking compounds (typically 60-200 molecules) and validate through biochemical and cellular assays [64].
Key Research Reagent Solutions:
- Multi-omics Datasets: Comprehensive genomic, transcriptomic, and proteomic data for target identification; function: provides training data for target discovery models.
- Generative Chemistry Algorithms: AI models trained on chemical compound databases; function: generates novel molecular structures with optimized properties.
- High-Performance Computing Infrastructure: Specialized computing resources for model training and molecular dynamics simulations; function: enables complex AI model execution and virtual screening.
- Automated Synthesis & Screening Platforms: Robotic laboratories for compound synthesis and testing; function: accelerates experimental validation of AI-generated candidates.
Protocol 2: Phenotypic Screening & Target Deconvolution (Recursion Pharmaceuticals)
This protocol details Recursion's approach to phenotypic drug discovery, which leverages high-content cellular imaging and machine learning to identify therapeutic compounds without predetermined molecular targets.
Purpose: To discover novel therapeutic compounds and their mechanisms of action through high-throughput phenotypic screening and AI-driven pattern recognition.
Workflow Overview:
- Cellular Model Engineering: Generate disease-relevant cellular models using CRISPR, small molecules, or other perturbations to recapitulate disease states.
- High-Content Imaging: Expose cellular models to extensive compound libraries (small molecules, biologics) in automated, high-throughput format. Capture detailed morphological data via high-resolution, automated microscopy.
- Computer Vision Feature Extraction: Process cellular images using convolutional neural networks (CNNs) to extract quantitative morphological features ("phenotypic fingerprints").
- Phenomic Map Construction: Embed phenotypic profiles in multidimensional space to identify compounds that normalize disease phenotypes toward healthy states.
- Target Inference & Mechanism Prediction: Leverage the Recursion Data Universe - trillions of biological and chemical relationships - to infer potential mechanisms of action for hit compounds through pattern matching against genetic and chemical perturbation data [66] [67].
Key Research Reagent Solutions:
- Phenotypic Cellular Models: Disease-relevant cell lines and primary cells; function: provides biological context for compound screening.
- High-Content Imaging Systems: Automated microscopy platforms with high-throughput capability; function: captures detailed morphological data at scale.
- BioHive-2 Supercomputer: Dedicated high-performance computing infrastructure; function: processes massive phenotypic datasets and runs complex AI models.
- Recursion Data Universe: Curated database of biological and chemical relationships; function: enables target inference and mechanism prediction.
Protocol 3: AI-Driven Lead Optimization (Exscientia)
This protocol describes Exscientia's approach to compound optimization using AI-driven design cycles, exemplifying their "Centaur Chemist" strategy that combines computational efficiency with human expertise.
Purpose: To rapidly optimize lead compounds through iterative AI-generated design cycles with integrated human feedback and experimental validation.
Workflow Overview:
- Compound Profiling: Characterize starting compounds through in vitro assays for potency, selectivity, and ADMET (absorption, distribution, metabolism, excretion, toxicity) properties.
- AI-Generated Design Hypotheses: Utilize generative AI models to propose structural modifications that improve multiple compound properties simultaneously while maintaining core activity.
- Human Expert Review: Medicinal chemistry experts review AI-proposed compounds based on synthetic feasibility, patentability, and additional knowledge not captured in AI models.
- Compound Synthesis & Testing: Synthesize selected compounds and profile in relevant biological assays.
- Model Retraining & Iteration: Incorporate experimental results back into AI models to improve predictive accuracy and inform next design cycle [68].
Key Research Reagent Solutions:
- Automated Compound Synthesis Platforms: High-throughput chemistry systems; function: enables rapid synthesis of AI-designed compounds.
- Multi-Parameter Optimization Algorithms: AI models trained on chemical and biological data; function: balances multiple drug properties during compound design.
- Integrated Assay Platforms: Standardized biological screening systems; function: provides consistent data for model training and compound evaluation.
Platform-Specific Therapeutic Programs
Insilico Medicine's Therapeutic Pipeline
Insilico Medicine has advanced a diverse therapeutic portfolio spanning multiple disease areas, with several programs reaching clinical validation:
Rentosertib (ISM001-055): A small molecule inhibitor targeting TNIK for idiopathic pulmonary fibrosis (IPF). This program represents the first AI-discovered novel-mechanism anti-fibrotic candidate to complete Phase 2a proof-of-concept trials, demonstrating promising efficacy trends and a favorable safety profile [64]. The program advanced from target discovery to clinical stage in approximately 18 months [65].
Cardiometabolic Portfolio: Recently unveiled a portfolio of eight oral small molecules targeting established cardiometabolic targets including GLP-1R, GIPR, Amylin, APJ, and Lp(a), as well as moderate-novelty targets such as NLRP3 and NR3C1 [64]. The portfolio includes two oral GLP-1 receptor agonists (GLP-1RAs) designed for improved safety and pharmacokinetics at low dose to enable multi-pill combinations. One candidate is engineered for once-weekly dosing [64].
Oncology Pipeline: Multiple programs targeting various cancer mechanisms, including USP1 inhibitor ISM3091 for BRCA-mutant cancer (currently in clinical trials), QPCTL inhibitor for cancer immunotherapy, and MAT2A inhibitor for MTAP-deficient cancer [63].
Recursion Pharmaceuticals' Therapeutic Pipeline
Following its merger with Exscientia and subsequent pipeline optimization, Recursion has focused its therapeutic efforts on oncology and rare diseases:
REC-617: A precision-designed oral CDK7 inhibitor currently in Phase 1/2 trials (ELUCIDATE study) for advanced solid tumors. The monotherapy dose-escalation study established the maximum tolerated dose at 10 mg once-daily, demonstrating a manageable safety profile and preliminary anti-tumor activity. As of September 2025, 29 heavily pre-treated patients with advanced solid tumors had received REC-617 across six dose levels, with one confirmed partial response and five cases of stable disease [67].
REC-7735: A precision-designed PI3Kα H1047R inhibitor generated using the Recursion OS, currently in IND-enabling studies. In preclinical studies, REC-7735 demonstrated significant tumor regressions at low doses, outperforming approved agents while maintaining high selectivity (>100-fold) over wild-type PIK3CA to reduce the risk of dose-limiting hyperglycemia [67].
REC-4881: A MEK1/2 inhibitor in Phase 2 TUPELO study for familial adenomatous polyposis (FAP), with additional data expected in December 2025 [67].
Exscientia's Therapeutic Pipeline
Exscientia has advanced multiple compounds into clinical development, with a strategic focus following its merger with Recursion:
GTAEXS-617: A CDK7 inhibitor and one of Exscientia's lead programs prior to the Recursion merger, representing the company's precision medicine approach to oncology [68].
EXS-74539: An LSD1 inhibitor developed for specific oncology indications, demonstrating the platform's capability to design targeted epigenetic therapies [68].
DSP-1181: Developed in partnership with Sumitomo Dainippon Pharma, this compound for obsessive-compulsive disorder (OCD) was the first AI-designed drug to enter clinical trials in 2020, marking a significant milestone for the field of AI-driven drug discovery [68].
Table 3: Representative Therapeutic Programs and Development Stages
| Company | Program | Target | Indication | Development Stage |
|---|---|---|---|---|
| Insilico Medicine | Rentosertib (ISM001-055) | TNIK | Idiopathic Pulmonary Fibrosis | Phase IIa completed [64] |
| Insilico Medicine | ISM5411 | PHD1/2 | Inflammatory Bowel Disease | Phase I completed [64] |
| Insilico Medicine | ISM3091 | USP1 | BRCA-mutant cancer | Clinical trials [63] |
| Recursion Pharmaceuticals | REC-617 | CDK7 | Advanced Solid Tumors | Phase 1/2 [67] |
| Recursion Pharmaceuticals | REC-7735 | PI3Kα H1047R | Breast Cancer | IND-enabling [67] |
| Recursion Pharmaceuticals | REC-4881 | MEK1/2 | Familial Adenomatous Polyposis | Phase 2 [67] |
| Exscientia | GTAEXS-617 | CDK7 | Oncology | Clinical stage [68] |
| Exscientia | EXS-74539 | LSD1 | Oncology | Clinical stage [68] |
DBTL Implementation & Pathway Analysis
Comparative DBTL Framework Analysis
Each company has implemented the Design-Build-Test-Learn (DBTL) cycle with distinct emphases and technological approaches:
Insilico Medicine's Generative DBTL Cycle: Implements a highly automated, generative approach to DBTL:
- Design: AI-generated novel targets and molecular structures using generative models [63] [64].
- Build: Automated synthesis of limited compound sets (60-200 molecules) [64].
- Test: High-throughput in vitro and in vivo validation of AI-predicted properties.
- Learn: Continuous model refinement using experimental results to improve subsequent design cycles.
Recursion's Phenotype-First DBTL Cycle: Employs a data-centric, phenotype-driven approach:
- Design: Hypothesis-agnostic screening of compound libraries against disease-relevant cellular models.
- Build: Generation of massive-scale phenotypic data through high-content imaging.
- Test: Quantitative analysis of phenotypic changes using computer vision and machine learning.
- Learn: Pattern recognition and target inference through comparison with genetic and chemical perturbation data [66] [67].
Exscientia's Human-AI Collaborative DBTL Cycle: Implements a hybrid approach combining AI efficiency with human expertise:
- Design: AI-generated compound designs with human expert review and refinement.
- Build: Synthesis of selected compounds based on both AI recommendations and medicinal chemistry intuition.
- Test: Standardized biological profiling of synthesized compounds.
- Learn: Integration of experimental results into AI models with human interpretation of discrepancies [68].
Signaling Pathway Workflows
The following diagram illustrates a representative signaling pathway targeted by Insilico Medicine's cardiometabolic portfolio, demonstrating the complex biological networks that AI platforms must model and interrogate:
The comparative analysis of Exscientia, Insilico Medicine, and Recursion Pharmaceuticals reveals distinct implementations of AI-driven drug discovery platforms, each with unique strengths and specialized applications. Insilico Medicine's generative AI approach demonstrates exceptional efficiency in novel target identification and molecular generation, with validated acceleration of discovery timelines. Recursion's phenotypic screening platform offers a powerful target-agnostic discovery engine capable of identifying novel mechanisms through pattern recognition in high-dimensional data. Exscientia's human-AI collaborative model balances computational efficiency with medicinal chemistry expertise, particularly strong in lead optimization phases.
The recent merger between Recursion and Exscientia creates an interesting convergence of phenotypic screening and generative chemistry capabilities, potentially establishing a comprehensive platform that spans multiple discovery approaches. All three platforms have demonstrated clinical-stage validation, with compounds advancing through human trials, providing preliminary evidence that AI-driven discovery can generate viable therapeutic candidates.
As these platforms continue to evolve, key challenges remain around clinical success rates, regulatory acceptance of AI-derived insights, and the integration of increasingly diverse data types. Nevertheless, the documented efficiencies in early discovery and the growing clinical pipelines suggest that AI-driven platforms represent a fundamental shift in therapeutic development methodology that will likely play an increasingly central role in pharmaceutical R&D.
The integration of artificial intelligence (AI) and closed-loop Design-Build-Test-Learn (DBTL) platforms is fundamentally reshaping the landscape of scientific research and drug development. These systems leverage autonomous AI agents to orchestrate complex experimental workflows, dramatically accelerating the pace of discovery [70]. This document provides application notes and experimental protocols for quantifying the transformative impact of these platforms, focusing on key metrics of timeline compression, cost reduction, and increased success rates. The content is framed within a broader thesis on the role of autonomous AI agents in research, providing scientists and drug development professionals with actionable methodologies for implementation and validation.
Quantitative Impact of AI in Research
AI-driven platforms are delivering measurable gains across various stages of the research and development lifecycle. The following tables summarize documented quantitative impacts in key domains.
Table 1: Documented AI Performance in Specific Research Domains
| Domain | AI Tool / System | Documented Impact Metric | Key Finding |
|---|---|---|---|
| Proteomics | AlphaFold 2 & 3 | >200 million protein structure predictions enabled; results in minutes versus years [70]. | Revolutionary acceleration in structural biology, facilitating drug design. |
| Manufacturing | Self-Improving Predictive Maintenance Agents | 30-40% reduction in unplanned downtime compared to traditional approaches [71]. | Continuous adaptation to new data maintains model accuracy and prevents losses. |
| Multi-Agent System (MAS) Development | Agent Communication Protocol (ACP) | ~70% reduction in custom integration code for Multi-Agent Systems (MAS) [72]. | Enhanced interoperability and efficiency in deploying collaborative AI agents. |
Table 2: General Efficiency Gains from Agentic AI Systems
| Aspect of Workflow | Impact of Autonomous AI Agents |
|---|---|
| Operational Scaling | One data scientist can oversee ten self-improving agents monitoring different production lines, each automatically adapting to local conditions [71]. |
| Model Adaptation | Eliminates manual retraining cycles; agents self-detect performance degradation and trigger retraining pipelines autonomously [71]. |
| Data Sovereignty & Compliance | Enables deployment of advanced AI capabilities (e.g., RAG agents accessing patient records) entirely within secure, compliant infrastructure (e.g., for HIPAA) [71]. |
Experimental Protocols for Validating AI Agent Performance
Protocol for Benchmarking Predictive Model Accuracy in a Closed Loop
Objective: To quantify the improvement in prediction accuracy and resultant reduction in experimental cycles achieved by a self-improving AI agent within a DBTL platform.
Materials:
- Historical dataset of experimental designs and their corresponding outcome measures.
- Access to a closed-loop DBTL platform with integrated AI modeling capabilities.
- A defined set of performance metrics (e.g., Mean Absolute Error, R², Area Under the Curve).
Methodology:
- Baseline Establishment: Use the historical dataset to train and validate a baseline static model. Record its predictive accuracy on a held-out test set.
- Agent Deployment: Deploy the self-improving AI agent on the DBTL platform. Configure its drift detection algorithms to monitor prediction accuracy against new experimental results [71].
- Closed-Loop Operation: Initiate new DBTL cycles. For each cycle:
- The AI agent proposes an experimental design.
- The experiment is executed, and results are recorded.
- The agent incorporates the new result into its knowledge base.
- The agent's self-monitoring system evaluates if prediction accuracy has dropped below a pre-set threshold, triggering automated retraining with the updated dataset [71].
- Data Collection & Analysis: Over a minimum of 5 full DBTL cycles, track:
- The predictive accuracy of the AI model before and after each retraining event.
- The number of cycles required to achieve a pre-determined performance target compared to the baseline projection.
Protocol for Quantifying Timeline Compression in a Multi-Agent Workflow
Objective: To measure the reduction in process completion time achieved by a collaborative multi-agent system compared to a sequential, human-led workflow.
Materials:
- A defined multi-step process (e.g., experimental data analysis, literature review, and report drafting).
- A configured multi-agent system with specialized agents (e.g., data retrieval, statistical analysis, natural language explanation) coordinated via an orchestration layer or communication protocol like ACP [72].
Methodology:
- Time-in-Motion Baseline: Document the mean completion time for the entire process using established, human-executed sequential workflows.
- Agent Orchestration: Model the process as a parallelizable workflow and implement it using collaborative agents. Ensure agents can communicate, share context, and coordinate via a defined protocol [71] [72].
- Parallel Execution: Execute the process using the multi-agent system. The orchestration layer manages task routing and result synthesis among the specialized agents [71].
- Metric Comparison: Record the total time from process initiation to final output delivery. Compare this against the established baseline to calculate the percentage reduction in timeline.
Workflow Visualization of an AI-Driven DBTL Platform
The following diagram, generated using Graphviz, illustrates the logical workflow and signaling pathways of a closed-loop DBTL platform powered by self-improving AI agents.
Diagram 1: Closed-Loop DBTL with Self-Improving AI Agent
This diagram illustrates the autonomous cycle where an AI agent designs experiments, learns from results, and self-improves its predictive models. The dashed and dotted lines represent the critical signaling pathways for continuous learning and model adaptation that enable timeline compression and cost reduction [71].
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential AI and Data Tools for DBTL Platforms
| Tool / Reagent | Function / Explanation |
|---|---|
| AlphaFold Server | A free online platform that predicts protein structures and their interactions with other biomolecules in minutes, revolutionizing target identification and structural biology [70]. |
| RAG (Retrieval-Augmented Generation) Agent | An AI agent that combines a language model with real-time access to proprietary knowledge bases (e.g., internal research reports, EHRs), ensuring outputs are based on current, organization-specific information while maintaining data sovereignty [71]. |
| Agent Communication Protocol (ACP) | A standardized "language" (e.g., based on HTTP/REST and JSON) that enables disparate AI agents from different frameworks to discover each other, communicate, and collaborate on complex tasks, reducing integration overhead [72]. |
| Automated ML (AutoML) Pipelines | Integrated components for model training, validation, and deployment that can be triggered automatically by self-improving agents upon detection of performance degradation or data drift [71]. |
| Vector Database | A specialized database (e.g., Weaviate, Milvus) that stores data as numerical vectors, enabling semantic search across vast document sets and research papers for RAG agents [71]. |
The drug discovery landscape is undergoing a profound transformation, shifting from traditional labor-intensive, human-driven workflows to AI-powered discovery engines capable of compressing timelines and expanding chemical and biological search spaces [8]. Central to this transformation is the Design-Build-Test-Learn (DBTL) cycle, a systematic, iterative framework for engineering biological systems [2]. Recent technological advances are pushing this paradigm further toward autonomous operation, where "Learning" can precede "Design" in an LDBT (Learn-Design-Build-Test) sequence, potentially creating a single-cycle process that generates functional parts and circuits [2]. This evolution is enabled by the integration of machine learning (ML), large language models (LLMs), and biofoundry automation, creating closed-loop systems that minimize human intervention [11].
This application note examines three emerging players—Generate:Biomedicines, Absci, and Terray Therapeutics—who are pioneering these advanced DBTL platforms. We focus specifically on their technological architectures, quantitative performance metrics, and detailed experimental protocols that enable autonomous drug discovery. It is important to note that while our analysis covers the mandated three companies, current search results did not contain specific technical details for Generate:Biomedicines' platform. Therefore, this document provides comprehensive coverage of Absci and Terray Therapeutics, with the understanding that Generate:Biomedicines represents another significant contributor to this field.
Technology Platform Comparisons
Quantitative Platform Metrics
Table 1: Comparative Performance Metrics of AI-Driven Drug Discovery Platforms
| Metric | Absci | Terray Therapeutics | Traditional Discovery |
|---|---|---|---|
| Data Generation Scale | Iterative wet-lab validation cycles every 6 weeks [73] | >2 billion unique target-ligand measurements; grows by 1 billion/quarter [74] | Limited by manual processes |
| Design Cycle Time | Accelerated via OCI/AMD infrastructure (2.5 µs inter-GPU latency) [75] | Closed-loop iteration of <1 month per target [74] | Months to years |
| Compound Synthesis Efficiency | Not specified | Several million molecules per month [76] | Hundreds to thousands per month |
| Lead Optimization Efficiency | Zero-shot AI de novo design of functional antibodies [77] | AI-generated small molecules with wet-lab follow-up [76] | Requires thousands of compounds |
| Clinical Advancement | ABS-101 Phase 1 readout 2025; ABS-201 Phase 1/2a 2026 [77] | First compound targeted for clinic by 2026 [76] | ~5 years to clinical stages |
Platform Architectures and Workflows
Table 2: Core Technology Architectures
| Company | Therapeutic Focus | Core Technology | AI/ML Integration |
|---|---|---|---|
| Absci | Biologics, Antibodies [73] | Integrated Drug Creation Platform: Generative AI + Synthetic Biology Data Engine [75] | Zero-shot de novo AI design; Molecular dynamics simulations [75] [77] |
| Terray Therapeutics | Small Molecules, Immunology [74] [76] | tNova Platform: Ultra-dense microarray technology + computational platform [78] | Latent diffusion models for molecule generation; Chemical space mapping algorithms [76] |
The following diagram illustrates Absci's core workflow, which exemplifies a tight closed-loop DBTL system for biologics design:
Diagram 1: Absci's integrated drug creation cycle. The platform utilizes OCI bare metal instances and AMD GPUs to achieve high-speed inter-GPU latency (2.5 µs), enabling rapid molecular dynamics simulations and closing the loop between computational design and wet lab validation in approximately six weeks [75] [73] [77].
In contrast, Terray Therapeutics employs a massively parallel approach to small molecule discovery:
Diagram 2: Terray's small molecule discovery loop. The platform leverages the world's most dense and precise microarray to generate over 2 billion unique target-ligand binding measurements, growing by 1 billion each quarter. This data trains AI models that generate novel small molecules, with the entire design-make-test-analyze cycle taking less than one month per target [74] [78] [76].
Experimental Protocols and Methodologies
Absci's De Novo Antibody Design Protocol
Protocol Title: Zero-shot AI-Driven Antibody Design and Validation Using Integrated Computational-Biological Workflow
Background: This protocol enables the de novo design of functional antibodies against difficult-to-drug targets without initial structural data, leveraging Absci's generative AI platform and high-performance computing infrastructure.
Materials and Equipment:
- Table 3: Research Reagent Solutions for Absci's Platform
| Reagent/Equipment | Function/Application | Specifications |
|---|---|---|
| Oracle Cloud Infrastructure | AI model training and molecular dynamics simulations | Bare metal instances with 5th Gen AMD EPYC processors [75] |
| AMD Instinct MI355X GPUs | Accelerate generative AI and simulation workloads | Ultrafast RDMA networking (2.5 µs inter-GPU latency) [75] |
| ROCm Software Platform | Open software platform for GPU computing | Enables AMD GPU utilization for AI workloads [75] |
| Synthetic Biology Data Engine | Wet-lab validation of AI-designed biologics | Continuous feedback loop between AI and experimental validation [73] |
| Reverse Immunology Platform | AI-enabled novel target discovery | Identifies antibody/target pairs from super immune responders [77] |
Procedure:
Target Identification and Characterization
AI Model Training and Initial Design
- Leverage OCI bare metal instances with AMD EPYC processors and Instinct MI355X GPUs for large-scale model training [75]
- Perform molecular dynamics simulations to refine antibody-antigen interactions using high-resolution models [75]
- Execute zero-shot generative AI designs that propose novel antibody sequences satisfying target product profiles [77]
In Silico Optimization and Selection
- Apply multi-parametric optimization for affinity, specificity, immunogenicity, and developability [73]
- Utilize terabytes-per-second throughput for checkpointing and data streaming during optimization cycles [75]
- Select lead candidates based on computational predictions of binding affinity and structural stability
Wet Lab Validation and Iteration
- Express and purify selected AI-designed antibody candidates using high-throughput methods
- Characterize binding affinity (KD), potency (IC50/EC_50), and specificity through in vitro assays
- Assess developability properties (aggregation, viscosity, stability) to identify potential clinical candidates
- Feed experimental results back into AI training cycle to refine subsequent design iterations [73]
Timeline: The complete design-build-test-learn cycle is completed within approximately 6 weeks per iteration [73].
Troubleshooting:
- For poor expression yields: Revisit AI design parameters to optimize sequence features affecting protein folding and stability
- For inadequate binding affinity: Increase diversity of initial design library and incorporate additional structural constraints in generative models
Terray Therapeutics' Small Molecule Optimization Protocol
Protocol Title: High-Throughput Small Molecule Screening and Optimization Using Ultra-Dense Microarray Technology
Background: This protocol describes Terray's approach to generating massive-scale, high-quality chemical data using microarray technology, which enables precise mapping of biochemical interactions between small molecules and disease targets for AI-driven small molecule discovery.
Materials and Equipment:
- Table 4: Research Reagent Solutions for Terray's Platform
| Reagent/Equipment | Function/Application | Specifications |
|---|---|---|
| Ultra-dense Microarray | High-throughput binding measurements | Billions of unique target-ligand interactions measured daily [78] |
| tNova Computational Platform | Integrated ML and data analysis | Processes massive-scale interaction data [78] |
| Latent Diffusion Models | Novel small molecule generation | AI generates new molecular structures based on learned patterns [76] |
| Chemical Space Mapping Algorithm | Models drug-like chemical space | Algorithm published in J. Chem. Inf. Model. (2024) [76] |
Procedure:
Microarray Fabrication and Preparation
- Synthesize diverse small molecule libraries covering extensive chemical space
- Print molecules onto ultra-dense microarrays at nanoscale resolution
- Quality control array uniformity and molecule integrity before screening
High-Throughput Binding Assays
Data Processing and AI Model Training
- Process raw binding data to generate quantitative interaction measurements
- Train machine learning models on the interaction dataset to predict molecular properties and binding affinities [74]
- Apply latent diffusion models and chemical space mapping algorithms to generate novel small molecule designs [76]
Hit Validation and Lead Optimization
- Resynthesize and confirm activity of AI-predicted hit compounds
- Perform iterative structure-activity relationship (SAR) studies using the continuous feedback loop
- Advance optimized leads through preclinical development toward clinical candidate selection
Timeline: The complete design-make-test-analyze cycle requires less than one month per target [74].
Troubleshooting:
- For low signal-to-noise in binding assays: Optimize incubation conditions and detection parameters
- For poor correlation between predicted and measured activity: Expand training dataset diversity and refine AI model architecture
The LDBT Paradigm: From DBTL to Learn-Design-Build-Test
The most significant evolution in closed-loop drug discovery is the shift from traditional Design-Build-Test-Learn (DBTL) cycles to a Learn-Design-Build-Test (LDBT) paradigm, where machine learning precedes and informs the design phase [2]. This transformation is made possible by foundational models trained on massive biological datasets that can make increasingly accurate zero-shot predictions.
Diagram 3: The paradigm shift from DBTL to LDBT. In the LDBT framework, learning precedes design through protein language models (e.g., ESM-2) and evolutionary data, enabling zero-shot predictions that can generate functional parts in a single cycle, moving synthetic biology closer to a Design-Build-Work model [2] [11].
The implementation of LDBT requires specific AI architectures and data resources:
- Protein Language Models: Models like ESM-2 trained on global protein sequences capture evolutionary relationships and can predict beneficial mutations and infer protein function in zero-shot settings [2]
- Structure-Based Design Tools: Systems like ProteinMPNN take entire protein structures as input and predict sequences that fold into specified backbones, achieving nearly 10-fold increases in design success rates when combined with structure assessment tools like AlphaFold [2]
- Hybrid Approaches: Physics-informed machine learning combines the predictive power of statistical models with the explanatory strength of physical principles for enhanced engineering outcomes [2]
Absci and Terray Therapeutics exemplify the cutting edge of closed-loop DBTL platforms in drug discovery, though they operate in complementary therapeutic modalities. Absci's platform, powered by high-performance computing infrastructure from Oracle and AMD, demonstrates the capability for zero-shot de novo design of antibodies, with multiple programs advancing toward clinical trials [75] [77]. Terray Therapeutics leverages unprecedented scale in data generation—with billions of quantitative binding measurements—to fuel AI models that navigate small molecule chemical space with exceptional efficiency [74] [78].
The emergence of the LDBT paradigm, where learning precedes design through foundational AI models, represents the next evolutionary stage in autonomous drug discovery [2]. As these platforms mature and integrate increasingly sophisticated AI agents with automated experimental systems, they promise to further compress discovery timelines, reduce costs, and ultimately increase the success rates of therapeutic development. The true validation of these approaches will come as more AI-designed drugs advance through clinical trials and demonstrate improved outcomes compared to conventionally discovered medicines.
Conclusion
The integration of AI agents into closed-loop DBTL platforms marks a definitive paradigm shift in drug discovery, moving the industry from empirical, sequential workflows to autonomous, data-driven engines. Evidence from clinical-stage biotechs demonstrates tangible success in compressing discovery timelines from years to months and significantly improving the efficiency of lead optimization. Key challenges around data integration, model reliability, and human oversight remain active frontiers. The future points toward increasingly sophisticated multi-agent systems capable of end-to-end discovery, deeper integration of patient-derived biological data for enhanced translatability, and the rise of a 'Design-Build-Work' model. For researchers and drug development professionals, mastering these platforms is no longer optional but essential for driving the next wave of therapeutic breakthroughs and achieving a more precise, rapid, and successful drug development pipeline.
References
- 1. The Autonomous Lab: AI Platforms Redefining Enzyme Engineering [https://www.ailurus.bio/post/the-autonomous-lab-ai-platforms-redefining-enzyme-engineering]
- 2. LDBT instead of DBTL: combining machine learning and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12589603/]
- 3. Artificial intelligence in drug discovery and development [https://link.springer.com/article/10.1007/s44395-025-00007-3]
- 4. Artificial Intelligence (AI) Applications in Drug Discovery and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11510778/]
- 5. [2508.14111] From AI for Science to Agentic Science [https://arxiv.org/abs/2508.14111]
- 6. Perspective Empowering biomedical discovery with AI agents [https://www.sciencedirect.com/science/article/pii/S0092867424010705]
- 7. combining machine learning and rapid cell-free testing [https://www.nature.com/articles/s41467-025-65281-2]
- 8. Leading AI-Driven Drug Discovery Platforms [https://www.sciencedirect.com/science/article/abs/pii/S0031699725075118]
- 9. Build Multi-Agent Systems Using the Agents as Tools Pattern [https://dev.to/aws/build-multi-agent-systems-using-the-agents-as-tools-pattern-jce]
- 10. Multi-Agent Architectures [https://docs.swarms.world/en/latest/swarms/concept/swarm_architectures/]
- 11. A generalized platform for artificial intelligence-powered ... [https://www.nature.com/articles/s41467-025-61209-y]
- 12. Zero-Shot Learning Techniques: A Comprehensive Guide [https://www.pingcap.com/article/zero-shot-learning-techniques-a-comprehensive-guide/]
- 13. PatrickZH/A-Large-scale-Attribute-Dataset-for-Zero-shot- ... [https://github.com/PatrickZH/A-Large-scale-Attribute-Dataset-for-Zero-shot-Learning]
- 14. Leveraging artificial intelligence in antibody-drug conjugate ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12638810/]
- 15. MegaScale: Scaling Large Language Model Training to ... [https://arxiv.org/html/2402.15627v1]
- 16. Hit Identification in Drug Discovery [https://www.vipergen.com/hit-identification-in-drug-discovery/]
- 17. a global close-loop feedback powered by autonomous AI ... [https://www.oaepublish.com/articles/aiagent.2025.02]
- 18. Digital to Biological Translation: How the Algorithmic Data ... [https://www.mdpi.com/2674-0583/3/4/17]
- 19. Hit Discovery using Docking ENriched by GEnerative ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11156482/]
- 20. Accelerated hit identification with target evaluation, deep ... [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-024-00914-0]
- 21. De novo drug design through artificial intelligence [https://www.frontiersin.org/journals/hematology/articles/10.3389/frhem.2024.1305741/full]
- 22. Integrating artificial intelligence into small molecule ... [https://www.nature.com/articles/s44386-025-00029-y]
- 23. Atomically accurate de novo design of antibodies with ... [https://www.nature.com/articles/s41586-025-09721-5]
- 24. AI-Driven Protein Design Partnership | IDT [https://www.idtdna.com/pages/about/news/2025/10/21/integrated-dna-technologies-and-profluent-collaborate-to-unlock-new-frontier-of-ai-driven-protein-design]
- 25. Scientists use AI to create antibodies entirely from scratch [https://www.drugtargetreview.com/news/190363/scientists-use-ai-to-create-antibodies-entirely-from-scratch/]
- 26. AI, agentic models and lab automation for scientific discovery [https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1649155/full]
- 27. High-Throughput Screening Meets AI and 3D Models [https://www.technologynetworks.com/drug-discovery/articles/how-high-throughput-screening-is-transforming-modern-drug-discovery-405922]
- 28. HTS Robotics Platform - The Wertheim UF Scripps Institute [https://hts.scripps.ufl.edu/facilities/hts-robotics/]
- 29. Lab Automation for High Throughput Clone Screening [https://www.moleculardevices.com/service-support/lab-automation-solutions/lab-automation-for-high-throughput-clone-screening]
- 30. High-Throughput Experimentation Using Cell-Free Protein ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10228547/]
- 31. Self-driving laboratories to autonomously navigate the ... [https://www.nature.com/articles/s44286-023-00002-4]
- 32. From Models to Scientists: Building AI Agents for Scientific ... [https://kempnerinstitute.harvard.edu/research/deeper-learning/from-models-to-scientists-building-ai-agents-for-scientific-discovery/]
- 33. Leveraging Agentic AI to Accelerate Drug Discovery and ... [https://www.akira.ai/blog/agentic-ai-drug-discovery-development]
- 34. Progress of AI-Driven Drug–Target Interaction Prediction and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12563295/]
- 35. AI agents in drug discovery [https://www.politico.com/newsletters/future-pulse/2025/10/14/ai-agents-in-drug-discovery-00607875]
- 36. Artificial intelligence in drug discovery and development - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC7577280/]
- 37. Reframing the IND: From Tactical Requirement to Strategic ... [https://www.appliedclinicaltrialsonline.com/view/reframing-the-ind-from-tactical-requirement-to-strategic-opportunity]
- 38. From Lab to Clinic: How Artificial Intelligence (AI) Is ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12298131/]
- 39. 2025 AI in Drug Discovery: Predictions [https://lizard.bio/knowledge-hub/2025-ai-in-drug-discovery-predictions]
- 40. An adversarial training framework for mitigating algorithmic ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10050816/]
- 41. Algorithmic fairness and bias mitigation for clinical machine ... [https://www.nature.com/articles/s42256-023-00697-3]
- 42. AI & Biosafety | BIT-LLM - iGEM 2025 [https://2025.igem.wiki/bit-llm/ai-biosafety]
- 43. Why Synthetic Data Is Taking Over in 2025: Solving AI's Data ... [https://humansintheloop.org/why-synthetic-data-is-taking-over-in-2025-solving-ais-data-crisis/]
- 44. Regulating the AI-enabled ecosystem for human therapeutics [https://pmc.ncbi.nlm.nih.gov/articles/PMC12085592/]
- 45. Human-in-the-Loop for AI: A Collaborative Future ... [https://blog.metaphacts.com/human-in-the-loop-for-ai-a-collaborative-future-in-research-workflows]
- 46. Methods and Validations for the AutoLit Review Software - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC12552804/]
- 47. Human in the Loop: How AI is Redefining Insights in 2025 [https://www.rivaltech.com/blog/human-in-the-loop-ai]
- 48. What is "Human-in-the-Loop"? [https://www.gmp-compliance.org/gmp-news/what-is-human-in-the-loop]
- 49. Synthetic biology/AI convergence (SynBioAI): security ... [https://link.springer.com/article/10.1007/s00146-025-02576-4]
- 50. Integrating Computational Design and Experimental ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11430650/]
- 51. Integrating Disparate Data Sources: Challenges and ... [https://dualitytech.com/blog/integrating-disparate-data-sources/]
- 52. Pricing the Factory: A Framework for Valuing Biotech ... [https://www.linkedin.com/pulse/pricing-factory-framework-valuing-biotech-platforms-ignacio-mnrif]
- 53. Top 10 R&D Intelligence Platforms for 2025: AI-Powered ... [https://www.linkedin.com/pulse/top-10-rd-intelligence-platforms-2025-ai-powered-innovation-management-nj17e]
- 54. The 2025 Optimizely Opal AI Benchmark Report [https://www.optimizely.com/insights/the-2025-optimizely-opal-ai-benchmark-report/]
- 55. AI Chatbot KPIs: What to Track in 2025 [https://dialzara.com/blog/ai-chatbot-kpis-what-to-track-in-2025]
- 56. Closing the loop: establishing an autonomous test-learn ... [https://www.frontiersin.org/journals/bioengineering-and-biotechnology/articles/10.3389/fbioe.2024.1528224/full]
- 57. AI agent development trends 2025: Tools, industries, and rates [https://greenice.net/ai-agent-development-trends/]
- 58. Progress, Pitfalls, and Impact of AI‐Driven Clinical Trials [https://pmc.ncbi.nlm.nih.gov/articles/PMC11924158/]
- 59. Harnessing Artificial Intelligence in Drug Discovery and ... [https://www.accc-cancer.org/acccbuzz/blog-post-template/accc-buzz/2024/12/20/harnessing-artificial-intelligence-in-drug-discovery-and-development]
- 60. The AI drug revolution needs a revolution [https://www.nature.com/articles/s44386-025-00013-6]
- 61. Molecular docking as a tool for the discovery ... [https://www.nature.com/articles/s41598-023-40160-2]
- 62. Molecular Docking: A powerful approach for structure-based ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3151162/]
- 63. Insilico Medicine: Main [https://insilico.com/]
- 64. BIO Europe 2025 | Pushing the frontiers of generative AI for ... [https://insilico.com/tpost/89a86bpg91-bio-europe-2025-pushing-the-frontiers-of]
- 65. 當AI遇上創新藥物研發:【英矽智能Insilico Medicine】正式遞 ... [https://www.facebook.com/61568446257142/posts/%E7%95%B6ai%E9%81%87%E4%B8%8A%E5%89%B5%E6%96%B0%E8%97%A5%E7%89%A9%E7%A0%94%E7%99%BC%E8%8B%B1%E7%9F%BD%E6%99%BA%E8%83%BDinsilico-medicine%E6%AD%A3%E5%BC%8F%E9%81%9E%E8%A1%A8%E6%B8%AF%E4%BA%A4%E6%89%80%E4%BC%B0%E5%80%BC%E7%A0%B413%E5%84%84%E7%BE%8E%E5%85%83-%E5%BE%9Etnik%E5%B0%8F%E5%88%86%E5%AD%90%E6%8A%91%E5%88%B6%E5%8A%91%E5%88%B0pharmaai%E5%85%A8%E6%96%B9%E4%BD%8D%E4%BD%88%E5%B1%80ai%E8%97%A5%E7%89%A9%E9%96%8B%E7%99%BC%E9%80%B2/122137989890614875/]
- 66. [美股财报]:Recursion Pharmaceuticals Inc-A 2025年季度报告 [https://www.fxbaogao.com/detail/4817952]
- 67. Recursion Reports Third Quarter 2025 Financial Results ... [https://ir.recursion.com/news-releases/news-release-details/recursion-reports-third-quarter-2025-financial-results-and]
- 68. 综述:领先的人工智能驱动药物发现平台:2025年的市场格局 ... [https://www.ebiotrade.com/newsf/2025-11/20251112002210649.htm]
- 69. 几个月后与Exscientia合并,AI生物技术公司Recursion重组 ... [https://www.familydoctor.cn/news/jige-yuehou-recursion-exscientia-hebing-chongzu-yanfa-85355.html]
- 70. Cutting-edge AI tools revolutionizing scientific research in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12089930/]
- 71. 5 Agentic AI Design Patterns Transforming Enterprise ... [https://www.shakudo.io/blog/5-agentic-ai-design-patterns-transforming-enterprise-operations-in-2025]
- 72. The Secret Language of AI: How Agent Communication ... [https://medium.com/@drajput_14416/agent-communication-protocol-forging-the-future-of-interoperable-ai-agents-e64be058b22d]
- 73. Absci: Home [https://www.absci.com/]
- 74. Terray Therapeutics: Everything small molecule drug ... [https://www.terraytx.com/]
- 75. Absci Accelerates AI-Driven Drug Discovery with Oracle and ... [https://investors.absci.com/news-releases/news-release-details/absci-accelerates-ai-driven-drug-discovery-oracle-and-amd]
- 76. Terray Therapeutics aims for the clinic by 2026 - C&EN [https://cen.acs.org/business/finance/Terray-Therapeutics-aims-clinic-2026/102/web/2024/10]
- 77. Absci Reports Business Updates and Second Quarter 2025 ... [https://investors.absci.com/news-releases/news-release-details/absci-reports-business-updates-and-second-quarter-2025-financial]
- 78. Terray Therapeutics Launches with $60M to Deliver ... [https://www.terraytx.com/press/terray-therapeutics-launches-with-60m-to-deliver-premium-chemical-data-at-unrivaled-scale-unlocking-the-potential-of-ai-driven-small-molecule-drug-discovery]